UCB Data100:数据科学的原理和技巧:第十一章到第十二章-程序员宅基地
十一、恒定模型、损失和转换
原文:Constant Model, Loss, and Transformations
译者:飞龙
学习成果
-
推导出在 MSE 和 MAE 成本函数下恒定模型的最佳模型参数。
-
评估 MSE 和 MAE 风险之间的差异。
-
理解变量线性化的必要性,并应用图基-莫斯特勒凸图进行转换。
上次,我们介绍了建模过程。我们建立了一个框架,根据一套工作流程,预测目标变量作为我们特征的函数:
-
选择模型 - 我们应该如何表示世界?
-
选择损失函数 - 我们如何量化预测误差?
-
拟合模型 - 我们如何根据我们的数据选择最佳模型参数?
-
评估模型性能 - 我们如何评估这个过程是否产生了一个好模型?
为了说明这个过程,我们推导了简单线性回归(SLR)下均方误差(MSE)作为成本函数的最佳模型参数。SLR 建模过程的摘要如下所示:
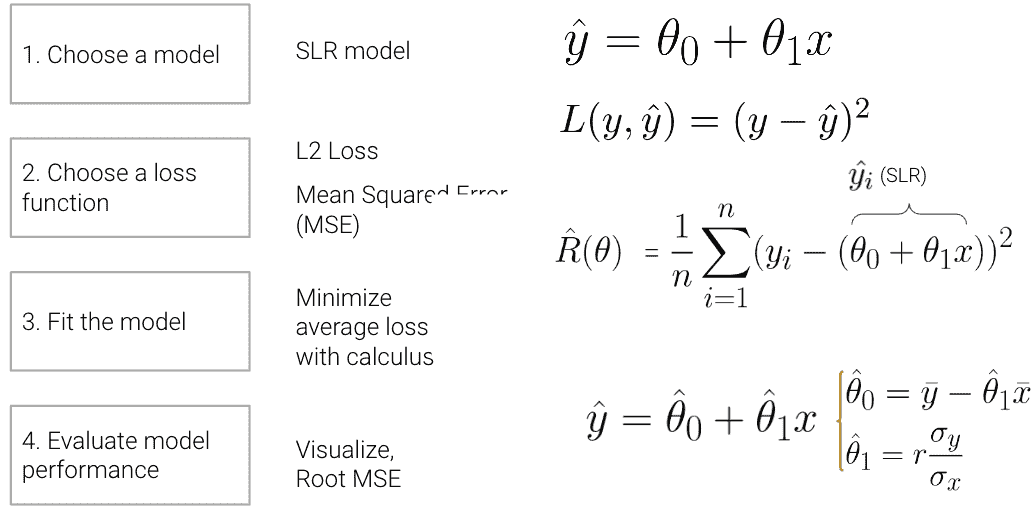
在本讲座中,我们将深入探讨步骤 4 - 评估模型性能 - 以 SLR 为例。此外,我们还将通过新模型探索建模过程,继续通过在新模型下找到最佳模型参数来熟悉建模过程,并测试两种不同的损失函数,以了解我们选择的损失如何影响模型设计。稍后,我们将考虑当线性模型不是捕捉数据趋势的最佳选择时会发生什么,以及有哪些解决方案可以创建更好的模型。
11.1 步骤 4:评估 SLR 模型
现在我们已经探讨了(1)选择模型、(2)选择损失函数和(3)拟合模型背后的数学原理,我们还剩下一个最后的问题 - 这个“最佳”拟合模型的预测有多“好”?为了确定这一点,我们可以:
-
可视化数据并计算统计数据:
-
绘制原始数据。
-
计算每一列的均值和标准差。如果我们的预测的均值和标准差接近于原始观察到的 y i y_i yi,我们可能会倾向于说我们的模型做得不错。
-
(如果我们拟合线性模型)计算相关性 r r r。特征和响应变量之间的相关系数的大幅度也可能表明我们的模型做得不错。
-
-
性能指标:
-
我们可以采用均方根误差(RMSE)。
-
这是均方误差(MSE)的平方根,它是我们一直在最小化以确定最佳模型参数的平均损失。
-
RMSE 与 y y y的单位相同。
-
较低的 RMSE 表示更“准确”的预测,因为我们在数据中有更低的“平均损失”。
-
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
-
-
可视化:
- 查看 e i = y i − y i ^ e_i = y_i - \hat{y_i} ei=yi−yi^的残差图,以可视化实际值和预测值之间的差异。良好的残差图不应显示输入/特征 x i x_i xi和残差值 e i e_i ei之间的任何模式。
为了说明这个过程,让我们看看安斯库姆的四重奏。
11.1.1 四个神秘的数据集(安斯库姆的四重奏)
让我们看看四个不同的数据集。
代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import itertools
from mpl_toolkits.mplot3d import Axes3D
# Big font helper
def adjust_fontsize(size=None):
SMALL_SIZE = 8
MEDIUM_SIZE = 10
BIGGER_SIZE = 12
if size != None:
SMALL_SIZE = MEDIUM_SIZE = BIGGER_SIZE = size
plt.rc('font', size=SMALL_SIZE) # controls default text sizes
plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize
plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title
# Helper functions
def standard_units(x):
return (x - np.mean(x)) / np.std(x)
def correlation(x, y):
return np.mean(standard_units(x) * standard_units(y))
def slope(x, y):
return correlation(x, y) * np.std(y) / np.std(x)
def intercept(x, y):
return np.mean(y) - slope(x, y)*np.mean(x)
def fit_least_squares(x, y):
theta_0 = intercept(x, y)
theta_1 = slope(x, y)
return theta_0, theta_1
def predict(x, theta_0, theta_1):
return theta_0 + theta_1*x
def compute_mse(y, yhat):
return np.mean((y - yhat)**2)
plt.style.use('default') # Revert style to default mpl
plt.style.use('default') # Revert style to default mpl
NO_VIZ, RESID, RESID_SCATTER = range(3)
def least_squares_evaluation(x, y, visualize=NO_VIZ):
# statistics
print(f"x_mean : {
np.mean(x):.2f}, y_mean : {
np.mean(y):.2f}")
print(f"x_stdev: {
np.std(x):.2f}, y_stdev: {
np.std(y):.2f}")
print(f"r = Correlation(x, y): {
correlation(x, y):.3f}")
# Performance metrics
ahat, bhat = fit_least_squares(x, y)
yhat = predict(x, ahat, bhat)
print(f"\theta_0: {
ahat:.2f}, \theta_1: {
bhat:.2f}")
print(f"RMSE: {
np.sqrt(compute_mse(y, yhat)):.3f}")
# visualization
fig, ax_resid = None, None
if visualize == RESID_SCATTER:
fig, axs = plt.subplots(1,2,figsize=(8, 3))
axs[0].scatter(x, y)
axs[0].plot(x, yhat)
axs[0].set_title("LS fit")
ax_resid = axs[1]
elif visualize == RESID:
fig = plt.figure(figsize=(4, 3))
ax_resid = plt.gca()
if ax_resid is not None:
ax_resid.scatter(x, y - yhat, color = 'red')
ax_resid.plot([4, 14], [0, 0], color = 'black')
ax_resid.set_title("Residuals")
return fig
# Load in four different datasets: I, II, III, IV
x = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5]
y1 = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]
y2 = [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74]
y3 = [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73]
x4 = [8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8]
y4 = [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89]
anscombe = {
'I': pd.DataFrame(list(zip(x, y1)), columns =['x', 'y']),
'II': pd.DataFrame(list(zip(x, y2)), columns =['x', 'y']),
'III': pd.DataFrame(list(zip(x, y3)), columns =['x', 'y']),
'IV': pd.DataFrame(list(zip(x4, y4)), columns =['x', 'y'])
}
# Plot the scatter plot and line of best fit
fig, axs = plt.subplots(2, 2, figsize = (10, 10))
for i, dataset in enumerate(['I', 'II', 'III', 'IV']):
ans = anscombe[dataset]
x, y = ans['x'], ans['y']
ahat, bhat = fit_least_squares(x, y)
yhat = predict(x, ahat, bhat)
axs[i//2, i%2].scatter(x, y, alpha=0.6, color='red') # plot the x, y points
axs[i//2, i%2].plot(x, yhat) # plot the line of best fit
axs[i//2, i%2].set_xlabel(f'$x_{
i+1}/details>)
axs[i//2, i%2].set_ylabel(f'$y_{
i+1}/details>)
axs[i//2, i%2].set_title(f"Dataset {
dataset}")
plt.show()
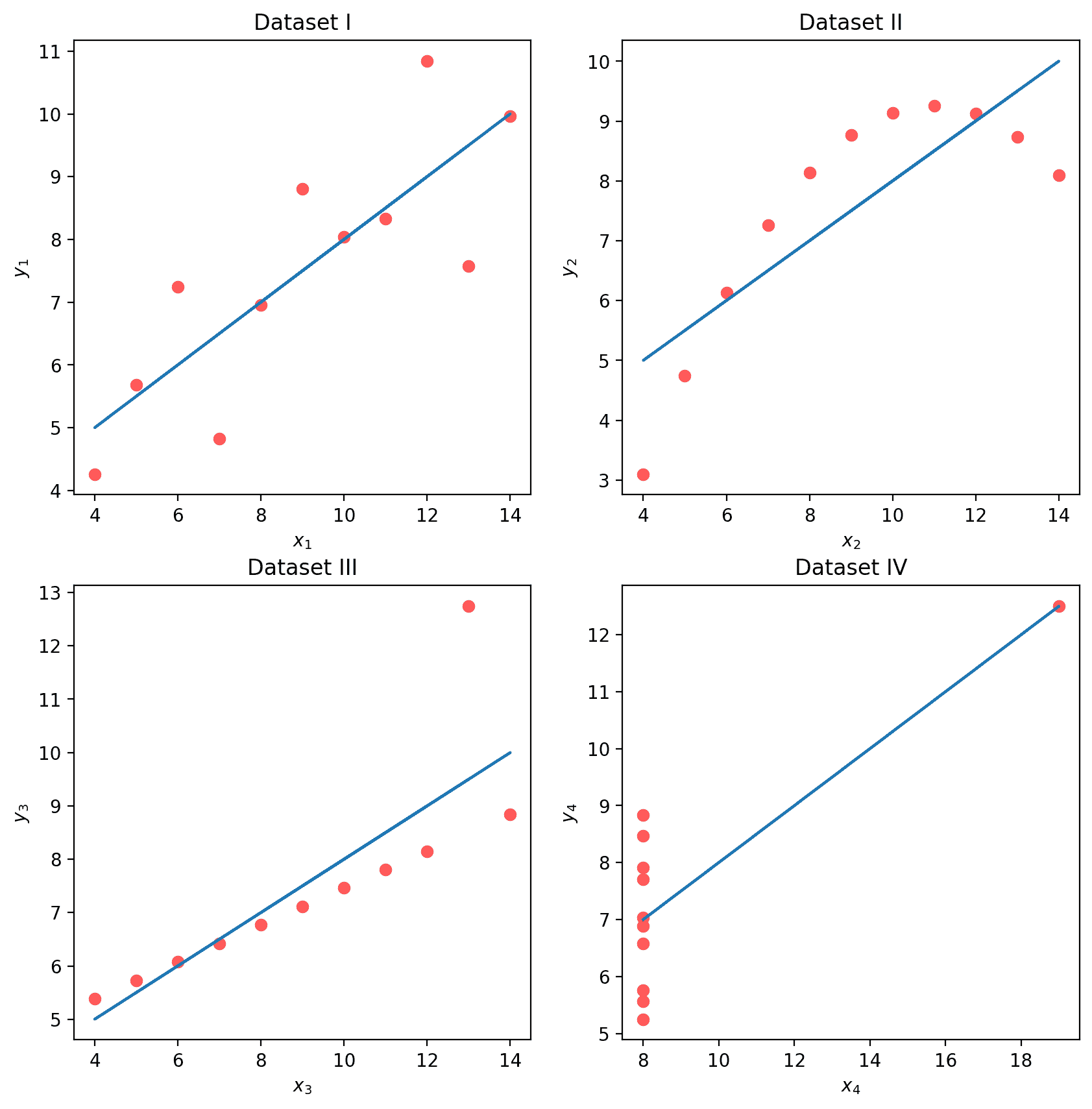
虽然这四组数据点看起来非常不同,但它们实际上都具有相同的 x ˉ \bar x xˉ、 y ˉ \bar y yˉ、 σ x \sigma_x σx、 σ y \sigma_y σy、相关性 r r r和 RMSE!如果我们只看这些统计数据,我们可能会倾向于说这些数据集是相似的。
代码
for dataset in ['I', 'II', 'III', 'IV']:
print(f">>> Dataset {
dataset}:")
ans = anscombe[dataset]
fig = least_squares_evaluation(ans['x'], ans['y'], visualize = NO_VIZ)
print()
print()
>>> Dataset I:
x_mean : 9.00, y_mean : 7.50
x_stdev: 3.16, y_stdev: 1.94
r = Correlation(x, y): 0.816
heta_0: 3.00, heta_1: 0.50
RMSE: 1.119
>>> Dataset II:
x_mean : 9.00, y_mean : 7.50
x_stdev: 3.16, y_stdev: 1.94
r = Correlation(x, y): 0.816
heta_0: 3.00, heta_1: 0.50
RMSE: 1.119
>>> Dataset III:
x_mean : 9.00, y_mean : 7.50
x_stdev: 3.16, y_stdev: 1.94
r = Correlation(x, y): 0.816
heta_0: 3.00, heta_1: 0.50
RMSE: 1.118
>>> Dataset IV:
x_mean : 9.00, y_mean : 7.50
x_stdev: 3.16, y_stdev: 1.94
r = Correlation(x, y): 0.817
heta_0: 3.00, heta_1: 0.50
RMSE: 1.118
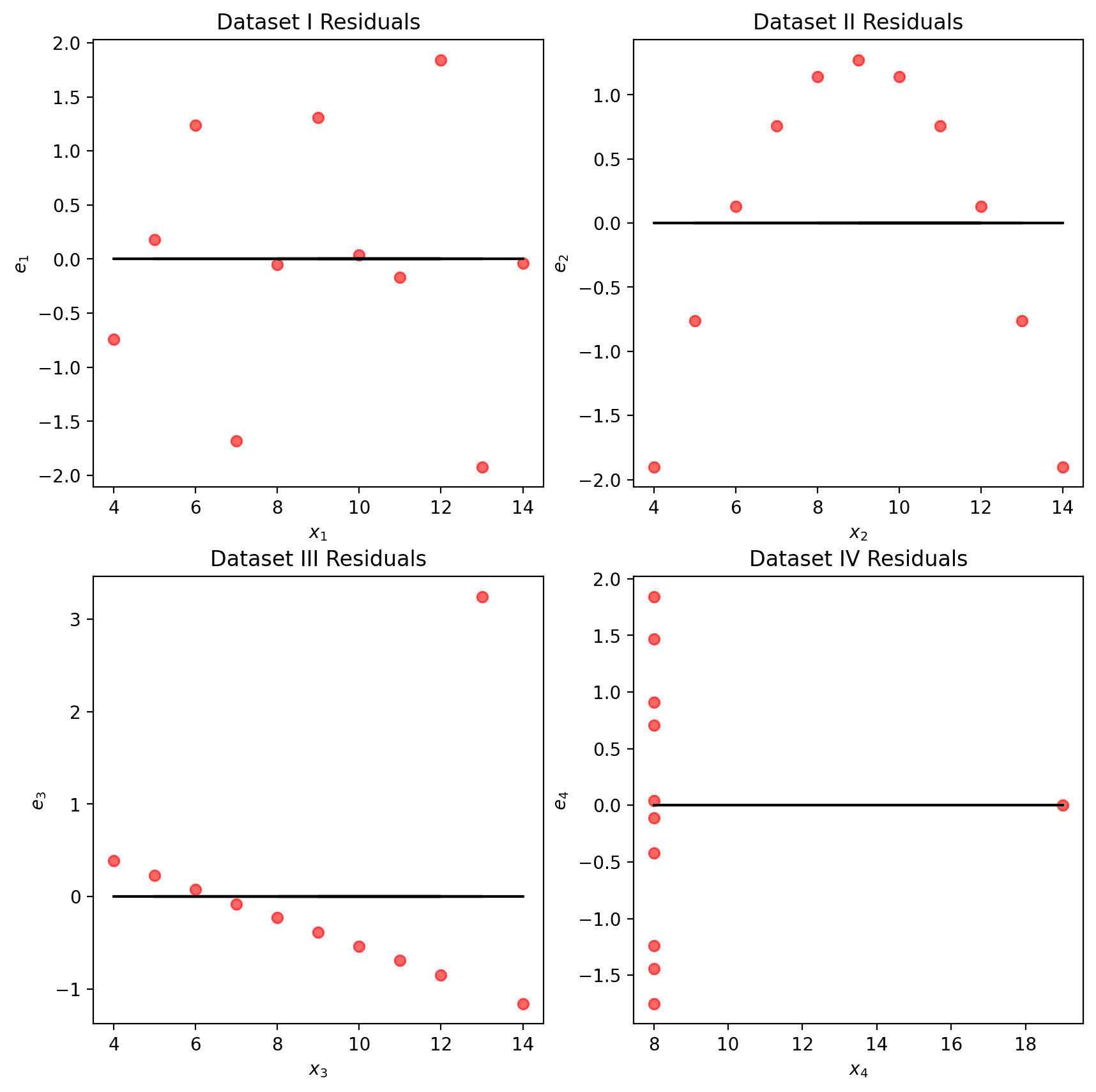
我们可能还希望可视化模型的残差,定义为观察值和预测的 y i y_i yi值之间的差异( e i = y i − y ^ i e_i = y_i - \hat{y}_i ei=yi−y^i)。这提供了每个预测与真实观察值的“偏差”的高层视图。回想一下,你在Data 8中探讨过这个概念:一个好的回归拟合在其残差图中不应显示出明显的模式。Anscombe 的四重奏的残差图如下所示。请注意,只有第一个图显示出残差大小没有明显模式。这表明 SLR 不是剩下的三组点的最佳模型的指示。
代码
# Residual visualization
fig, axs = plt.subplots(2, 2, figsize = (10, 10))
for i, dataset in enumerate(['I', 'II', 'III', 'IV']):
ans = anscombe[dataset]
x, y = ans['x'], ans['y']
ahat, bhat = fit_least_squares(x, y)
yhat = predict(x, ahat, bhat)
axs[i//2, i%2].scatter(x, y - yhat, alpha=0.6, color='red') # plot the x, y points
