GTC 2024 火线评论:DPU 重构文件存储访问_dpu分布式存储-程序员宅基地
技术标签: 云计算
编者按:英伟达2024 GTC 大会上周在美国加州召开,星辰天合 CTO 王豪迈在大会现场参与了 GPU 与存储相关的最新技术讨论,继上一篇《GTC 2024 火线评论:GPU 的高效存储利用》之后,这是他发回的第二篇评论文章。
上一篇文章已经提到,随着 AI 集群规模的提升,数据集的大幅增长,势必要面对集群资源的高效利用和安全问题,其中关键之一就是计算资源对于共享资源(如共享文件存储)的安全访问和保护。相比于传统 CPU 集群的共享存储和安全访问,GPU 集群在面对类似问题的挑战是安全+性能。安全访问并不能牺牲性能,特别是在当下刚发布的新一代 GPU 算力和网络平台下,存储带宽面对进一步提高的要求,吃紧的内存带宽和网络传输将进一步承压。

高性能存储安全访问的挑战
在讨论安全问题前,可能还要先牵扯算力集群和存储的网络方案。
众所周知,Nvidia 在 AI 数据中心推崇两个概念,一个是 AI Factory,另一个是 AI Cloud,前者类似于超级计算机的概念,适合单应用场景并推荐 Infiniband 组网方案,后者面临多租户和多样化的计算任务,因此推荐以太网方案。在这个分类下,我们会将以上存储安全访问问题缩小到更广泛 AI Cloud 场景上,因为这类场景相比而言,更急迫的需要解决。 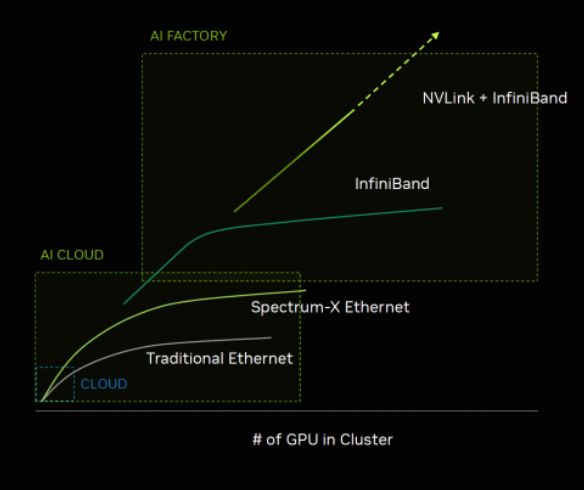
特别是,在当下 GPU 芯片昂贵成本下,即使在非 GPU 虚拟化场景,算力共享和灵活调度都是降低 AI 任务成本的重要手段,但算力平台如何向用户提供安全的数据访问和隔离手段是其中的重中之重。 因此,AI 算力集群需要在 足够性能 下解决控制面和数据面的安全访问挑战:
- 控制面路径的关键操作安全性:管理和配置网络、系统的操作,权限和策略的分配,漏洞和安全缺陷管理等等
数据面的授权访问和外部攻击:数据泄漏、篡改、服务拒绝等攻击
DPU 作为存储访问的信任代理
在以太网组网的 AI Cloud 场景下,Nvidia 提出了引入 DPU 方案来解决上述问题,通过 DPU 提供的代理访问来隔离非信任的主机和可信基础设施,确保 AI Cloud 的数据安全。
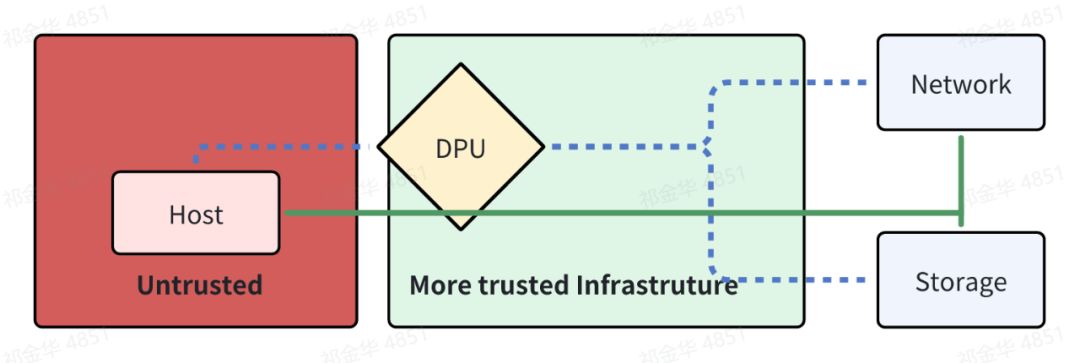
DPU 是一种专用硬件加速器,通常包含 CPU、内存和网络接口,能够在不增加主机侧处理器负担的情况下,执行数据处理任务,包括 Nvidia、Intel、AMD、Marvell 在内的芯片厂商都推出了 DPU 产品。DPU 在安全性上通常可以带来几个好处:
隔离和专用处理能力:DPU 可以作为一个隔离层,将存储和网络操作与主机的 CPU 分离开。这意味着即使主机受到安全威胁,攻击者也难以直接接触到数据传输和存储操作。
减少攻击面:DPU 可以控制访问存储资源的路径,允许更精细的访问控制策略,并且限制了潜在的攻击向量。由于主 CPU 不直接处理数据流,攻击者需先破坏 DPU,才能对数据进行篡改或未授权访问,这大大增加了攻击难度。
内置安全功能:许多 DPU 都配备了加密和其他安全功能,如内联数据加密、秘密保护和防火墙服务。这些功能可以在硬件层面提供保护,而不是依赖于可能被破坏的软件。
细粒度的控制:DPU 可以实现对数据访问的精细管理,包括访问控制、监控和日志记录,使系统管理员能够更好地监控和响应安全事件。
提供零信任架构:在 DPU 代理的帮助下,可以实施零信任安全模型,它假定内部网络也不可信,需要严格验证所有请求,这增强了对潜在内部威胁。
值得一提的是:在 Nvidia 发布的《下一代 AI 的新一代网络》白皮书中,提到在 400/800Gb 的网络中,即使无损网络环境中,都很难避免在 AI 的突发流量中性能不受影响。因此在以太网路线上,业界会期望借助于 DPU 算力来实现 RDMA 的拥塞控制,而不是依赖交换机或者 ECN 机制。因此 DPU 可能会是超高以太网网络的必需。
回到计算节点的 GPU 应用对于文件存储访问这个问题,存储客户端目前主要有两种选择:
- 用户态客户端:cuFile(GDS)/S3/SQL/..
内核态客户端:Posix/VFS
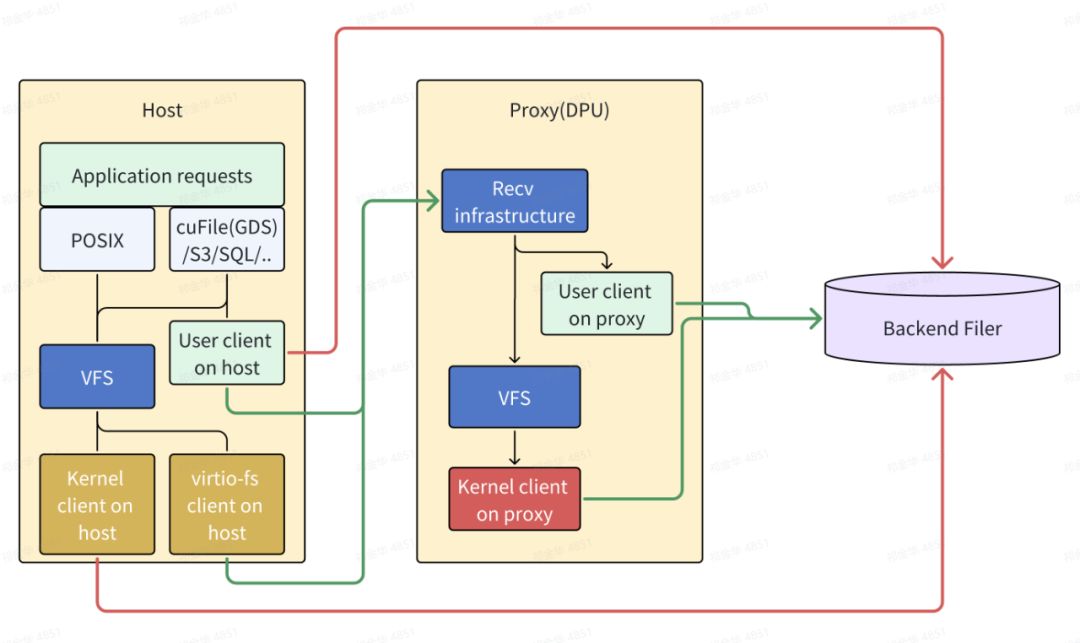
而引入 DPU 来实现安全访问,可以利用业界已有的虚拟化场景的文件协议实现 virtio-fs,virtio-fs 已经有长达十年的发展历程,它可以在这里提供从 Host 到 DPU 的文件代理通道,使得文件存储客户端可以完全运行于 DPU 操作系统。这样的变化,可以用下图来更清晰展示,其中红色的访问路径表示不安全的,绿色表示通过 DPU 的代理访问:
零拷贝问题
从技术角度来讲,引入额外的 DPU 来实现文件存储访问肯定带来额外开销,具体来说有这两个问题:
客户端缓存:在 AI 高性能的存储场景,客户端的内存缓存是必备选择,在当前的大部分 AI 任务中,对于存储的访问成本相对计算延迟仍然较高,缓存命中率非常关键,上一篇提到的 SCADA 实际上就是希望在中间建立通用的框架。但就目前而言,数据在计算节点上的缓存主要由存储客户端提供,例如 GPFS 在内核态实现了自有的缓存机制,Lustre 则更多依赖于 Linux Page Cache 机制。如果将存储客户端运行在 DPU 后,之前 Host 侧 CPU/GPU 的庞大内存也无法被数据缓存利用,DPU 内置的内存相对较小,则势必导致缓存命中率降低,性能大幅下降。因此,DPU 代理方案需要进一步解决该问题。
额外的拷贝成本:在客户端直接访问存储的路径中,通常采用 RDMA 来实现数据零拷贝。增加 DPU 代理访问后,会增加一次 Host 内存到 DPU 的拷贝。

DOCA SNAP virtio-fs
DPU Secure Storage Zero Copy 会通过 DOCA virtfs-fs SDK 来交付,过去 DOCA 已经提供了 SNAP NVME 能力,即可以通过 DPU 来实现 NVMe over Fabric 的卸载,DOCA SNAP virtfs 会成为新的文件存储访问卸载能力。
DPU 中的 VirtioFS 服务会基于 SPDK(https://spdk.io/) 开发,提供面向不同的文件存储供应商实现统一的抽象,运行在 DPU 中,面向 Host 的 virtio-fs 内核驱动承接请求,并为不同供应商的文件存储客户端根据需要去执行对应请求,未来文件存储供应商可以通过以下方式对接:
用户态文件客户端:如果文件存储直接支持用户态的文件客户端库,SNAP virtio-fs 可以直接通过库链接方式集成使用。
NFS over RDMA:如果文件存储提供标准的 NFS over RDMA 支持,则 SNAP virtio-fs 会直接通过 DPU OS 的 NFS 内核客户端访问,DPU OS 中的 NFS 内核客户端会修改来支持零拷贝。
内核态文件客户端:如果文件存储支持内核态客户端,则可以在 DPU OS 上安装,SNAP virtio-fs 可以执行 POSIX 调用。从 DPU OS Kernel 可以支持将 mkey 传递给 POSIX read()/write() 实现零拷贝。
目前 DPU Secure Storage 项目也需要得到文件存储厂商和 Linux Upstream 的支持,文件存储厂商需要尽快考虑将存储客户端迁移到合适的 DPU 运行环境,并作为 SPDK virtio-fs 的后端,为了实现零拷贝,需要能够支持利用 SPDK 的 memory domain API 来获得 mkey 对应的 Host 内存空间。而为了在 Host OS 上需要进一步加强 virtio-fs 的性能,比如实现多队列能力,支持 GPU 内存等。
XSKY 参与情况
对于国内领先的分布式存储厂商来说,我们同样认为,不仅是 Nvidia BlueField 系列产品可以提供这样的方式,这样的需求应该可以在普遍的 DPU 产品中实现并被利用,有效的提高 DPU 在存储协议上的多样化支持,并带来共享文件存储的安全性所需。
我们也会尽快评估在基于新一代全共享架构(XSEA)的全闪存文件存储,提供面向 AI Cloud 场景的 DPU 访问客户端能力,拥抱快速变化的 AI 基础设施进化。在多样化的 GPU 存储类型的利用上,不管是块存储的 NVMe 卷作为节点内的高速缓存,还是共享文件存储作为 CPU/GPU 内存的全局缓存存储,最终通过基于对象存储的数据湖来统一治理,这些存储类型的需求和定位都跟 XSKY 的产品定位和路线图高度符合。
智能推荐
vs2010 语法错误: 缺少“;”(在标识符“PVOID64”的前面)-程序员宅基地
文章浏览阅读1.6k次。网上有很多答案,看了让人不知道在说什么,一个行之有效的解决方案是在“stdafx.h”中添加#define POINTER_64 __ptr64。已验证有效。缺点是每生成一个新项目,都要添加一次。_vs2010 语法错误: 缺少“;”(在标识符“pvoid64”的前面)
leetcode sql题目_leedcode sql-程序员宅基地
文章浏览阅读392次。1 # Write your MySQL query statement belowselect max(salary) as SecondHighestSalary from Employee where salary not in (select max(salary) from Employee )Write a SQL query to get the second hig_leedcode sql
嵌入式软件工程师笔试面试指南-ARM体系与架构_嵌入式工程师笔试面试指南-程序员宅基地
文章浏览阅读1.1w次,点赞74次,收藏324次。嵌入式软件笔试,嵌入式软件面试,程序员简历书写,Linux驱动工程师笔试,Linux驱动工程师面试,BSP工程师笔试,BSP工程师面试,应届生秋招,应届生春招,C/C++笔试题目,C/C++面试题目,C/C++程序员,BSP工程师_嵌入式工程师笔试面试指南
威佐夫博弈 hdu1527 取石子游戏_博弈 分割石子-程序员宅基地
文章浏览阅读800次。传送门:点击打开链接题意:轮流取石子。1.在一堆中取任意个数.2.在两堆中取相同个数。最后取完的人胜利,问先手是否必赢思路:威佐夫博弈博弈,满足黄金分割,且每个数字只会出现一次。具体求法见代码#include#include#include#include#include#include#include#include#include#include#include_博弈 分割石子
python控制蓝牙音响_[ESP32+MicroPython]智能音响控制-程序员宅基地
文章浏览阅读2k次。blinker支持多种智能音响控制,如天猫精灵、百度小度、小米小爱、京东叮咚等。这里以天猫精灵控制为例,blinker DIY支持将设备模拟成三种类型的智能家居:插座、灯、传感器。Blinker支持多种语音助手控制,如天猫精灵、百度小度,本节以天猫精灵控制为例。示例程序及blinker模块天猫精灵基本接入方法通常语音助手都是对特定的设备类型进行支持,确定设备类型后,才能响应对应的语音指令。使用bl..._blinker支持micpython么
