http://www.cnblogs.com/LBSer/p/4068864.html
随着业务快速发展,基于lucene的索引文件zip压缩后也接近了GB量级,而保持索引文件大小为一个可以接受的范围非常有必要,不仅可以提高索引传输、读取速度,还能提高索引cache效率(lucene打开索引文件的时候往往会进行缓存,比如MMapDirectory通过内存映射方式进行缓存)。
如何降低我们的索引文件大小呢?本文进行了一些尝试,下文将一一介绍。
1 数值数据类型索引优化
1.1 数值类型索引问题
lucene本质上是一个全文检索引擎而非传统的数据库系统,它基于倒排索引,非常适合处理文本,而处理数值类型却不是强项。
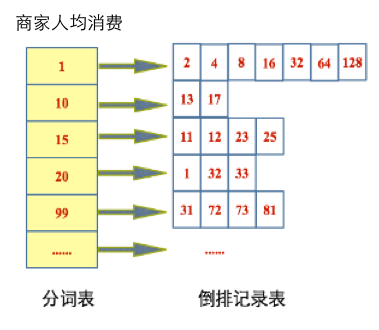
举个应用场景,假设我们倒排存储的是商家,每个商家都有人均消费,用户想查询范围在500~1000这一价格区间内的商家。
一种简单直接的想法就是,将商家人均消费当做字符串写入倒排(如图所示),在进行区间查询时:1)遍历价格分词表,将落在此区间范围内的倒排id记录表找出来;2)合并倒排id记录表。这里两个步骤都存在性能问题:1)遍历价格分词表,比较暴力,而且通过term查找倒排id记录表次数过多,性能非常差,在lucene里查询次数过多,可能会抛出Too Many Boolean Clause的Exception。2)合并倒排id记录表非常耗时,说白了这些倒排id记录表都在磁盘里。
当然还有种思路就是将其数字长度补齐,假设所有商家的人均消费在[0,10000]这一区间内,我们存储1时写到倒排里就是00001(补齐为5位),由于分词表会按照字符串排序好,因此我们不必遍历价格分词表,通过二分查找能快速找到在某一区间范围内的倒排id记录表,但这里同样未能解决查询次数过多、合并倒排id记录表次数过多的问题。此外怎样补齐也是问题,补齐太多浪费空间,补齐太少存储不了太大范围值。
1.2 lucene解决方法
为解决这一问题, Schindler和 Diepenbroek提出了基于trie的解决方法,此方法08年发表在 Computers & Geosciences (地理信息科学sci期刊,影响因子1.9),也被lucene 2.9之后版本采用。( Schindler, U, Diepenbroek, M, 2008. Generic XML-based Framework for Metadata Portals. Computers & Geosciences 34 (12),论文:http://epic.awi.de/17813/1/Sch2007br.pdf)
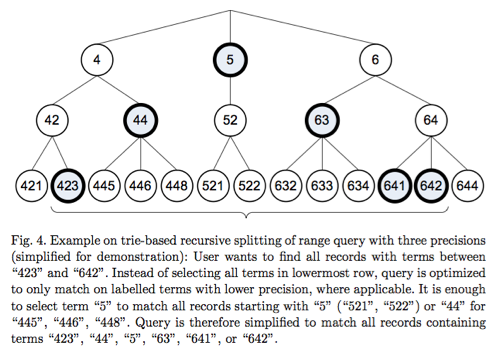
简单来说,整数423不是直接写入倒排,而是分割成几段写入倒排,以十进制分割为例,423将被分割为423、42、4这三个term写入, 本质上这些term形成了trie树(如图所示)。
如何查询呢?假设我们要查询[422, 642]这一区间范围的doc,首先在树的最底层找到第一个比422大的值,即423,之后查找423的右兄弟节点,发现没有便找其父节点的右兄弟(找到44),对于642也是,找其左兄弟节点(641),之后找父节点的左兄弟(63),一直找到两者的公共节点,最终找出423、44、5、63、641、642这6个term即可。通过这种方法,原先需要查询423、445、446、448、521、522、632、633、634、641、642这11次term对应的倒排id列表,并合并这11个term对应的倒排id列表,现在仅需要查询423、44、5、63、641、642这6个term对应的倒排id列表并合并,大大降低了查询次数以及合并次数,尤其是查询区间范围较大时效果更为明显。
这种优化方法本质上是一种以空间换时间的方法,可以看到term数目将增大许多。
在实际操作中,lucene将数字转换成2进制来处理,而且实际上这颗trie树也无需保存数据结构,传统trie一个节点会有指向孩子节点的指针, 同时会有指向父节点的指针,而在这里只要知道一个节点,其父节点、右兄弟节点都可以通过计算得到。此外lucene也提供了precisionstep这一字段用于设置分割长度,默认情况下int、double、float等数字类型precisionstep为4,就是按4位二进制进行分割。precisionstep长度设置得越短,分割的term越多,大范围查询速度也越快,precisionstep设置得越长,极端情况下设置为无穷大,那么不会进行trie分割,范围查询也没有优化效果,precisionstep长度需要结合自身业务进行优化。
1.3 索引文件大小优化方案
我们的应用中很多field都是数值类型,比如id、avescore(评价分)、price(价格)等等,但是用于区间范围查询的数值类型非常少,大部分都是直接查询或者为进行排序使用。
因此优化方法非常简单,将不需要使用范围查询的数字字段设置precisionstep为Intger.max,这样数字写入倒排仅存一个term,能极大降低term数量。