axs[i//2, i%2].plot(x, np.zeros_like(x), color='black') # plot the residual line
axs[i//2, i%2].set_xlabel(f'$x_{
i+1}/details>)
axs[i//2, i%2].set_ylabel(f'$e_{
i+1}/details>)
axs[i//2, i%2].set_title(f"Dataset {
dataset} Residuals")
plt.show()
11.1.2 预测 vs. 估计
术语预测和估计通常在某种程度上可以互换使用,但它们之间有微妙的区别。估计是使用数据计算模型参数的任务。预测是使用模型预测未见数据的输出的任务。在我们的简单线性回归模型中
y ^ = θ 0 ^ + θ 1 ^ \hat{y} = \hat{\theta_0} + \hat{\theta_1} y^=θ0^+θ1^
我们通过最小化平均损失来估计参数;然后,我们使用这些估计来预测。最小二乘估计是选择最小化 MSE 的参数。
11.2 常数模型 + MSE
现在,我们将从 SLR 模型转换为常数模型,也称为汇总统计。常数模型与我们之前探索过的简单线性回归模型略有不同。常数模型不是从输入的特征变量生成预测,而是始终预测相同的常数数字。这忽略了变量之间的任何关系。例如,假设我们想要预测一家波霸店一天卖出的饮料数量。波霸茶的销售可能取决于一年中的时间、天气、顾客的感觉、学校是否在上课等等,但常数模型忽略了这些因素,而更倾向于一个更简单的模型。换句话说,常数模型采用了一个简化的假设。
它也是一个参数化的统计模型:
y ^ i = θ 0 \hat{y}_i = \theta_0 y^i=θ0
θ 0 \theta_0 θ0是常数模型的参数,就像 θ 0 \theta_0 θ0和 θ 1 \theta_1 θ1是 SLR 中的参数一样。由于我们的参数 θ 0 \theta_0 θ0是一维的( θ 0 ∈ R \theta_0 \in \mathbb{R} θ0∈R),我们现在的模型没有输入,将始终预测 y ^ i = θ 0 \hat{y}_i = \theta_0 y^i=θ0。
11.2.1 推导最优的 θ 0 \theta_0 θ0
我们现在的任务是确定什么值的 θ 0 \theta_0 θ0最能代表最佳模型 - 换句话说,每次猜测什么数字可以在我们的数据上获得最低可能的平均损失?
像以前一样,我们将使用均方误差(MSE)。回想一下,MSE 是数据 D = { y 1 , y 2 , . . . , y n } D = \{y_1, y_2, ..., y_n\} D={ y1,y2,...,yn}上的平均平方损失(L2 损失)。
R ( θ ) = 1 n ∑ i = 1 n ( y i − y i ^ ) 2 R(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \hat{y_i})^2 R(θ)=n1i=1∑n(yi−yi^)2
我们的建模过程现在看起来像这样:
-
选择模型:常数模型
-
选择损失函数:L2 损失
-
拟合模型
-
评估模型性能
给定常数模型 y ^ i = θ 0 \hat{y}_i = \theta_0 y^i=θ0,我们可以将 MSE 方程重写为
R ( θ ) = 1 n ∑ i = 1 n ( y i − θ 0 ) 2 R(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2 R(θ)=n1i=1∑n(yi−θ0)2
我们可以通过找到最优的 θ 0 \theta_0 θ0来拟合模型,从而最小化 MSE,使用微积分方法。
- 对 θ 0 \theta_0 θ0求导
d d θ 0 R ( θ ) = d d θ 0 1 n ∑ i = 1 n ( y i − θ 0 ) 2 = n ∑ i = 1 n d d θ 0 ( y i − θ 0 ) 2 求和的导数是导数的和 = n ∑ i = 1 n 2 ( y i − θ 0 ) ( − 1 ) 链式法则 = − 2 n ∑ i = 1 n ( y i − θ 0 ) 简单的常数 \begin{align} \frac{d}{d\theta_0}\text{R}(\theta) & = \frac{d}{d\theta_0}\frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2 \\ &= {n}\sum^{n}_{i=1} \frac{d}{d\theta_0} (y_i - \theta_0)^2 \quad \quad \text{求和的导数是导数的和} \\ &= {n}\sum^{n}_{i=1} 2 (y_i - \theta_0) (-1) \quad \quad \text{链式法则} \\ &= {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \theta_0) \quad \quad \text{简单的常数} \end{align} dθ0dR(θ)=dθ0dn1i=1∑n(yi−θ0)2=ni=1∑ndθ0d(yi−θ0)2求和的导数是导数的和=ni=1∑n2(yi−θ0)(−1)链式法则=n−2i=1∑n(yi−θ0)简单的常数
-
等于 0 0 = − 2 n ∑ i = 1 n ( y i − θ 0 ) 0 = {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \theta_0) 0=n−2i=1∑n(yi−θ0)
-
解出 θ 0 \theta_0 θ0
0 = − 2 n ∑ i = 1 n ( y i − θ 0 ) = ∑ i = 1 n ( y i − θ 0 ) 两边同时除以 − 2 n = ∑ i = 1 n y i − ∑ i = 1 n θ 0 分开求和 = ∑ i = 1 n y i − n ∗ θ 0 c + c + … + c = nc n ∗ θ 0 = ∑ i = 1 n y i θ 0 = 1 n ∑ i = 1 n y i θ 0 = y ˉ \begin{align} 0 &= {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \theta_0) \\ &= \sum^{n}_{i=1} (y_i - \theta_0) \quad \quad \text{两边同时除以} \frac{-2}{n} \\ &= \sum^{n}_{i=1} y_i - \sum^{n}_{i=1} \theta_0 \quad \quad \text{分开求和} \\ &= \sum^{n}_{i=1} y_i - n * \theta_0 \quad \quad \text{c + c + … + c = nc} \\ n * \theta_0 &= \sum^{n}_{i=1} y_i \\ \theta_0 &= \frac{1}{n} \sum^{n}_{i=1} y_i \\ \theta_0 &= \bar{y} \end{align} 0n∗θ0θ0θ0=n−2i=1∑n(yi−θ0)=i=1∑n(yi−θ0)两边同时除以n−2=i=1∑nyi−i=1∑nθ0分开求和=i=1∑nyi−n∗θ0c + c + … + c = nc=i=1∑nyi=n1i=1∑nyi=yˉ
让我们花点时间解释一下这个结果。 θ ^ = y ˉ \hat{\theta} = \bar{y} θ^=yˉ 是常数模型 + MSE 的最佳参数。无论你有什么样的数据样本,它都是成立的,并且它提供了一些正式的推理,解释了为什么均值是如此常见的摘要统计量。
我们的最佳模型参数是使成本函数最小化的参数值。成本函数的最小值可以表示为:
R ( θ ^ ) = min θ R ( θ ) R(\hat{\theta}) = \min_{\theta} R(\theta) R(θ^)=θminR(θ)
用简单的英语重新陈述上面的内容:当成本函数以最佳参数作为输入时,我们正在查看成本函数的值。这个最佳模型参数 θ ^ \hat{\theta} θ^ 是使成本 R R R 最小化的 θ \theta θ 的值。
对于建模目的,我们更关心成本的最小值 R ( θ ^ ) R(\hat{\theta}) R(θ^),而不是导致这种最低平均损失的 * θ \theta θ 的值。换句话说,我们关心找到最佳参数值,使得:
θ ^ = arg min θ R ( θ ) \hat{\theta} = \underset{\theta}{\operatorname{\arg\min}}\:R(\theta) θ^=θargminR(θ)
也就是说,我们想要找到使成本函数最小化的参数 θ \theta θ。
11.2.2 比较两个不同的模型,都使用 MSE 进行拟合
现在我们已经探讨了带有 L2 损失的常数模型,我们可以将其与上一讲学到的 SLR 模型进行比较。考虑下面的数据集,其中包含嘴海牛的年龄和长度信息。假设我们想要预测嘴海牛的年龄:
| 常数模型 | 简单线性回归 | |
|---|---|---|
| 模型 | y ^ = θ 0 \hat{y} = \theta_0 y^=θ0 | y ^ = θ 0 + θ 1 x \hat{y} = \theta_0 + \theta1 x y^=θ0+θ1x |
| 数据 | 年龄样本 D = { y 1 , y 2 , . . . , y m } D = \{y_1, y_2, ..., y_m\} D={ y1,y2,...,ym} | 年龄样本 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } D = \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\} D={(x1,y1),(x2,y2),...,(xn,yn)} |
| 维度 | θ 0 ^ \hat{\theta_0} θ0^ 是 1-D | θ ^ = [ θ 0 ^ , θ 1 ^ ] \hat{\theta} = [\hat{\theta_0}, \hat{\theta_1}] θ^=[θ0^,θ1^] 是 2-D |
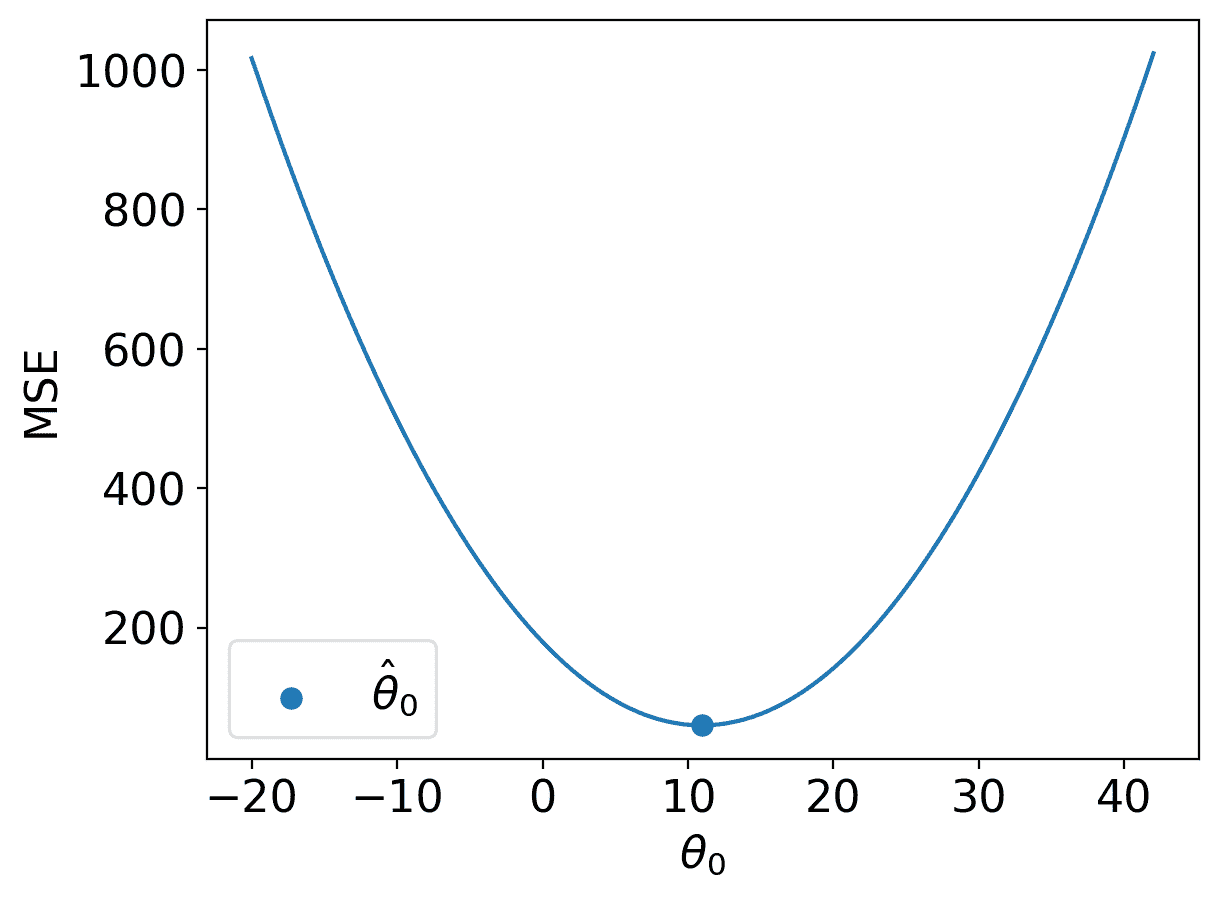
| 损失曲面 | 2-D 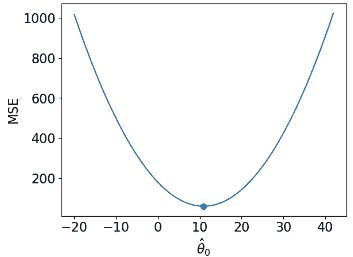 |
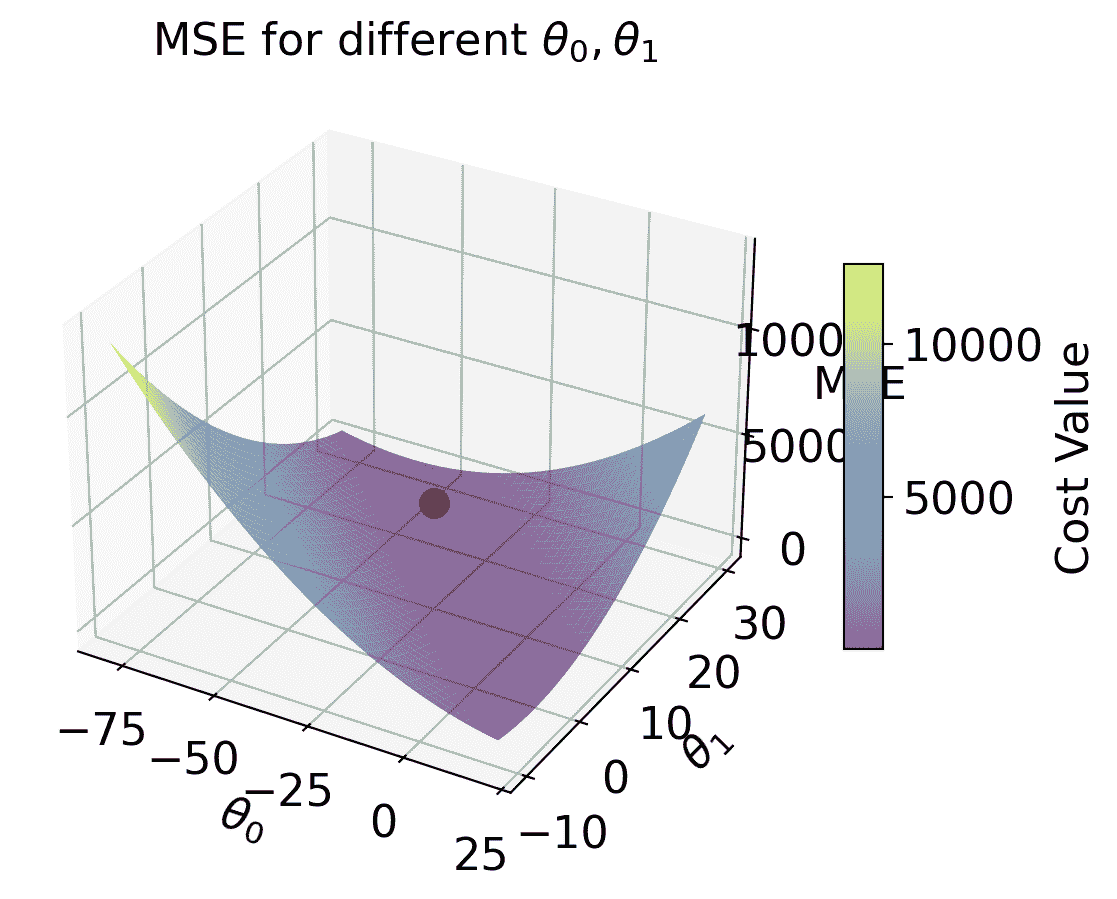
3-D  |
| 损失模型 | R ^ ( θ ) = 1 n ∑ i = 1 n ( y i − θ 0 ) 2 \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2 R^(θ)=n1∑i=1n(yi−θ0)2 | R ^ ( θ ) = 1 n ∑ i = 1 n ( y i − ( θ 0 + θ 1 x ) ) 2 \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - (\theta_0 + \theta_1 x))^2 R^(θ)=n1∑i=1n(yi−(θ0+θ1x))2 |
| RMSE | 7.72 | 4.31 |
| 可视化预测 | 地毯图 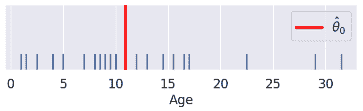 |
散点图 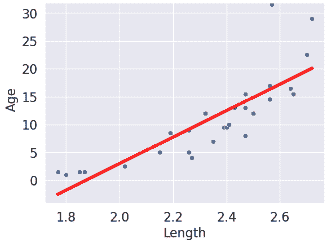 |
(注意我们的 SLR 散点图的点在视觉上并不是一个很好的线性拟合。我们会回到这个问题)。
生成图形和模型的代码如下,但我们不会深入讨论。
代码
dugongs = pd.read_csv("data/dugongs.csv")
data_constant = dugongs["Age"]
data_linear = dugongs[["Length", "Age"]]
# Constant Model + MSE
plt.style.use('default') # Revert style to default mpl
adjust_fontsize(size=16)
%matplotlib inline
def mse_constant(theta, data):
return np.mean(np.array([(y_obs - theta) ** 2 for y_obs in data]), axis=0)
thetas = np.linspace(-20, 42, 1000)
l2_loss_thetas = mse_constant(thetas, data_constant)
# Plotting the loss surface
plt.plot(thetas, l2_loss_thetas)
plt.xlabel(r'$\theta_0/details>)
plt.ylabel(r'MSE')
# Optimal point
thetahat = np.mean(data_constant)
plt.scatter([thetahat], [mse_constant(thetahat, data_constant)], s=50, label = r"$\hat{\theta}_0$")
plt.legend();
# plt.show()
代码
# SLR + MSE
def mse_linear(theta_0, theta_1, data_linear):
data_x, data_y = data_linear.iloc[:,0], data_linear.iloc[:,1]
return np.mean(np.array([(y - (theta_0+theta_1*x)) ** 2 for x, y in zip(data_x, data_y)]), axis=0)
# plotting the loss surface
theta_0_values = np.linspace(-80, 20, 80)
theta_1_values = np.linspace(-10, 30, 80)
mse_values = np.array([[mse_linear(x,y,data_linear) for x in theta_0_values] for y in theta_1_values])
# Optimal point
data_x, data_y = data_linear.iloc[:, 0], data_linear.iloc[:, 1]
theta_1_hat = np.corrcoef(data_x, data_y)[0, 1] * np.std(data_y) / np.std(data_x)
theta_0_hat = np.mean(data_y) - theta_1_hat * np.mean(data_x)
# Create the 3D plot
fig = plt.figure(figsize=(7, 5))
ax = fig.add_subplot(111, projection='3d')
X, Y = np.meshgrid(theta_0_values, theta_1_values)
surf = ax.plot_surface(X, Y, mse_values, cmap='viridis', alpha=0.6) # Use alpha to make it slightly transparent
# Scatter point using matplotlib
sc = ax.scatter([theta_0_hat], [theta_1_hat], [mse_linear(theta_0_hat, theta_1_hat, data_linear)],
marker='o', color='red', s=100, label='theta hat')
# Create a colorbar
cbar = fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10)
cbar.set_label('Cost Value')
ax.set_title('MSE for different $\\theta_0, \\theta_1/details>)
ax.set_xlabel('$\\theta_0/details>)
ax.set_ylabel('$\\theta_1/details>)
ax.set_zlabel('MSE')
# plt.show()
Text(0.5, 0, 'MSE')
代码
# Predictions
yobs = data_linear["Age"] # The true observations y
xs = data_linear["Length"] # Needed for linear predictions
n = len(yobs) # Predictions
yhats_constant = [thetahat for i in range(n)] # Not used, but food for thought
yhats_linear = [theta_0_hat + theta_1_hat * x for x in xs]
# Constant Model Rug Plot
# In case we're in a weird style state
sns.set_theme()
adjust_fontsize(size=16)
%matplotlib inline
fig = plt.figure(figsize=(8, 1.5))
sns.rugplot(yobs, height=0.25, lw=2) ;
plt.axvline(thetahat, color='red', lw=4, label=r"$\hat{\theta}_0$");
plt.legend()
plt.yticks([]);
# plt.show()
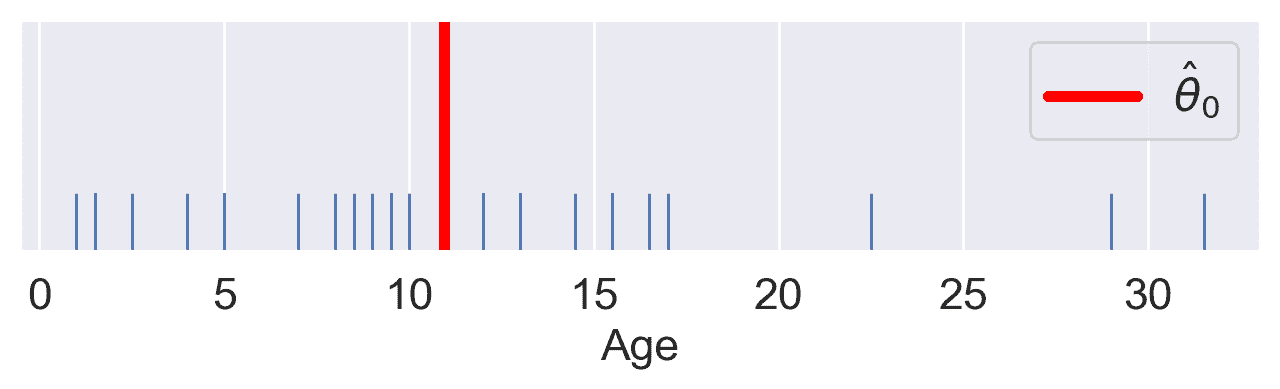
代码
# SLR model scatter plot
# In case we're in a weird style state
sns.set_theme()
adjust_fontsize(size=16)
%matplotlib inline
sns.scatterplot(x=xs, y=yobs)
plt.plot(xs, yhats_linear, color='red', lw=4);
# plt.savefig('dugong_line.png', bbox_inches = 'tight');
# plt.show()

解释 RMSE(均方根误差):* 常数误差高于线性误差。
因此,* 常数模型比线性模型更差(至少对于这个度量)。
11.3 常数模型 + MAE
我们现在看到,改变用于预测的模型会导致最佳模型参数的结果大不相同。如果我们改变模型评估中使用的损失函数会发生什么?
这一次,我们将考虑具有 L1(绝对损失)作为损失函数的常数模型。这意味着平均损失将被表示为平均绝对误差(MAE)。
-
选择模型:常数模型
-
选择损失函数:L1 损失
-
拟合模型
-
评估模型性能
11.3.1 求解最优 θ 0 \theta_0 θ0
回想一下,MAE 是数据 D = { y 1 , y 2 , . . . , y m } D = \{y_1, y_2, ..., y_m\} D={ y1,y2,...,ym} 上的平均绝对损失(L1 损失)。
R ^ ( θ ) = 1 n ∑ i = 1 n ∣ y i − y i ^ ∣ \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \hat{y_i}| R^(θ)=n1i=1∑n∣yi−yi^∣
给定常数模型 y ^ = θ 0 \hat{y} = \theta_0 y^=θ0,我们可以将 MAE 写成:
R ^ ( θ ) = 1 n ∑ i = 1 n ∣ y i − θ 0 ∣ \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \theta_0| R^(θ)=n1i=1∑n∣yi−θ0∣
为了拟合模型,我们通过微积分方法找到最优参数值 θ ^ \hat{\theta} θ^:
- 对 θ 0 ^ \hat{\theta_0} θ0^ 求导数。
R ^ ( θ ) = 1 n ∑ i = 1 n ∣ y i − θ ∣ \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \theta| R^(θ)=n1i=1∑n∣yi−θ∣
d d θ R ( θ ) = d d θ ( 1 n ∑ i = 1 n ∣ y i − θ ∣ ) \frac{d}{d\theta} R(\theta) = \frac{d}{d\theta} \left(\frac{1}{n} \sum^{n}_{i=1} |y_i - \theta| \right) dθdR(θ)=dθd(n1i=1∑n∣yi−θ∣)
= 1 n ∑ i = 1 n d d θ ∣ y i − θ ∣ = \frac{1}{n} \sum^{n}_{i=1} \frac{d}{d\theta} |y_i - \theta| =n1i=1∑ndθd∣yi−θ∣
-
这里,我们似乎遇到了一个问题:当参数为 0 时(即 y i = θ y_i = \theta yi=θ)绝对值的导数是未定义的。现在,我们将忽略这个问题。事实证明,忽略这种情况不会影响我们的最终结果。
-
进行导数运算时,考虑两种情况。当 θ \theta θ 小于或等于 y i y_i yi 时,项 y i − θ y_i - \theta yi−θ 将为正值,绝对值不会产生影响。当 θ \theta θ 大于 y i y_i yi 时,项 y i − θ y_i - \theta yi−θ 将为负值。应用绝对值将其转换为正值,我们可以表示为 − ( y i − θ ) = θ − y i -(y_i - \theta) = \theta - y_i −(yi−θ)=θ−yi。
∣ y i − θ ∣ = { y i − θ 如果 θ ≤ y i θ − y i 如果 θ > y i |y_i - \theta| = \begin{cases} y_i - \theta \quad \text{ 如果 } \theta \le y_i \\ \theta - y_i \quad \text{如果 }\theta > y_i \end{cases} ∣yi−θ∣={ yi−θ 如果 θ≤yiθ−yi如果 θ>yi
- 求导:
d d θ ∣ y i − θ ∣ = { d d θ ( y i − θ ) = − 1 如果 θ < y i d d θ ( θ − y i ) = 1 如果 θ > y i \frac{d}{d\theta} |y_i - \theta| = \begin{cases} \frac{d}{d\theta} (y_i - \theta) = -1 \quad \text{如果 }\theta < y_i \\ \frac{d}{d\theta} (\theta - y_i) = 1 \quad \text{如果 }\theta > y_i \end{cases} dθd∣yi−θ∣={ dθd(yi−θ)=−1如果 θ<yidθd(θ−yi)=1如果 θ>yi
- 这意味着我们对于 θ < y i \theta < y_i θ<yi 和 θ > y i \theta > y_i θ>yi 的数据点得到了不同的导数值。我们可以总结为:
d d θ R ( θ ) = 1 n ∑ i = 1 n d d θ ∣ y i − θ ∣ = 1 n [ ∑ θ 0 ^ < y i ( − 1 ) + ∑ θ 0 ^ > y i ( + 1 ) ] \frac{d}{d\theta} R(\theta) = \frac{1}{n} \sum^{n}_{i=1} \frac{d}{d\theta} |y_i - \theta| \\ = \frac{1}{n} \left[\sum_{\hat{\theta_0} < y_i} (-1) + \sum_{\hat{\theta_0} > y_i} (+1) \right] dθdR(θ)=n1i=1∑ndθd∣yi−θ∣=n1 θ0^<yi∑(−1)+θ0^>yi∑(+1)
-
换句话说,我们取 i = 1 , 2 , . . . , n i = 1, 2, ..., n i=1,2,...,n 的值的总和:
-
如果我们的观察值 y i y_i yi 大于 我们的预测值 θ 0 ^ \hat{\theta_0} θ0^,则为 − 1 -1 −1
-
如果我们的观察值 y i y_i yi 小于 我们的预测值 θ 0 ^ \hat{\theta_0} θ0^,则为 + 1 +1 +1
-
-
置为 0。 0 = 1 n ∑ θ 0 ^ < y i ( − 1 ) + 1 n ∑ θ 0 ^ > y i ( + 1 ) 0 = \frac{1}{n}\sum_{\hat{\theta_0} < y_i} (-1) + \frac{1}{n}\sum_{\hat{\theta_0} > y_i} (+1) 0=n1θ0^<yi∑(−1)+n1θ0^>yi∑(+1)
-
求解 θ 0 ^ \hat{\theta_0} θ0^。 0 = − 1 n ∑ θ 0 ^ < y i ( 1 ) + 1 n ∑ θ 0 ^ > y i ( 1 ) 0 = -\frac{1}{n}\sum_{\hat{\theta_0} < y_i} (1) + \frac{1}{n}\sum_{\hat{\theta_0} > y_i} (1) 0=−n1θ0^<yi∑(1)+n1θ0^>yi∑(1)
∑ θ 0 ^ < y i ( 1 ) = ∑ θ 0 ^ > y i ( 1 ) \sum_{\hat{\theta_0} < y_i} (1) = \sum_{\hat{\theta_0} > y_i} (1) θ0^<yi∑(1)=θ0^>yi∑(1)
因此,最小化 MAE 的常数模型参数 θ = θ 0 ^ \theta = \hat{\theta_0} θ=θ0^ 必须满足:
∑ θ 0 ^ < y i ( 1 ) = ∑ θ 0 ^ > y i ( 1 ) \sum_{\hat{\theta_0} < y_i} (1) = \sum_{\hat{\theta_0} > y_i} (1) θ0^<yi∑(1)=θ0^>yi∑(1)
换句话说,大于 θ 0 \theta_0 θ0 的观察数量必须等于小于 θ 0 \theta_0 θ0 的观察数量;方程的左右两侧必须有相等数量的点。这就是中位数的定义,因此我们的最优值是 θ 0 ^ = m e d i a n ( y ) \hat{\theta_0} = median(y) θ0^=median(y)
11.4 总结:损失优化、微积分和临界点
首先,将目标函数定义为平均损失。
-
代入 L1 或 L2 损失。
-
代入模型,使得结果表达为 θ \theta θ 的函数。
然后,找到目标函数的最小值:
-
对 θ \theta θ 求导数。
-
置为 0。
-
求解 θ ^ \hat{\theta} θ^。
-
(如果我们有多个参数)重复步骤 1-3,使用偏导数。
回想微积分中的临界点: R ( θ ^ ) R(\hat{\theta}) R(θ^)可能是一个最小值、最大值或者鞍点!* 从技术上讲,我们还应该进行二阶导数测试,即,展示 R ′ ′ ( θ ^ ) > 0 R''(\hat{\theta}) > 0 R′′(θ^)>0。* MSE 具有一个特性——凸性——它保证了 R ( θ ^ ) R(\hat{\theta}) R(θ^) 是一个全局最小值。* MAE 的凸性证明超出了本课程的范围。
11.5 比较损失函数
我们现在已经尝试了在 MSE 和 MAE 成本函数下拟合模型。这两个结果如何比较?
让我们考虑一个数据集,其中每个条目代表了泡泡茶店每天卖出的饮料数量。我们将拟合一个常数模型来预测明天将卖出的饮料数量。
drinks = np.array([20, 21, 22, 29, 33])
drinks
array([20, 21, 22, 29, 33])
根据我们上面的推导,我们知道 MSE 成本下的最佳模型参数是数据集的均值。在 MAE 成本下,最佳参数是数据集的中位数。
np.mean(drinks), np.median(drinks)
(25.0, 22.0)
如果我们在几个可能的 θ \theta θ 值上绘制每个经验风险函数,我们会发现每个 θ ^ \hat{\theta} θ^ 确实对应于最低的错误值:
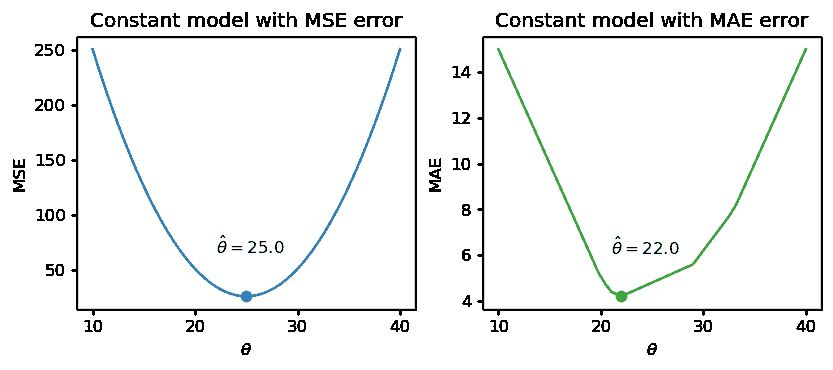
注意上面的 MSE 是一个平滑函数——它在所有点上都是可微的,这使得用数值方法最小化它变得容易。相比之下,MAE 在每个“拐点”处都不可微。我们将在几周内探讨成本函数的平滑性如何影响我们应用数值优化的能力。
异常值如何影响每个成本函数?想象一下,我们用 1000 替换数据集中的最大值。数据的均值显著增加,而中位数几乎不受影响。
drinks_with_outlier = np.append(drinks, 1033)
display(drinks_with_outlier)
np.mean(drinks_with_outlier), np.median(drinks_with_outlier)
array([ 20, 21, 22, 29, 33, 1033])
(193.0, 25.5)
这意味着在 MSE 下,最佳模型参数 θ ^ \hat{\theta} θ^ 受到异常值的影响。在 MAE 下,最佳参数不受异常数据的影响。我们可以通过说 MSE 对异常值敏感,而 MAE 对异常值稳健来概括这一点。
让我们尝试另一个实验。这一次,我们将向数据中添加一个额外的非异常数据点。
drinks_with_additional_observation = np.append(drinks, 35)
drinks_with_additional_observation
array([20, 21, 22, 29, 33, 35])
当我们再次可视化成本函数时,我们发现 MAE 现在在 22 和 29 之间绘制了一条水平线。这意味着模型参数有无数个最佳值:任何值 θ ^ ∈ [ 22 , 29 ] \hat{\theta} \in [22, 29] θ^∈[22,29] 都将最小化 MAE。相比之下,MSE 仍然有一个最佳的 θ ^ \hat{\theta} θ^ 值。换句话说,MSE 有一个唯一的 θ ^ \hat{\theta} θ^ 解;MAE 不能保证有一个唯一的解。

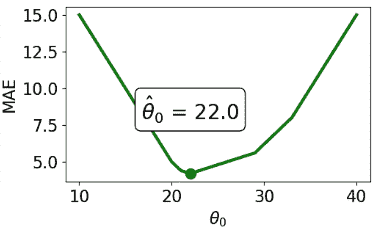
总结我们的例子,
| – | MSE(均方损失) | MAE(平均绝对损失) |
|---|---|---|
| 损失函数 | R ^ ( θ ) = 1 n ∑ i = 1 n ( y i − θ 0 ) 2 \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2 R^(θ)=n1∑i=1n(yi−θ0)2 | R ^ ( θ ) = 1 n ∑ i = 1 n ∣ ; y i − θ 0 ∣ \hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} |;y_i - \theta_0| R^(θ)=n1∑i=1n∣;yi−θ0∣ |
| 最佳 θ 0 ^ \hat{\theta_0} θ0^ | θ 0 ^ = m e a n ( y ) = y ˉ \hat{\theta_0} = mean(y) = \bar{y} θ0^=mean(y)=yˉ | θ 0 ^ = m e d i a n ( y ) \hat{\theta_0} = median(y) θ0^=median(y) |
| 损失曲面 |  |
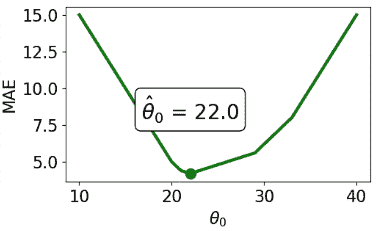 |
| 形状 | 平滑 - 容易使用数值方法最小化(在几周内) | 分段 - 在每个“拐点”处,它不可微。更难最小化。 |
| 异常值 | 对异常值敏感(因为它们会显著改变均值)。敏感性还取决于数据集的大小。 | 对异常值更加稳健。 |
| θ 0 ^ \hat{\theta_0} θ0^ 唯一性 | 唯一 θ 0 ^ \hat{\theta_0} θ0^ | 无数个 θ 0 ^ \hat{\theta_0} θ0^ |
11.6 转换以拟合线性模型
到目前为止,我们已经有了一种有效的方法来拟合模型以预测线性关系。给定一个特征变量和目标,我们可以应用我们的四步过程来找到最佳的模型参数。
上面的关键词是线性。当我们之前计算参数估计时,我们假设 x i x_i xi和 y i y_i yi之间存在大致线性的关系。现实世界中的数据并不总是那么简单,但我们可以对数据进行转换以尝试获得线性关系。
Tukey-Mosteller Bulge Diagram是一个总结两个变量之间关系线性化的变换的有用工具。要确定哪些变换可能合适,追踪数据形成的“凸起”的形状。找到与此凸起匹配的图表象限。该象限的垂直和水平轴上显示的变换可以帮助改善变量之间的拟合。
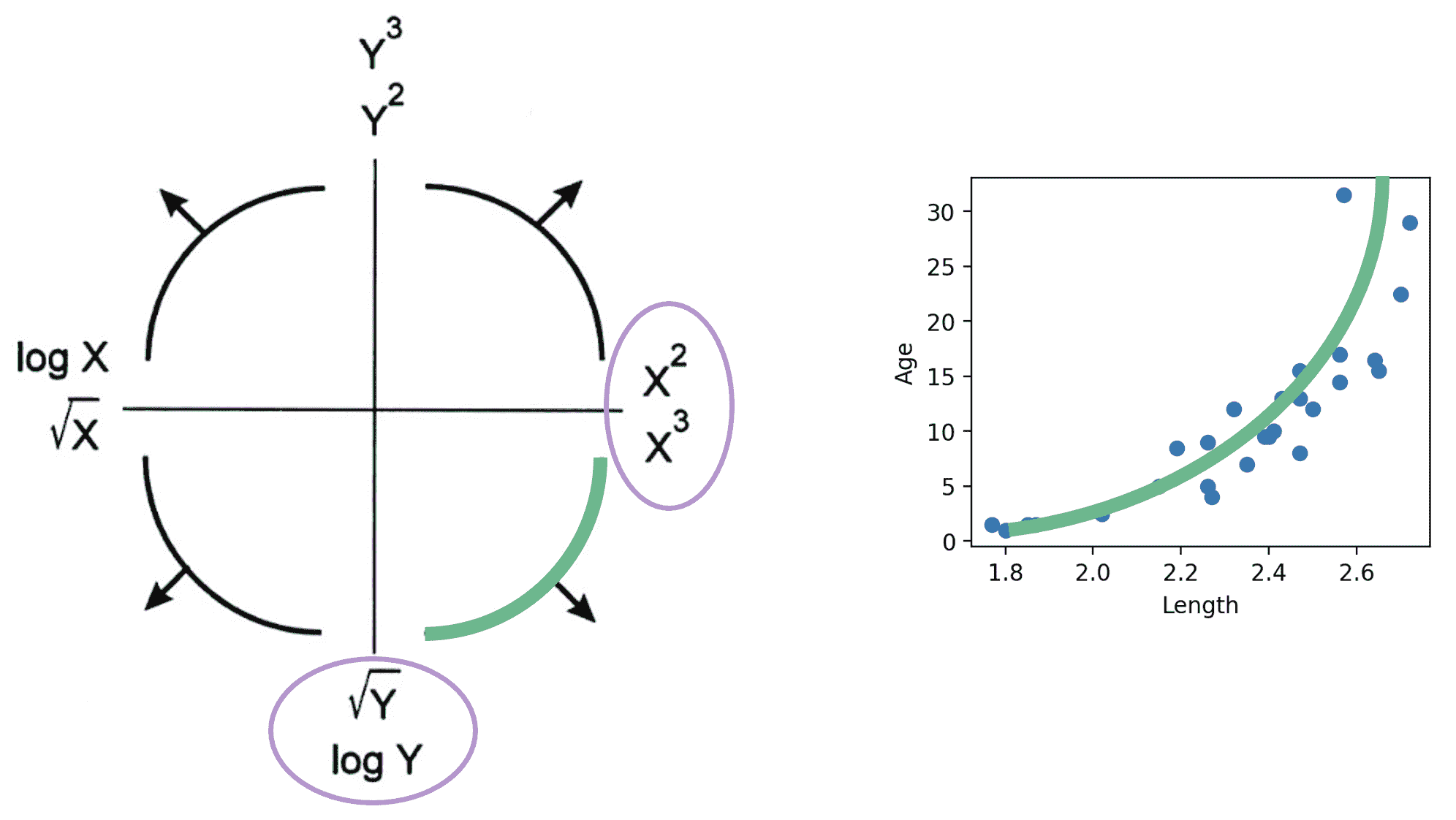
注意:
-
有多种解决方案。有些比其他的拟合效果更好。
-
sqrt 和 log 使值“变小”。
-
提高到幂会使值“变大”。
-
这些变换中的每一个都等同于增加或减少轴的比例。
除了线性之外,还有其他可能的目标,例如使数据看起来更对称。线性允许我们对转换后的数据进行拟合。
让我们重新看一下我们的儒艮示例。长度和年龄如下图所示:
代码
# `corrcoef` computes the correlation coefficient between two variables
# `std` finds the standard deviation
x = dugongs["Length"]
y = dugongs["Age"]
r = np.corrcoef(x, y)[0, 1]
theta_1 = r*np.std(y)/np.std(x)
theta_0 = np.mean(y) - theta_1*np.mean(x)
fig, ax = plt.subplots(1, 2, dpi=200, figsize=(8, 3))
ax[0].scatter(x, y)
ax[0].set_xlabel("Length")
ax[0].set_ylabel("Age")
ax[1].scatter(x, y)
ax[1].plot(x, theta_0 + theta_1*x, "tab:red")
ax[1].set_xlabel("Length")
ax[1].set_ylabel("Age");
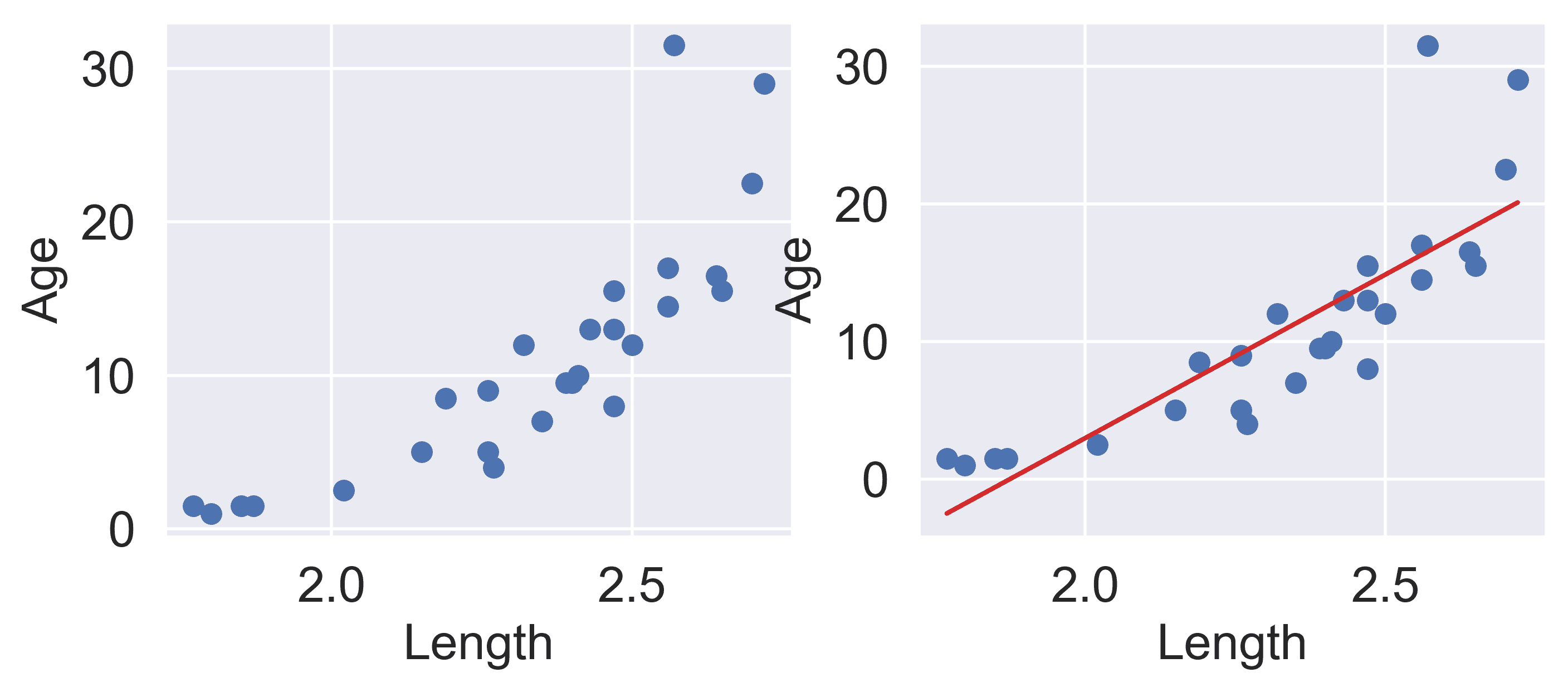
在左边的图中,我们看到数据点有轻微的曲线。在右边绘制 SLR 曲线会导致拟合效果不佳。
为了使 SLR 表现良好,我们希望“年龄”和“长度”之间存在粗略的线性趋势。是什么导致原始数据偏离线性关系?注意到“长度”大于 2.6 的数据点相对于其他数据有着不成比例的高“年龄”值。如果我们能够操纵这些数据点使其具有较低的“年龄”值,我们将“移动”这些点向下并减少数据中的曲率。对 y i y_i yi应用对数变换(即取 log ( \log( log(“年龄” ) ) ))就可以实现这一点。
关于 log \log log的重要说明:在 Data 100(以及大多数高年级 STEM 课程)中, log \log log表示以 e e e为底的自然对数。在相关情况下,以 10 为底的对数用 log 10 \log_{10} log10表示。
代码
z = np.log(y)
r = np.corrcoef(x, z)[0, 1]
theta_1 = r*np.std(z)/np.std(x)
theta_0 = np.mean(z) - theta_1*np.mean(x)
fig, ax = plt.subplots(1, 2, dpi=200, figsize=(8, 3))
ax[0].scatter(x, z)
ax[0].set_xlabel("Length")
ax[0].set_ylabel(r"$\log{(Age)}$")
ax[1].scatter(x, z)
ax[1].plot(x, theta_0 + theta_1*x, "tab:red")
ax[1].set_xlabel("Length")
ax[1].set_ylabel(r"$\log{(Age)}$")
plt.subplots_adjust(wspace=0.3);
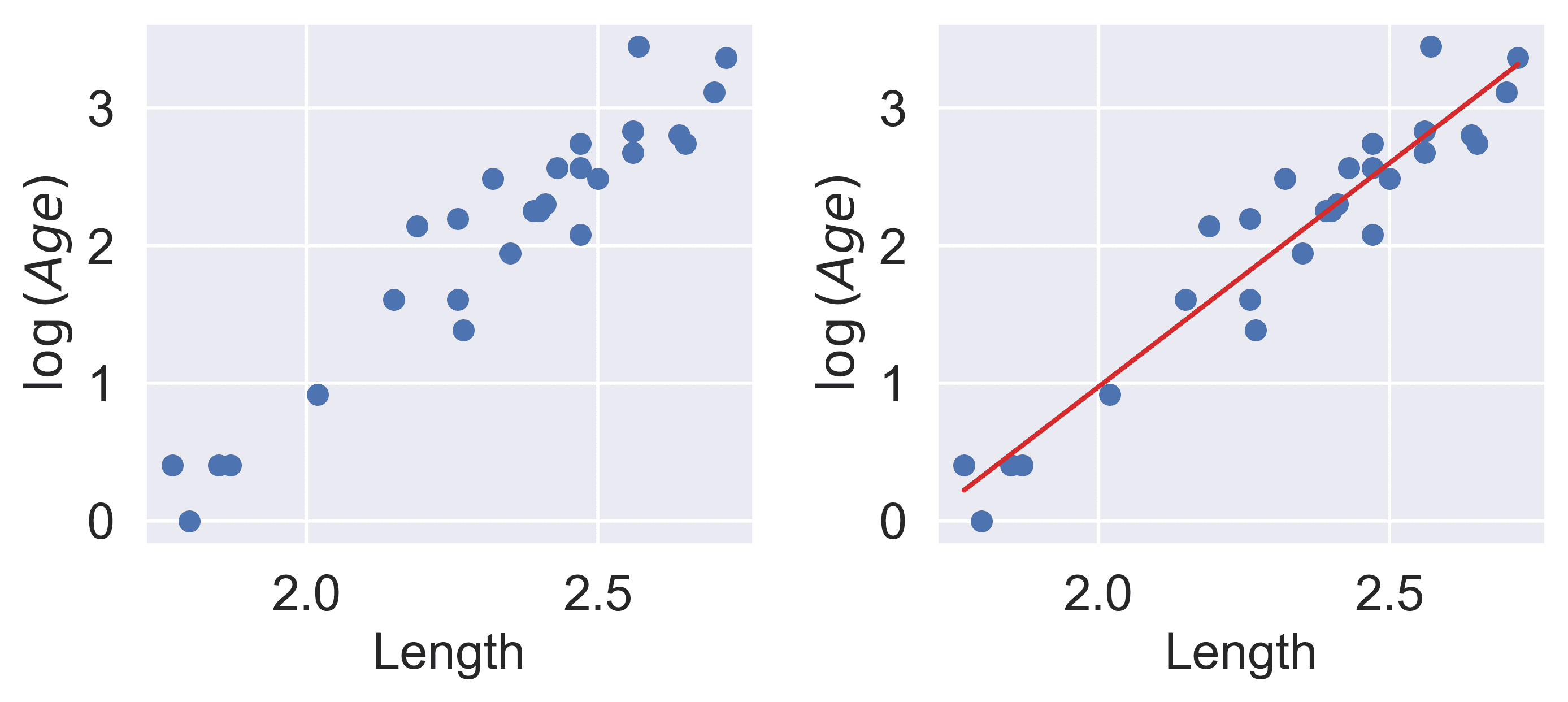
我们的 SLR 拟合看起来好多了!我们现在有了一个新的目标变量:SLR 模型现在试图预测“年龄”的对数,而不是未经转换的“年龄”。换句话说,我们应用了变换 z i = log ( y i ) z_i = \log{(y_i)} zi=log(yi)。注意到得到的模型仍然是参数线性的 θ = [ θ 0 , θ 1 ] \theta = [\theta_0, \theta_1] θ=[θ0,θ1]。SLR 模型变为:
log ( y i ) ^ = θ 0 + θ 1 x i \log{\hat{(y_i)}} = \theta_0 + \theta_1 x_i log(yi)^=θ0+θ1xi
z ^ i = θ 0 + θ 1 x i \hat{z}_i = \theta_0 + \theta_1 x_i z^i=θ0+θ1xi
事实证明,这种线性化关系可以帮助我们理解 x i x_i xi和 y i y_i yi之间的基本关系。如果我们重新排列上面的关系,我们会发现: log ( y i ) = θ 0 + θ 1 x i y i = e θ 0 + θ 1 x i y i = ( e θ 0 ) e θ 1 x i y i = C e k x i \log{(y_i)} = \theta_0 + \theta_1 x_i \\ y_i = e^{\theta_0 + \theta_1 x_i} \\ y_i = (e^{\theta_0})e^{\theta_1 x_i} \\ y_i = C e^{k x_i} log(yi)=θ0+θ1xiyi=eθ0+θ1xiyi=(eθ0)eθ1xiyi=Cekxi
对于一些常数 C C C和 k k k。
y i y_i yi是 x i x_i xi的指数函数。对未经转换的变量应用指数拟合可以证实这一发现。
代码
plt.figure(dpi=120, figsize=(4, 3))
plt.scatter(x, y)
plt.plot(x, np.exp(theta_0)*np.exp(theta_1*x), "tab:red")
plt.xlabel("Length")
plt.ylabel("Age");

你可能会想:为什么我们选择特别应用对数变换?为什么不使用其他函数来线性化数据?
实际上,许多其他修改“年龄”和“长度”相对比例的数学运算在这里都可以起作用。
十二、普通最小二乘法
译者:飞龙
学习成果
-
定义关于参数向量 θ \theta θ 的线性性。
-
了解使用矩阵表示法来表达多元线性回归。
-
解释普通最小二乘法为残差向量的范数的最小化。
-
计算多元线性回归的性能指标。
我们现在已经花了很多讲座时间来探讨如何构建有效的模型 - 我们介绍了 SLR 和常数模型,选择了适合我们建模任务的成本函数,并应用了转换来改进线性拟合。
在所有这些情况下,我们考虑了一个特征的模型 ( y ^ i = θ 0 + θ 1 x i \hat{y}_i = \theta_0 + \theta_1 x_i y^i=θ0+θ1xi) 或零个特征的模型 ( y ^ i = θ 0 \hat{y}_i = \theta_0 y^i=θ0)。作为数据科学家,我们通常可以访问包含 许多 特征的数据集。为了建立最佳模型,考虑所有可用的变量作为模型的输入将是有益的,而不仅仅是一个。在今天的讲座中,我们将介绍 多元线性回归 作为将多个特征合并到模型中的框架。我们还将学习如何加速建模过程 - 具体来说,我们将看到线性代数为我们提供了一组强大的工具,用于理解模型性能。
12.1 线性
如果一个表达式是 关于 θ \theta θ (一组参数) 是线性组合,那么它是线性的。检查一个表达式是否可以分解为两个项的矩阵乘积 - 一个 θ \theta θ 向量,和一个不涉及 θ \theta θ 的矩阵/向量 - 是线性的一个很好的指标。
例如,考虑向量 θ = [ θ 0 , θ 1 , θ 2 ] \theta = [\theta_0, \theta_1, \theta_2] θ=[θ0,θ1,θ2]
- y ^ = θ 0 + 2 θ 1 + 3 θ 2 \hat{y} = \theta_0 + 2\theta_1 + 3\theta_2 y^=θ0+2θ1+3θ2 在 theta 上是线性的,我们可以将其分解为两个项的矩阵乘积:
y ^ = [ 1 2 3 ] [ θ 0 θ 1 θ 2 ] \hat{y} = \begin{bmatrix} 1 \space 2 \space 3 \end{bmatrix} \begin{bmatrix} \theta_0 \\ \theta_1 \\ \theta_2 \end{bmatrix} y^=[1 2 3] θ0θ1θ2
- y ^ = θ 0 θ 1 + 2 θ 1 2 + 3 l o g ( θ 2 ) \hat{y} = \theta_0\theta_1 + 2\theta_1^2 + 3log(\theta_2) y^=θ0θ1+2θ12+3log(θ2) 在 theta 上 不 是线性的,因为 θ 1 \theta_1 θ1 项是平方的,而 θ 2 \theta_2 θ2 项是对数的。我们无法将其分解为两个项的矩阵乘积。
12.2 多元线性回归的术语
在回归的背景下有几个等效的术语。我们在本课程中最常用的是加粗的。
-
x x x 可以被称为
-
特征
-
协变量
-
自变量
-
解释变量
-
预测变量
-
输入
-
回归器
-
-
y y y 可以被称为
-
输出
-
结果
-
响应
-
因变量
-
-
y ^ \hat{y} y^ 可以被称为
-
预测
-
预测响应
-
估计值
-
-
θ \theta θ 可以被称为
-
权重
-
参数
-
系数
-
-
θ ^ \hat{\theta} θ^ 可以被称为
-
估计器
-
最佳参数
-
-
一个数据点 ( x , y ) (x, y) (x,y) 也被称为一个观测。
12.3 多元线性回归
多元线性回归是简单线性回归的扩展,它将额外的特征添加到模型中。多元线性回归模型的形式为:
y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ p x p \hat{y} = \theta_0\:+\:\theta_1x_{1}\:+\:\theta_2 x_{2}\:+\:...\:+\:\theta_p x_{p} y^=θ0+θ1x1+θ2x2+...+θpxp
我们对 y y y 的预测值 y ^ \hat{y} y^ 是单个 观测 (特征) x i x_i xi 和参数 θ i \theta_i θi 的线性组合。
我们可以通过查看从 2018-19 NBA 赛季下载的包含每个球员数据的数据集来进一步探讨这个想法,数据来自 Kaggle。
代码
import pandas as pd
nba = pd.read_csv('data/nba18-19.csv', index_col=0)
nba.index.name = None # Drops name of index (players are ordered by rank)
nba.head(5)
| Player | Pos | Age | Tm | G | GS | MP | FG | FGA | FG% | … | FT% | ORB | DRB | TRB | AST | STL | BLK | TOV | PF | PTS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Álex Abrines\abrinal01 | SG | 25 | OKC | 31 | 2 | 19.0 | 1.8 | 5.1 | 0.357 | … | 0.923 | 0.2 | 1.4 | 1.5 | 0.6 | 0.5 | 0.2 | 0.5 | 1.7 | 5.3 |
| 2 | Quincy Acy\acyqu01 | PF | 28 | PHO | 10 | 0 | 12.3 | 0.4 | 1.8 | 0.222 | … | 0.700 | 0.3 | 2.2 | 2.5 | 0.8 | 0.1 | 0.4 | 0.4 | 2.4 | 1.7 |
| 3 | Jaylen Adams\adamsja01 | PG | 22 | ATL | 34 | 1 | 12.6 | 1.1 | 3.2 | 0.345 | … | 0.778 | 0.3 | 1.4 | 1.8 | 1.9 | 0.4 | 0.1 | 0.8 | 1.3 | 3.2 |
| 4 | Steven Adams\adamsst01 | C | 25 | OKC | 80 | 80 | 33.4 | 6.0 | 10.1 | 0.595 | … | 0.500 | 4.9 | 4.6 | 9.5 | 1.6 | 1.5 | 1.0 | 1.7 | 2.6 | 13.9 |
| 5 | Bam Adebayo\adebaba01 | C | 21 | MIA | 82 | 28 | 23.3 | 3.4 | 5.9 | 0.576 | … | 0.735 | 2.0 | 5.3 | 7.3 | 2.2 | 0.9 | 0.8 | 1.5 | 2.5 | 8.9 |
5 行×29 列
假设我们有兴趣预测一名运动员本赛季在篮球比赛中将得分的数量(PTS)。
假设我们想要通过使用球员的一些特征或特征来拟合一个线性模型。具体来说,我们将专注于投篮命中、助攻和三分球出手。
-
FG,每场比赛的(2 分)投篮命中数 -
AST,每场比赛的平均助攻数 -
3PA,每场比赛尝试的三分球数
代码
nba[['FG', 'AST', '3PA', 'PTS']].head()
| FG | AST | 3PA | PTS | |
|---|---|---|---|---|
| 1 | 1.8 | 0.6 | 4.1 | 5.3 |
| 2 | 0.4 | 0.8 | 1.5 | 1.7 |
| 3 | 1.1 | 1.9 | 2.2 | 3.2 |
| 4 | 6.0 | 1.6 | 0.0 | 13.9 |
| 5 | 3.4 | 2.2 | 0.2 | 8.9 |
因为我们现在处理的是许多参数值,我们已经将它们全部收集到了一个维度为 ( p + 1 ) × 1 (p+1) \times 1 (p+1)×1的参数向量中,以保持整洁。记住 p p p代表我们拥有的特征数量(在这种情况下是 3)。
θ = [ θ 0 θ 1 ⋮ θ p ] \theta = \begin{bmatrix} \theta_{0} \\ \theta_{1} \\ \vdots \\ \theta_{p} \end{bmatrix} θ= θ0θ1⋮θp
我们在这里使用两个向量:一个表示观察数据的行向量,另一个包含模型参数的列向量。多元线性回归模型等同于观察向量和参数向量的点(标量)积。
[ 1 , x 1 , x 2 , x 3 , . . . , x p ] θ = [ 1 , x 1 , x 2 , x 3 , . . . , x p ] [ θ 0 θ 1 ⋮ θ p ] = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ p x p [1,\:x_{1},\:x_{2},\:x_{3},\:...,\:x_{p}] \theta = [1,\:x_{1},\:x_{2},\:x_{3},\:...,\:x_{p}] \begin{bmatrix} \theta_{0} \\ \theta_{1} \\ \vdots \\ \theta_{p} \end{bmatrix} = \theta_0\:+\:\theta_1x_{1}\:+\:\theta_2 x_{2}\:+\:...\:+\:\theta_p x_{p} [1,x1,x2,x3,...,xp]θ=[1,x1,x2,x3,...,xp] θ0θ1⋮θp =θ0+θ1x1+θ2x2+...+θpxp
请注意,我们已经在观察向量中插入了 1 作为第一个值。当计算点积时,这个 1 将与 θ 0 \theta_0 θ0相乘,得到回归模型的截距。我们称这个 1 条目为截距或偏差项。
鉴于我们这里有三个特征,我们可以将这个模型表示为: y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 \hat{y} = \theta_0\:+\:\theta_1x_{1}\:+\:\theta_2 x_{2}\:+\:\theta_3 x_{3} y^=θ0+θ1x1+θ2x2+θ3x3
我们的特征由 x 1 x_1 x1(FG)、 x 2 x_2 x2(AST)和 x 3 x_3 x3(3PA)表示,每个特征都有对应的参数 θ 1 \theta_1 θ1、 θ 2 \theta_2 θ2和 θ 3 \theta_3 θ3。
在统计学中,这个模型+损失被称为普通最小二乘法(OLS)。OLS 的解是参数 θ ^ \hat{\theta} θ^的最小损失,也称为最小二乘估计。
12.4 线性代数方法
我们现在知道如何从多个观察特征生成单个预测。数据科学家通常会进行大规模工作 - 也就是说,他们希望构建可以一次产生多个预测的模型。我们上面介绍的向量表示法为我们提供了如何加速多元线性回归的线索。我们想要使用线性代数的工具。
让我们考虑如何应用上面所做的事情。为了适应我们正在考虑多个特征变量的事实,我们将稍微调整我们的符号。现在,每个观察可以被认为是一个行向量,其中每个特征都有一个条目。
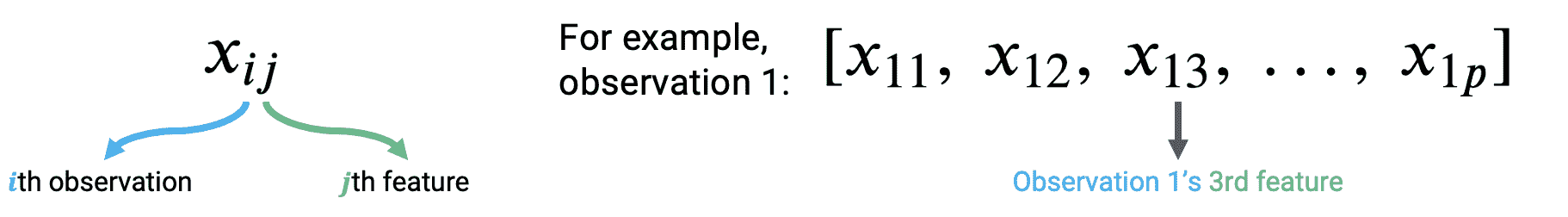
要从数据中的第一个观测中进行预测,我们取参数向量和第一个观测向量的点积。要从第二个观测中进行预测,我们将重复这个过程,找到参数向量和第二个观测向量的点积。如果我们想要找到数据集中每个观测的模型预测,我们将对数据中的所有 n n n个观测重复这个过程。
y ^ 1 = θ 0 + θ 1 x 11 + θ 2 x 12 + . . . + θ p x 1 p = [ 1 , x 11 , x 12 , x 13 , . . . , x 1 p ] θ \hat{y}_1 = \theta_0 + \theta_1 x_{11} + \theta_2 x_{12} + ... + \theta_p x_{1p} = [1,\:x_{11},\:x_{12},\:x_{13},\:...,\:x_{1p}] \theta y^1=θ0+θ1x11+θ2x12+...+θpx1p=[1,x11,x12,x13,...,x1p]θ
y ^ 2 = θ 0 + θ 1 x 21 + θ 2 x 22 + . . . + θ p x 2 p = [ 1 , x 21 , x 22 , x 23 , . . . , x 2 p ] θ \hat{y}_2 = \theta_0 + \theta_1 x_{21} + \theta_2 x_{22} + ... + \theta_p x_{2p} = [1,\:x_{21},\:x_{22},\:x_{23},\:...,\:x_{2p}] \theta y^2=θ0+θ1x21+θ2x22+...+θpx2p=[1,x21,x22,x23,...,x2p]θ
⋮ \vdots ⋮
y ^ n = θ 0 + θ 1 x n 1 + θ 2 x n 2 + . . . + θ p x n p = [ 1 , x n 1 , x n 2 , x n 3 , . . . , x n p ] θ \hat{y}_n = \theta_0 + \theta_1 x_{n1} + \theta_2 x_{n2} + ... + \theta_p x_{np} = [1,\:x_{n1},\:x_{n2},\:x_{n3},\:...,\:x_{np}] \theta y^n=θ0+θ1xn1+θ2xn2+...+θpxnp=[1,xn1,xn2,xn3,...,xnp]θ
我们的观测数据由 n n n个行向量表示,每个向量的维度为 ( p + 1 ) (p+1) (p+1)。我们可以将它们全部收集到一个称为 X \mathbb{X} X的单个矩阵中。

矩阵 X \mathbb{X} X被称为设计矩阵。它包含了我们 p p p个特征的所有观测数据,其中每一行对应一个观测,每一列对应一个特征。它通常(但并非总是)包含一个额外的全为 1 的列来表示截距或偏置列。
回顾设计矩阵中发生的情况:每一行代表一个单独的观测。例如,数据 100 中的一个学生。每一列代表一个特征。例如,数据 100 中学生的年龄。这个约定使我们能够轻松地将我们在数据框中的先前工作转移到这种新的线性代数视角。
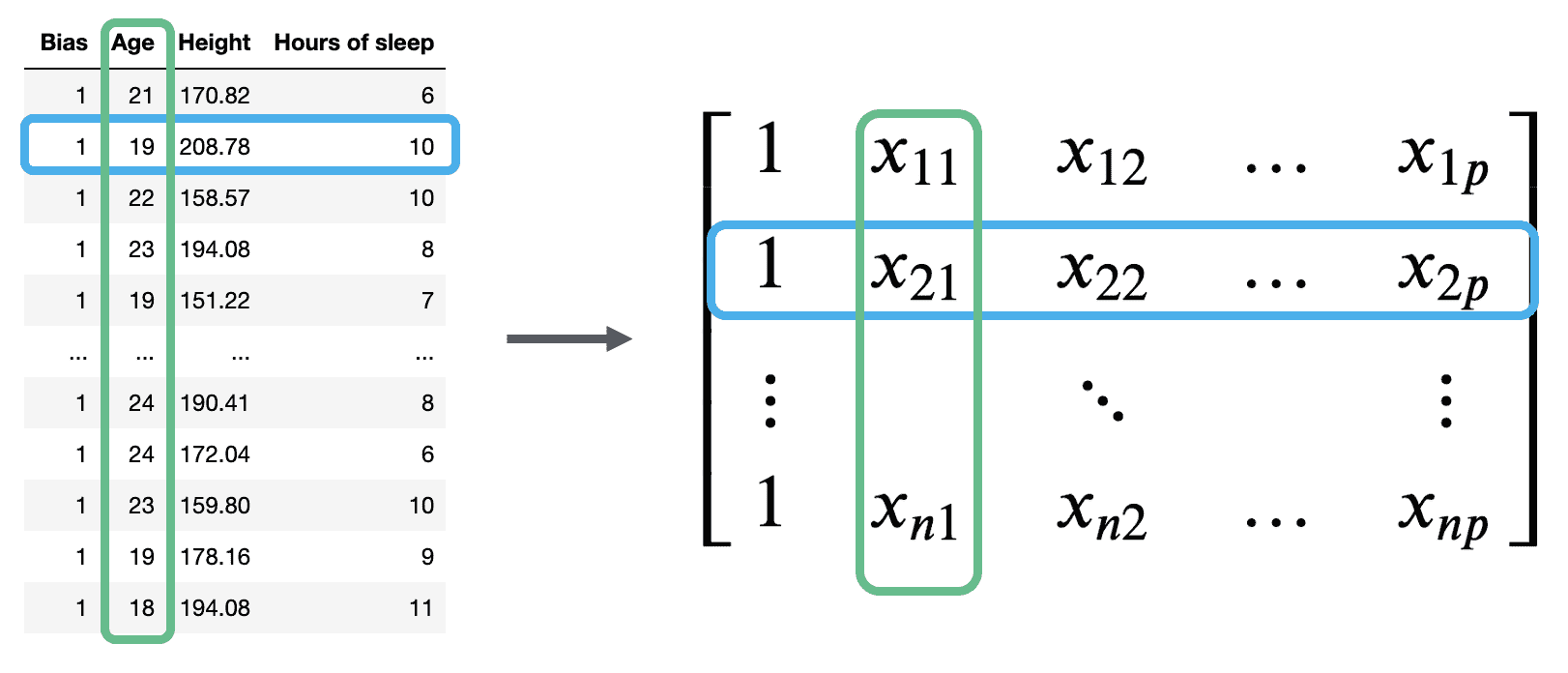
多元线性回归模型可以用矩阵的术语重新表述: Y ^ = X θ \Large \mathbb{\hat{Y}} = \mathbb{X} \theta Y^=Xθ
在这里, Y ^ \mathbb{\hat{Y}} Y^是具有 n n n个元素的预测向量( Y ^ ∈ R n \mathbb{\hat{Y}} \in \mathbb{R}^{n} Y^∈Rn);它包含模型对每个 n n n个输入观测的预测。 X \mathbb{X} X是维度为 X ∈ R ( n × ( p + 1 ) ) \mathbb{X} \in \mathbb{R}^(n \times (p + 1)) X∈R(n×(p+1))的设计矩阵, θ \theta θ是维度为 θ ∈ R ( p + 1 ) \theta \in \mathbb{R}^{(p + 1)} θ∈R(p+1)的参数向量。
作为一个复习,让我们也回顾一下点积(或内积)。这是一个向量运算,它:
-
只能在两个相同长度的向量上进行
-
对应向量的乘积求和
-
返回一个单一的数字
虽然这不在范围内,但请注意我们也可以几何地解释点积:
- 它是三个因素的乘积:两个向量的大小和它们之间的角度的余弦: u ⃗ ⋅ v ⃗ = ∣ ∣ u ⃗ ∣ ∣ ⋅ ∣ ∣ v ⃗ ∣ ∣ ⋅ c o s θ \vec{u} \cdot \vec{v} = ||\vec{u}|| \cdot ||\vec{v}|| \cdot {cos \theta} u⋅v=∣∣u∣∣⋅∣∣v∣∣⋅cosθ
12.5 均方误差
现在我们有了一个新的理解模型的方法,以向量和矩阵为基础。为了配合这个新的约定,我们应该更新我们对风险函数和模型拟合的理解。
回想一下我们对 MSE 的定义: R ( θ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 R(\theta) = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 R(θ)=n1i=1∑n(yi−y^i)2
在本质上,MSE 是一种距离的度量 - 它指示了预测值与真实值之间的“距离”平均有多远。
在处理向量时,这种“距离”或向量的大小/长度的概念由范数表示。更确切地说,向量 a ⃗ \vec{a} a和 b ⃗ \vec{b} b之间的距离可以表示为: ∣ ∣ a ⃗ − b ⃗ ∣ ∣ 2 = ( a 1 − b 1 ) 2 + ( a 2 − b 2 ) 2 + … + ( a n − b n ) 2 = ∑ i = 1 n ( a i − b i ) 2 ||\vec{a} - \vec{b}||_2 = \sqrt{(a_1 - b_1)^2 + (a_2 - b_2)^2 + \ldots + (a_n - b_n)^2} = \sqrt{\sum_{i=1}^n (a_i - b_i)^2} ∣∣a−b∣∣2=(a1−b1)2+(a2−b2)2+…+(an−bn)2=i=1∑n(ai−bi)2
双竖线是范数的数学表示。下标 2 表示我们正在计算 L2 范数,或平方范数。
我们需要了解 Data 100 的两种范数是 L1 和 L2 范数(听起来熟悉吗?)。在这篇笔记中,我们将专注于 L2 范数。我们将在未来的讲座中深入探讨 L1 范数。
对于 n 维向量 x ⃗ = [ x 1 x 2 ⋮ x n ] \vec{x} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} x= x1x2⋮xn ,L2 向量范数是
∣ ∣ x ⃗ ∣ ∣ 2 = ( x 1 ) 2 + ( x 2 ) 2 + … + ( x n ) 2 = ∑ i = 1 n ( x i ) 2 ||\vec{x}||_2 = \sqrt{(x_1)^2 + (x_2)^2 + \ldots + (x_n)^2} = \sqrt{\sum_{i=1}^n (x_i)^2} ∣∣x∣∣2=(x1)2+(x2)2+…+(xn)2=i=1∑n(xi)2
L2 向量范数是 n n n维中勾股定理的推广。因此,它可以用作矢量的长度的度量,甚至可以用作两个矢量之间的距离的度量。
我们可以将 MSE 表示为平方 L2 范数,如果我们用预测向量 Y ^ \hat{\mathbb{Y}} Y^和真实目标向量 Y \mathbb{Y} Y来重新表达它:
R ( θ ) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 = 1 n ∣ ∣ Y − Y ^ ∣ ∣ 2 2 R(\theta) = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 = \frac{1}{n} ||\mathbb{Y} - \hat{\mathbb{Y}}||_2^2 R(θ)=n1i=1∑n(yi−y^i)2=n1∣∣Y−Y^∣∣22
这里,范数双条之外的上标 2 表示我们正在平方范数。如果我们插入我们的线性模型 Y ^ = X θ \hat{\mathbb{Y}} = \mathbb{X} \theta Y^=Xθ,我们会发现 MSE 成本函数的向量表示:
R ( θ ) = 1 n ∣ ∣ Y − X θ ∣ ∣ 2 2 R(\theta) = \frac{1}{n} ||\mathbb{Y} - \mathbb{X} \theta||_2^2 R(θ)=n1∣∣Y−Xθ∣∣22
在线性代数的视角下,我们的新任务是拟合最佳参数向量 θ \theta θ,使得成本函数最小化。等价地,我们希望最小化范数 ∣ ∣ Y − X θ ∣ ∣ 2 = ∣ ∣ Y − Y ^ ∣ ∣ 2 . ||\mathbb{Y} - \mathbb{X} \theta||_2 = ||\mathbb{Y} - \hat{\mathbb{Y}}||_2. ∣∣Y−Xθ∣∣2=∣∣Y−Y^∣∣2.
我们可以用两种方式重新表述这个目标:
-
最小化真实值向量 Y \mathbb{Y} Y和预测值向量 Y ^ \mathbb{\hat{Y}} Y^之间的距离
-
最小化残差向量的长度,定义为: e = Y − Y ^ = [ y 1 − y ^ 1 y 2 − y ^ 2 ⋮ y n − y ^ n ] e = \mathbb{Y} - \mathbb{\hat{Y}} = \begin{bmatrix} y_1 - \hat{y}_1 \\ y_2 - \hat{y}_2 \\ \vdots \\ y_n - \hat{y}_n \end{bmatrix} e=Y−Y^= y1−y^1y2−y^2⋮yn−y^n
12.6 几何视角
为了得出最佳参数向量以实现这一目标,我们可以利用我们建模设置的几何特性。
到目前为止,我们大多把我们的模型看作是观测值和参数向量水平堆叠的标量积。我们也可以将 Y ^ \hat{\mathbb{Y}} Y^看作是特征向量的线性组合,由参数缩放。我们使用符号 X : , i \mathbb{X}_{:, i} X:,i来表示设计矩阵的第 i i i列。您可以将其视为在调用.iloc和.loc时使用的相同约定。“:”表示我们正在取第 i i i列中的所有条目。
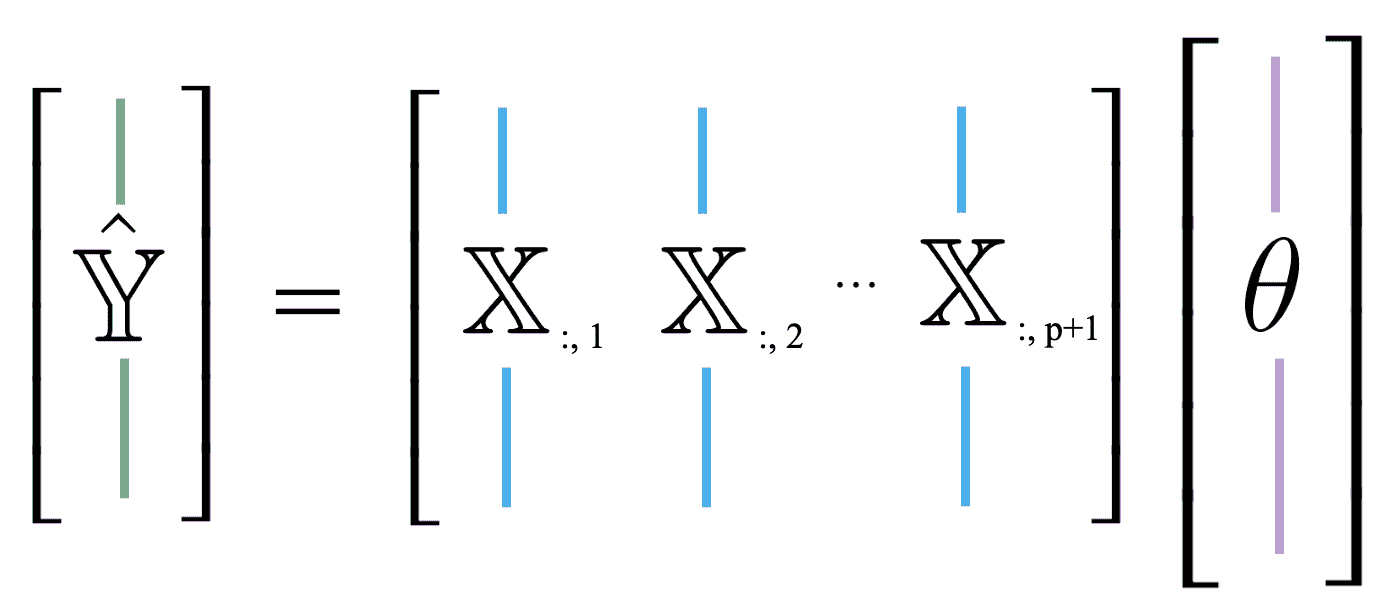
Y ^ = θ 0 [ 1 1 ⋮ 1 ] + θ 1 [ x 11 x 21 ⋮ x n 1 ] + … + θ p [ x 1 p x 2 p ⋮ x n p ] = θ 0 X : , 1 + θ 1 X : , 2 + … + θ p X : , p + 1 \hat{\mathbb{Y}} = \theta_0 \begin{bmatrix} 1 \\ 1 \\ \vdots \\ 1 \end{bmatrix} + \theta_1 \begin{bmatrix} x_{11} \\ x_{21} \\ \vdots \\ x_{n1} \end{bmatrix} + \ldots + \theta_p \begin{bmatrix} x_{1p} \\ x_{2p} \\ \vdots \\ x_{np} \end{bmatrix} = \theta_0 \mathbb{X}_{:,\:1} + \theta_1 \mathbb{X}_{:,\:2} + \ldots + \theta_p \mathbb{X}_{:,\:p+1} Y^=θ0 11⋮1 +θ1 x11x21⋮xn1 +…+θp x1px2p⋮xnp =θ0X:,1+θ1X:,2+…+θpX:,p+1
这种新方法很有用,因为它使我们能够利用线性组合的性质。
回想一下矩阵 X \mathbb{X} X的范围或列空间(表示为 s p a n ( X ) span(\mathbb{X}) span(X))是矩阵列的所有可能线性组合的集合。换句话说,范围代表着可能通过添加和缩放矩阵列的某些组合到达的空间中的每一点。另外,如果 X \mathbb{X} X的每一列的长度为 n n n, s p a n ( X ) span(\mathbb{X}) span(X)是 R n \mathbb{R}^{n} Rn的子空间。
因为预测向量 Y ^ = X θ \hat{\mathbb{Y}} = \mathbb{X} \theta Y^=Xθ是 X \mathbb{X} X的列的线性组合,我们知道预测包含在 X \mathbb{X} X的范围内。也就是说,我们知道 Y ^ ∈ Span ( X ) \mathbb{\hat{Y}} \in \text{Span}(\mathbb{X}) Y^∈Span(X)。
下面的图是对 Span ( X ) \text{Span}(\mathbb{X}) Span(X)的简化视图,假设 X \mathbb{X} X的每一列都有长度 n n n。注意KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at end of input: \mathbb{X的列定义了 R n \mathbb{R}^n Rn的子空间,子空间中的每个点都可以通过 X \mathbb{X} X的列的线性组合到达。预测向量 Y ^ \mathbb{\hat{Y}} Y^位于这个子空间的某个位置。
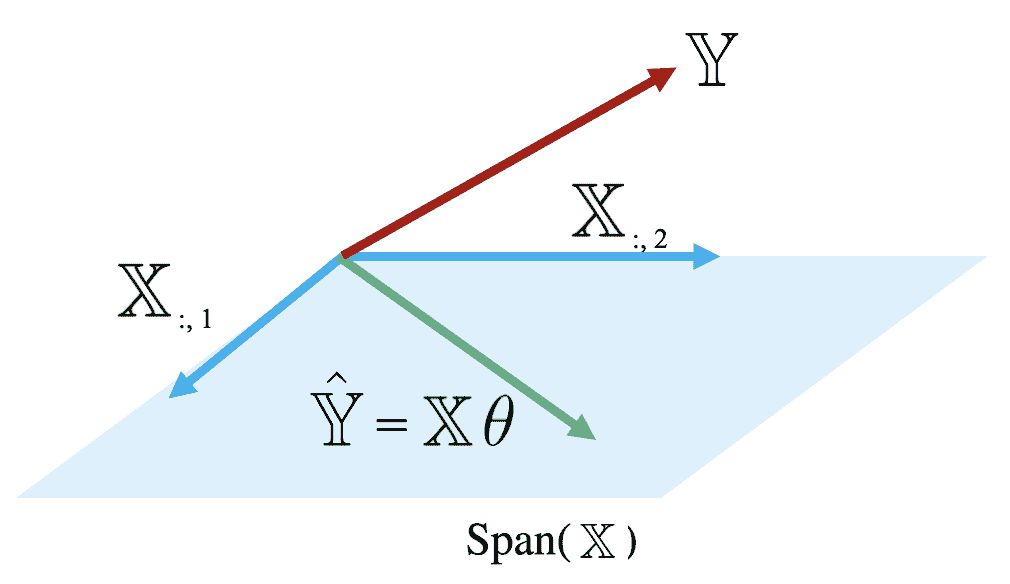
检查这个图,我们发现了一个问题。真实值向量 Y \mathbb{Y} Y理论上可以位于 R n \mathbb{R}^n Rn空间中的任何位置——它的确切位置取决于我们在现实世界中收集的数据。然而,我们的多元线性回归模型只能在 X \mathbb{X} X张成的 R n \mathbb{R}^n Rn空间的子空间中进行预测。记住我们在前一节建立的模型拟合目标:我们希望生成预测,使得真实值向量 Y \mathbb{Y} Y和预测值向量 Y ^ \mathbb{\hat{Y}} Y^之间的距离最小化。这意味着我们希望 Y ^ \mathbb{\hat{Y}} Y^是 Span ( X ) \text{Span}(\mathbb{X}) Span(X)中离 Y \mathbb{Y} Y最近的向量。
另一种重新表述这个目标的方式是,我们希望最小化残差向量 e e e的长度,即其 L 2 L_2 L2范数。
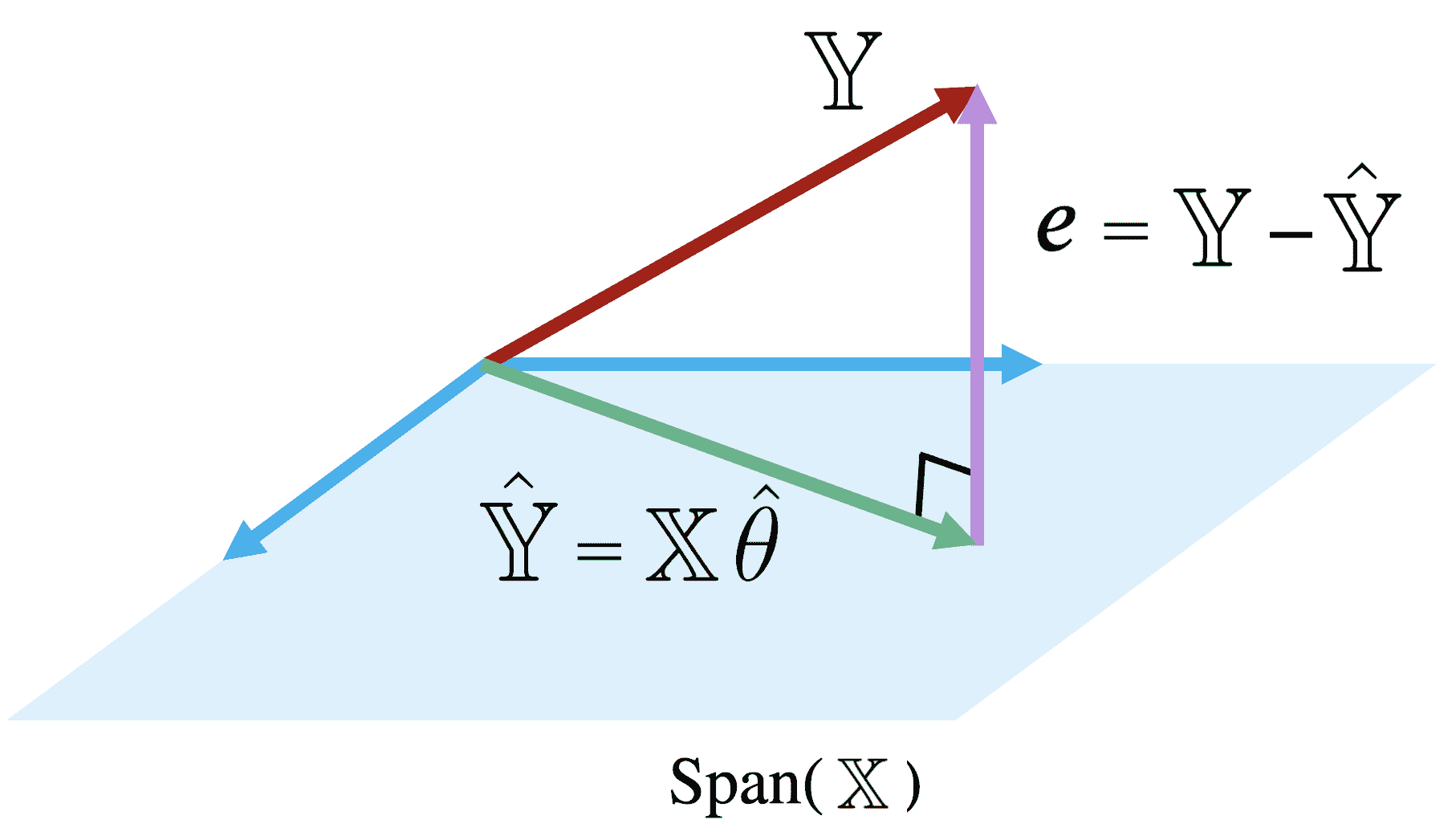
在 Span ( X ) \text{Span}(\mathbb{X}) Span(X)中距离 Y \mathbb{Y} Y最近的向量始终是 Y \mathbb{Y} Y在 Span ( X ) \text{Span}(\mathbb{X}) Span(X)上的正交投影。因此,我们应该选择参数向量 θ \theta θ,使得残差向量与 Span ( X ) \text{Span}(\mathbb{X}) Span(X)中的任何向量正交。你可以将这个想象成从 Y \mathbb{Y} Y到 X \mathbb{X} X的跨度上垂直投影线创建的向量。
这如何帮助我们确定最佳参数向量 θ ^ \hat{\theta} θ^?回想一下,如果两个向量 a a a和 b b b正交,它们的点积为零: a T b = 0 {a}^{T}b = 0 aTb=0。如果向量 v v v正交于矩阵 M M M的张成空间,当且仅当 v v v正交于 M M M中的每一列。综合起来,向量 v v v对于 Span ( M ) \text{Span}(M) Span(M)正交,如果:
M T v = 0 ⃗ M^Tv = \vec{0} MTv=0
请注意, 0 ⃗ \vec{0} 0代表零向量,一个全为 0 的 d d d长度向量。
记住我们的目标是找到 θ ^ \hat{\theta} θ^,使得我们最小化目标函数 R ( θ ) R(\theta) R(θ)。等价地,这就是使得残差向量 e = Y − X θ e = \mathbb{Y} - \mathbb{X} \theta e=Y−Xθ与 Span ( X ) \text{Span}(\mathbb{X}) Span(X)正交的 θ ^ \hat{\theta} θ^。
观察 Y − X θ ^ \mathbb{Y} - \mathbb{X}\hat{\theta} Y−Xθ^与 s p a n ( X ) span(\mathbb{X}) span(X)正交的定义(0 是 0 ⃗ \vec{0} 0向量),我们可以写成: X T ( Y − X θ ^ ) = 0 ⃗ \mathbb{X}^T (\mathbb{Y} - \mathbb{X}\hat{\theta}) = \vec{0} XT(Y−Xθ^)=0
然后我们重新排列项: X T Y − X T X θ ^ = 0 ⃗ \mathbb{X}^T \mathbb{Y} - \mathbb{X}^T \mathbb{X} \hat{\theta} = \vec{0} XTY−XTXθ^=0
最后,我们得到了正规方程: X T X θ ^ = X T Y \mathbb{X}^T \mathbb{X} \hat{\theta} = \mathbb{X}^T \mathbb{Y} XTXθ^=XTY
任何最小化数据集上均方误差的向量 θ \theta θ必须满足这个方程。
如果 X T X \mathbb{X}^T \mathbb{X} XTX是可逆的,我们可以得出结论: θ ^ = ( X T X ) − 1 X T Y \hat{\theta} = (\mathbb{X}^T \mathbb{X})^{-1} \mathbb{X}^T \mathbb{Y} θ^=(XTX)−1XTY
这被称为 θ \theta θ的最小二乘估计:它是使平方损失最小化的 θ \theta θ的值。
请注意,最小二乘估计是在假设 X T X \mathbb{X}^T \mathbb{X} XTX是可逆的条件下推导出来的。当 X T X \mathbb{X}^T \mathbb{X} XTX是满列秩时,这个条件成立,而这又发生在 X \mathbb{X} X是满列秩时。我们将在实验和作业中探讨这个事实的后果。
12.7 评估模型性能
我们对多元线性回归的几何视图已经有了很大的进展!我们已经确定了最小化多个特征模型中的均方误差的参数值的最佳集合。
现在,我们想要了解我们的拟合模型的表现如何。模型性能的一个度量是均方根误差,即 RMSE。RMSE 只是 MSE 的平方根。取平方根将值转换回 y i y_i yi的原始、非平方单位,这对于理解模型的性能很有用。较低的 RMSE 表示更“准确”的预测-在整个数据集中有更低的平均损失。
RMSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
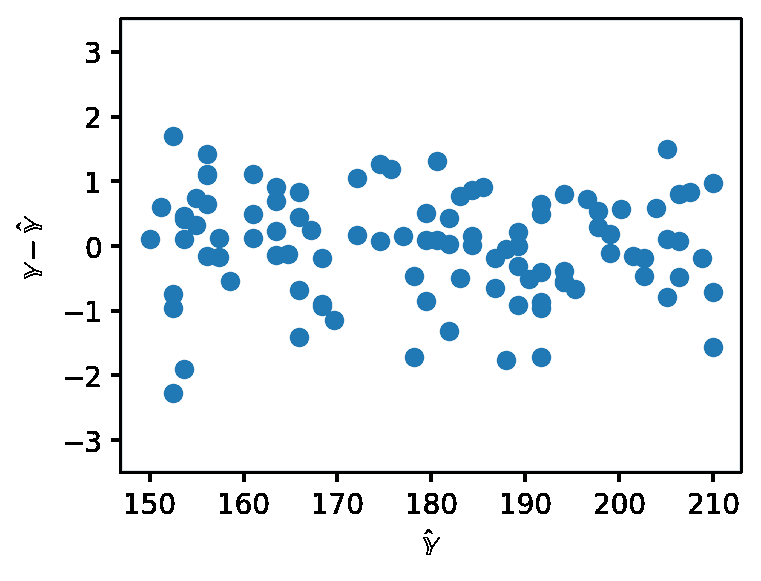
在处理 SLR 时,我们生成了残差与单个特征的图表,以了解残差的行为。在多元线性回归中使用多个特征时,考虑在残差图中只有一个特征不再有意义。相反,多元线性回归通过制作残差与预测值的图表来进行评估。与 SLR 一样,如果多元线性模型的残差图没有模式,则表现良好。
对于 SLR,我们使用相关系数来捕捉目标变量和单个特征变量之间的关联。在多元线性模型设置中,我们将需要一个性能度量,可以同时考虑多个特征。多元 R 2 R^2 R2,也称为决定系数,是我们的拟合值(预测) y ^ i \hat{y}_i y^i的方差比例到真实值 y i y_i yi。它的范围从 0 到 1,实际上是模型解释观察中方差的比例。
R 2 = variance of y ^ i variance of y i = σ y ^ 2 σ y 2 R^2 = \frac{\text{variance of } \hat{y}_i}{\text{variance of } y_i} = \frac{\sigma^2_{\hat{y}}}{\sigma^2_y} R2=variance of yivariance of y^i=σy2σy^2
请注意,对于具有截距项的 OLS,例如 y ^ = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ p x p \hat{y} = \theta_0 + \theta_1x_1 + \theta_2x_2 + \cdots + \theta_px_p y^=θ0+θ1x1+θ2x2+⋯+θpxp, R 2 \mathbb{R}^2 R2等于 y y y和 y ^ \hat{y} y^之间的相关性的平方。另一方面,对于 SLR, R 2 \mathbb{R}^2 R2等于 r 2 r^2 r2,即 x x x和 y y y之间的相关性。这两个属性的证明超出了本课程的范围。
此外,随着我们添加更多的特征,我们的拟合值倾向于越来越接近我们的实际值。因此, R 2 \mathbb{R}^2 R2增加。
然而,增加更多的特征并不总是意味着我们的模型更好!我们将在课程后面看到原因。
12.8 OLS 属性
- 使用最优参数向量时,我们的残差 e = Y − Y ^ e = \mathbb{Y} - \hat{\mathbb{Y}} e=Y−Y^与 s p a n ( X ) span(\mathbb{X}) span(X)正交。
X T e = 0 \mathbb{X}^Te = 0 XTe=0
证明:
- 最优参数向量 θ ^ \hat{\theta} θ^解决了正规方程 ⟹ θ ^ = X T X − 1 X T Y \implies \hat{\theta} = \mathbb{X}^T\mathbb{X}^{-1}\mathbb{X}^T\mathbb{Y} ⟹θ^=XTX−1XTY
X T e = X T ( Y − Y ^ ) \mathbb{X}^Te = \mathbb{X}^T (\mathbb{Y} - \mathbb{\hat{Y}}) XTe=XT(Y−Y^)
X T ( Y − X θ ^ ) = X T Y − X T X θ ^ \mathbb{X}^T (\mathbb{Y} - \mathbb{X}\hat{\theta}) = \mathbb{X}^T\mathbb{Y} - \mathbb{X}^T\mathbb{X}\hat{\theta} XT(Y−Xθ^)=XTY−XTXθ^
- 任何矩阵与其逆矩阵相乘都是单位矩阵 I \mathbb{I} I
X T Y − ( X T X ) ( X T X ) − 1 X T Y = X T Y − X T Y = 0 \mathbb{X}^T\mathbb{Y} - (\mathbb{X}^T\mathbb{X})(\mathbb{X}^T\mathbb{X})^{-1}\mathbb{X}^T\mathbb{Y} = \mathbb{X}^T\mathbb{Y} - \mathbb{X}^T\mathbb{Y} = 0 XTY−(XTX)(XTX)−1XTY=XTY−XTY=0
- 对于所有具有截距项的线性模型,残差的总和为零。
∑ i n e i = 0 \sum_i^n e_i = 0 i∑nei=0
证明:
-
对于所有具有截距项的线性模型,预测的 y y y值的平均值等于真实 y y y值的平均值。 y ˉ = y ^ ˉ \bar{y} = \bar{\hat{y}} yˉ=y^ˉ
-
将残差总和重写为两个单独的总和, ∑ i n e i = ∑ i n y i − ∑ i n y ^ i \sum_i^n e_i = \sum_i^n y_i - \sum_i^n\hat{y}_i i∑nei=i∑nyi−i∑ny^i
-
每个相应的和是平均和的倍数。 ∑ i n e i = n y ˉ − n y ˉ = n ( y ˉ − y ˉ ) = 0 \sum_i^n e_i = n\bar{y} - n\bar{y} = n(\bar{y} - \bar{y}) = 0 i∑nei=nyˉ−nyˉ=n(yˉ−yˉ)=0
- 最小二乘估计 θ ^ \hat{\theta} θ^是唯一的,当且仅当 X \mathbb{X} X是满列秩的。
证明:
-
我们知道正规方程 X T X θ ^ = Y \mathbb{X}^T\mathbb{X}\hat{\theta} = \mathbb{Y} XTXθ^=Y的解是满足先前相等的最小二乘估计。
-
θ ^ \hat{\theta} θ^ 有一个唯一的解 ⟺ \iff ⟺ 方阵 X T X \mathbb{X}^T\mathbb{X} XTX 是可逆的。
-
方阵的列秩是它包含的线性独立列的数量。
-
一个 n n n x n n n 的方阵被认为是完整的列秩当且仅当它的所有列都是线性独立的。也就是说,它的秩等于 n n n。
-
X T X \mathbb{X}^T\mathbb{X} XTX 的形状是 ( p + 1 ) × ( p + 1 ) (p + 1) \times (p + 1) (p+1)×(p+1),因此最大秩为 p + 1 p + 1 p+1。
-
-
r a n k ( X T X ) rank(\mathbb{X}^T\mathbb{X}) rank(XTX) = r a n k ( X ) rank(\mathbb{X}) rank(X)(证明超出范围)。
-
因此, X T X \mathbb{X}^T\mathbb{X} XTX 的秩为 p + 1 p + 1 p+1 ⟺ \iff ⟺ X \mathbb{X} X 的秩为 p + 1 p + 1 p+1 ⟺ X \iff \mathbb{X} ⟺X 是完整的列秩。
总结:
| 模型 | 估计 | 唯一? | |
|---|---|---|---|
| 常数模型 + MSE | y ^ = θ 0 \hat{y} = \theta_0 y^=θ0 | θ 0 ^ = m e a n ( y ) = y ˉ \hat{\theta_0} = mean(y) = \bar{y} θ0^=mean(y)=yˉ | 是。任何一组值都有唯一的均值。 |
| 常数模型 + MAE | y ^ = θ 0 \hat{y} = \theta_0 y^=θ0 | θ 0 ^ = m e d i a n ( y ) \hat{\theta_0} = median(y) θ0^=median(y) | 是,如果是奇数。否,如果是偶数。返回中间 2 个值的平均值。 |
| 简单线性回归 + MSE | y ^ = θ 0 + θ 1 x \hat{y} = \theta_0 + \theta_1x y^=θ0+θ1x | θ 0 ^ = y ˉ − θ 1 ^ x ^ \hat{\theta_0} = \bar{y} - \hat{\theta_1}\hat{x} θ0^=yˉ−θ1^x^ θ 1 ^ = r σ y σ x \hat{\theta_1} = r\frac{\sigma_y}{\sigma_x} θ1^=rσxσy | 是。任何一组非常数*值都有唯一的均值、标准差和相关系数。 |
| OLS(线性模型 + MSE) | Y ^ = X θ \mathbb{\hat{Y}} = \mathbb{X}\mathbb{\theta} Y^=Xθ | θ ^ = X T X − 1 X T Y \hat{\theta} = \mathbb{X}^T\mathbb{X}^{-1}\mathbb{X}^T\mathbb{Y} θ^=XTX−1XTY | 是,如果 X \mathbb{X} X 是完整的列秩(所有列线性独立,数据点的数量 >>> 特征的数量)。 |
智能推荐
泰克Tektronix DPO2014示波器-程序员宅基地
文章浏览阅读354次,点赞7次,收藏8次。杰出的处理能力,迅速解决问题 - MSO2000和DPO2000系列数字荧光示波器 (DPO)为您查看信号和迅速解决问题提供了所需的性能和工具。DPO2000 系列是少有在所有通道上提供了1M 点可用记录长度、串行触发和解码分析选项、可变低通滤波器、允许直到示波器全部带宽查看信号细节及体积小巧的示波器。-体积小,重量轻,深仅5.3 英寸(134mm),重仅7 磅14 盎司(3.6 公斤)混合信号设计和分析(MSO2000 系列)-能够时间相关最多4 条模拟和16 条数字通道。-并行总线触发和分析。
Android百度地图(三):百度地图画运动轨迹及图层点击事件处理_百度地图polyline和轨迹-程序员宅基地
文章浏览阅读2.1w次,点赞11次,收藏107次。上篇文章讲述了如何在地图显示位置点,这篇文章主要讲述如何在地图上画运动轨迹,以及地图图层点击事件的处理。很多运动类的app都有画出跑步者运动轨迹的需求,拿咕咚来说,我们看一下它的效果图:咕咚运动轨迹图本篇将要实现的效果1.跑步结束后,静态的画出整个运动轨迹2.跑步过程中,时时动态的画运动轨迹效果图如何实现:1._百度地图polyline和轨迹
cocos2d 嵌入网页_在 cocos2d-x 中嵌入浏览器-程序员宅基地
文章浏览阅读656次。在 cocos2d-x 中嵌入浏览器次阅读Embeds a browser in cocos2d-x在游戏中嵌入网页是很常见的需求,cocos2d-x 引擎官方并没有提供这个功能。我在网上转了一圈,把找到的资料做了一些修改,将其集成到我们使用的 quick-cocos2d-x 引擎中。主要代码来自:CCXWebview,这里 还有一篇专门讲解Android嵌入浏览器的文章,可以参考。集成的类叫做 ..._cocos2dx pc 内嵌网页
jsoncpp去掉多余字符_拼凑字符串时,去除末尾多余字符的几个方法-程序员宅基地
文章浏览阅读545次。title: 拼凑字符串时,去除末尾多余字符的几个方法date: 2018-08-17 22:12:58tags: [Java,方法]在拼接字符串的时候,经常会发现多了,不想要的字符,让人很是烦恼,这下面总结三个可以去掉烦恼的方法。//循环生成json格式数据public static String CreateJson() {String json="{\"content\":[";for(in..._json 输入的结尾有多余的字符。”
ROS学习笔记49(写一个简单的图像订阅者(C ++))_sensor_msgs::imageconstptr-程序员宅基地
文章浏览阅读1.8k次,点赞3次,收藏15次。1 程序#include <ros/ros.h>#include <image_transport/image_transport.h>#include <opencv2/highgui/highgui.hpp>#include <cv_bridge/cv_bridge.h>void imageCallback(const senso..._sensor_msgs::imageconstptr
jmeter两种设置中文方法_jmeter设置中文-程序员宅基地
文章浏览阅读1.7w次,点赞14次,收藏42次。jmeter两种设置中文方法、jmeter设置为中文方法、jmeter设置为中文的两种方法、jmeter怎么改中文_jmeter设置中文
随便推点
java对象与json对象间的相互转换的方法_接收{}对象,此处接收数组对象会有异常-程序员宅基地
文章浏览阅读446次。String json=JSON.toJSONString(user);//关键1.简单的解析json字符串首先将json字符串转换为json对象,然后再解析json对象,过程如下。 1 JSONObject jsonObject = JSONObject.fromObject(jsonStr); 根据json中的键得到它的值 1 2 3 4 String name = jsonObject.get._接收{}对象,此处接收数组对象会有异常
【小沐学NLP】Python实现图片文字识别_机器学习如何图片中文字识别的程序-程序员宅基地
文章浏览阅读5.3k次,点赞12次,收藏87次。Tesseract最初由惠普实验室支持,用于电子版文字识别,1996年被移植到Windows上,1998年进行了C++化,在2005年Tesseract由惠普公司宣布开源。2006年到现在,由Google公司维护开发。最初Tesseract是用C语言写的,在1998年改用C++。..._机器学习如何图片中文字识别的程序
stm32 定时器输入捕获实验_stm32使用定时器对脉冲进行捕获和计数-程序员宅基地
文章浏览阅读2k次,点赞4次,收藏24次。输入捕获模式可以用来测量脉冲宽度或者测量频率原理图如图 所示,就是输入捕获测量高电平脉宽的原理,假定定时器工作在向上计数模式,图中 t1~t2 时间,就是我们需要测量的高电平时间。测量方法如下:首先设置定时器通道 x 为上升沿捕获,这样, t1 时刻,就会捕获到当前的 CNT 值,然后立即清零 CNT,并设置通道 x为下降沿捕获,这样到 t2 时刻,又会发生捕获事件,得到此时的 CNT 值,记为 CCRx2。这样,根据定时器的计数频率,我们就可以算出 t1~t2 的时间,从而得到高电平脉宽。_stm32使用定时器对脉冲进行捕获和计数
求二叉树最小结点_c语言非空二叉树最小值结点-程序员宅基地
文章浏览阅读5.7k次,点赞6次,收藏46次。struct BTNode{ int data; struct BTNode *lchild; struct BTNode *rchild;}BTNode * MinNode(BTNode *b){ if (b != NULL){ BTNode *min1, *min2, *min; if (b->lchild == NULL &..._c语言非空二叉树最小值结点
Vue.js初学_vue.js初学者-程序员宅基地
文章浏览阅读8.5k次,点赞63次,收藏392次。Vue.js从零开始1、简单认识Vue.jsVue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与现代化的工具链以及各种支持类库结合使用时,Vue 也完全能够为复杂的单页应用提供驱动。2、Vue.js安装CDN引入直接下载然后引入,script方式引用npm方式安装注意开发环境版本(vue.js)和生产环境版_vue.js初学者
html数字跳动加载,【AE】加载动画和数字跳动-程序员宅基地
文章浏览阅读501次。原标题:【AE】加载动画和数字跳动转载一篇晓斌师兄的教程~最近都在研究动效,跟着师兄一起动手吧!转载:吴影浪技 作品:http://www.zcool.com.cn/work/ZMjExNzkxMDQ=.htmlHello,大家好,今天给大家分享一个小案例,就是上面那个图的制作思路,一如既往的,只分享思路,不要在意那些参数。教程分两部分,第一部分是简单说一些AE的工具,方便后面操作(其实是某土豪煤..._数字加载动画