C程序设计(第五版)第6章 利用数组处理批量数据-程序员宅基地
文章浏览阅读7.4k次。
随便推点
Redis实现延迟队列方法介绍-程序员宅基地
文章浏览阅读3.3k次。其中,延迟队列是 Redis 的一个重要应用场景,它被广泛应用于异步任务的调度、消息队列的实现以及秒杀、抢购等高并发场景的处理。在实现延迟队列时,我们可以使用 Redis 的有序集合来保存待执行的任务,其中元素的分值表示任务的执行时间,元素的值表示任务的内容。使用 ZADD 命令将任务添加到有序集合中,将任务的执行时间作为元素的分值,将任务的内容作为元素的值。使用 ZADD 命令将任务添加到有序集合中,将任务的执行时间作为元素的分值,将任务的内容作为元素的值。一、Redis 有序集合实现延迟队列。
Python入门实战:Python的文件操作-程序员宅基地
文章浏览阅读701次,点赞23次,收藏7次。1.背景介绍Python是一种强大的编程语言,它具有简洁的语法和易于学习。Python的文件操作是一种常用的编程技术,可以让程序员更方便地读取和写入文件。在本文中,我们将深入探讨Python的文件操作,涵盖了核心概念、算法原理、具体操作步骤、数学模型公式、代码实例以及未来发展趋势。1.1 Python的文件操作背景Python的文件操作是一种基本的编程技能,它允许程序员在程序中读取和写...
机器学习模型对比_机器学习的模型比较-程序员宅基地
文章浏览阅读1k次。1.SVM和LR(逻辑回归)1.1 相同点都是线性分类器。本质上都是求一个最佳分类超平面。都是监督学习算法。 都是判别模型。通过决策函数,判别输入特征之间的差别来进行分类。常见的判别模型有:KNN、SVM、LR。 常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。1.2 不同点损失函数不同,LR的损失函数为交叉熵;svm的损失函数自带正则化,而LR需要在损失函数的基础上加上正则化。 两个模型对数据和参数的敏感程度不同。SVM算法中仅支持向量起作用,大部分样本的增减对模型无影响;而L_机器学习的模型比较
纯C语言完整代码操作单链表(初始化、插入、删除、查找...)-程序员宅基地
文章浏览阅读901次,点赞3次,收藏10次。C语言操作单链表
实战打靶集锦-027-SoSimple1_sosimple 写入试验场-程序员宅基地
文章浏览阅读1.6k次,点赞32次,收藏47次。本文简单记录了博主的一次打靶经历,涉及wordpress扫描与爆破、social-warfare远程代码执行漏洞、sudo命令提权等_sosimple 写入试验场
用opencv的dnn模块做yolov5目标检测_opencv yolov5-程序员宅基地
文章浏览阅读7w次,点赞271次,收藏1.1k次。最近在微信公众号里看到多篇讲解yolov5在openvino部署做目标检测文章,但是没看到过用opencv的dnn模块做yolov5目标检测的。于是,我就想着编写一套用opencv的dnn模块做yolov5目标检测的程序。在编写这套程序时,遇到的bug和解决办法,在这篇文章里讲述一下。在yolov5之前的yolov3和yolov4的官方代码都是基于darknet框架的实现的,因此opencv的dnn模块做目标检测时,读取的是.cfg和.weight文件,那时候编写程序很顺畅,没有遇到bug。但是yolo_opencv yolov5