1 public final class CustomFieldType { 2 public static final FieldType INT_TYPE_NOT_STORED_NO_TIRE = new FieldType(); 3 static { 4 INT_TYPE_NOT_STORED_NO_TIRE.setIndexed(true); 5 INT_TYPE_NOT_STORED_NO_TIRE.setTokenized(true); 6 INT_TYPE_NOT_STORED_NO_TIRE.setOmitNorms(true); 7 INT_TYPE_NOT_STORED_NO_TIRE.setIndexOptions(FieldInfo.IndexOptions.DOCS_ONLY); 8 INT_TYPE_NOT_STORED_NO_TIRE.setNumericType(FieldType.NumericType.INT); 9 INT_TYPE_NOT_STORED_NO_TIRE.setNumericPrecisionStep(Integer.MAX_VALUE); 10 INT_TYPE_NOT_STORED_NO_TIRE.freeze(); 11 } 12 }
1.4 效果
优化之后效果明显,索引压缩包大小直接减少了一倍。
2 空间数据类型索引优化
.1 地理数据索引问题
还是一样的话,lucene基于倒排索引,非常适合文本,而对于空间类型数据却不是强项。
举个应用场景,每一个商家都有唯一的经纬度坐标(x, y),用户想筛选附近5千米的商家。
一种直观的想法是将经度x、维度y分别当做两个数值类型字段写到倒排里,然后查询的时候遍历所有的商家,计算与用户的距离,并保留小于5千米的商家。这种方法缺点很明显:1)需要遍历所有的商家,非常暴力;2)此外球面距离计算非涉及到大量的三角函数计算,效率较低(博主研发了一种快速距离计算方法,能提高至少10倍计算速度:地理空间距离计算优化)。
简单的优化方法使用矩形框对这些商家进行过滤,之后对过滤后的商家进行距离计算,保留小于5千米的商家,这种方法尽管极大降低了计算量,但还是需要遍历所有的商家。

2.2 lucene解决方法
lucene采用geohash的方法对经纬度进行编码(geohash介绍参见:GeoHash)。简单描述下,geohash对空间不断进行划分并对每一个划分子空间进行编码,比如我们整个北京地区被编码为“w”,那么再对北京一分为4,某一子空间编码为“WX”,对“WX”子空间再进行划分,对各个子空间再进行标识,例如“WX4”(简单可以这么理解)。
那么一个经纬度(x,y)怎样写入到倒排索引呢?假设某一经纬度落在“WX4”子空间内,那么经纬度将以“W”、“WX”、“WX4”这三个term写入到倒排。
如何进行附近查询呢?首先将我们附近5km划分一个个格子,每个格子有geohash的编码,将这些编码当做查询term,去倒排查询即可,比如附近5km的geohash格子对应的编码是“WX4”,那么直接就能将落在此空间范围的商家找出。

2.3 索引文件大小优化方案
上述方法本质上也是一种以空间换时间的方法,比如一个经纬度(x,y),只有两个字段,但是以geohash进行编码将产生许多term并写入倒排。
lucene默认最长的geohash长度为24,也就是一个经纬度将以24个字符串的形式来写入到倒排中。最初采用的geohash长度为11,但实际上针对我们的需求,geohash长度为9的时候已经足够满足我们的需求(geohash长度为9大约代表了5*4米的格子)。
下表表示geohash长度对应的精度,摘自维基百科:http://en.wikipedia.org/wiki/Geohash
|
geohash length
|
lat bits
|
lng bits
|
lat error
|
lng error
|
km error
|
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ± 2.8 | ± 5.6 | ±630 |
| 3 | 7 | 8 | ± 0.70 | ± 0.7 | ±78 |
| 4 | 10 | 10 | ± 0.087 | ± 0.18 | ±20 |
| 5 | 12 | 13 | ± 0.022 | ± 0.022 | ±2.4 |
| 6 | 15 | 15 | ± 0.0027 | ± 0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.000085 | ±0.00017 | ±0.019 |
1 private void spatialInit() { 2 this.ctx = SpatialContext.GEO; // 选择geo表示经纬度坐标,会按照球面计算距离,否则是平面欧式距离 3 int maxLevels = 9; // geohash长度为9表示5*5米的格子,长度过长会造成查询匹配开销 4 SpatialPrefixTree grid = new GeohashPrefixTree(ctx, maxLevels); // geohash字符串匹配树 5 this.strategy = new RecursivePrefixTreeStrategy(grid, "poi"); // 递归匹配 6 }
2.4 效果
此优化效果结果未做记录,不过经纬度geohash编码占据了term数量的25%,而我们又将geohash长度从11减少到9(降低18%),相当于整个term数量降低了25%*18%=4.5%。
3 只索引不存储
上面两种方法本质上通过减少term数量来减少索引文件大小,下面的方法走的是另一种方式。
从lucene查出一堆docid之后,需要通过docid找出相应的document,并找出里面一些需要的字段,例如id,人均消费等等,然后返回给客户端。但实际上我们只需要获取id,通过这些id再去请求DB/Cache获取额外的字段。
因此优化方法是只存储id等必须的字段,对于大部分字段我们只索引而不存储,通过这种方法,索引压缩文件降低了10%左右。
1 doc.add(new StringField("price", each, Field.Store.NO));
4 小结
本文基于lucene的一些基础原理以及自身业务,对索引文件大小进行了优化,使得索引文件大小下降了一半多。
检索实践文章系列: