有Mysql数据库的情况下为什么要用Hive数据库?-程序员宅基地
有Mysql数据库的情况下为什么要用Hive?
最近接到公司的一个需求,要求使用Hive做数据查询。当时第一反应就是What?Hive是什么鬼?一脸懵逼状。(请原谅一个刚开始实习的Java实习生见识短浅)然后发现了hive的一些问题。下面简单介绍一下Hive。
网上对于hive与mysql的区别的文章也不是很多。so只能问问公司大牛们,看看他们是怎样理解的。
由于 Hive 采用了 SQL 的查询语言 HQL,因此很容易将 Hive 理解为数据库。其实 从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
一、Hive是一个基于Hadoop的数据仓库平台。通过hive,我们可以方便地进行ETL的工作。hive定义了一个类似于SQL的查询语言:HQL,能 够将用户编写的QL转化为相应的Mapreduce程序基于Hadoop执行。
Hive是Facebook 2008年8月刚开源的一个数据仓库框架,其系统目标与 Pig 有相似之处,但它有一些Pig目前还不支持的机制,比如:更丰富的类型系统、更类似SQL的查询语言、Table/Partition元数据的持久化等。
Hive 可以看成是从SQL到Map-Reduce的 映射器
Hive的数据放在哪儿?
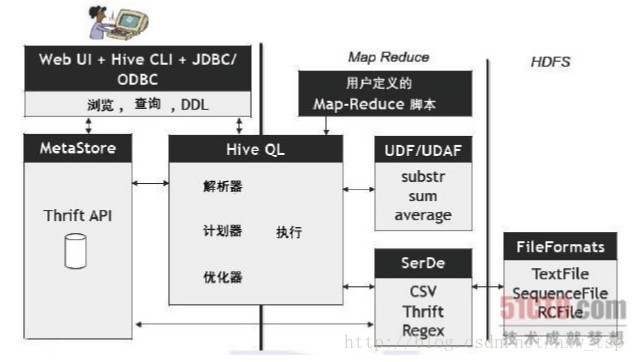
数据在HDFS的warehouse目录下,一个表对应一个子目录。
本地的/tmp目录存放日志和执行计划
hive的表分为两种,内表和外表。
Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
使用Mysql作为Hive metaStore的存储数据库
其中主要涉及到的表如下:
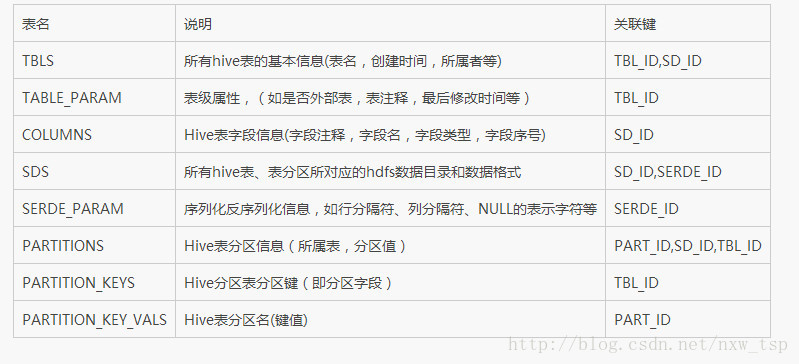
但是对于一个菜鸟来说,看完这些还是有点云里雾里。
下面来看他们的异同。
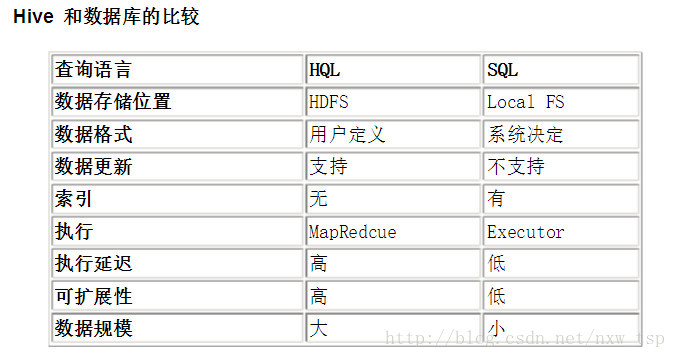
查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库 则可以将数据保存在本地文件系统中。
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三 个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不 支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描, 因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的(类似 select * from tbl 的查询不需要 MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外 一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是 一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的 数据;对应的,数据库可以支持的数据规模较小。
看了这些,我说为什么hive查询数据怎么这么慢呢。
最后再来一下数据库和数据仓储的区别。
> 数据库是面向事务的设计,数据仓库是面向主题设计的。 数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
> 数据库设计是尽量避免冗余,一般采用符合范式的规则来设计,数据仓库在设计是有意引入冗余,采用反范式的方式来设计。
> 数据库是为捕获数据而设计,数据仓库是为分析数据而设计,它的两个基本的元素是维表和事实表。(维是看问题的角度,比如时间,部门,维表放的就是这些东西的定义,事实表里放着要查询的数据,同时有维的ID)
以上文章部分内容来自与网络。
智能推荐
计算机就业方向-程序员宅基地
文章浏览阅读6.8k次,点赞5次,收藏12次。希望看到这篇文章的学计算机、软件的同学可以互相转载,让大家都知道我们以后的道路是怎样的。有了方向,干什么都有动力,不是吗?(有点长,希望大家先分享,以后慢慢看,有用没用,我说了不算,你看看就知道了!)计算机专业就业方向一、 关于企业计算方向企业计算(Enterprise Computing)是稍时髦较好听的名词,主要是 指企业信息系统,如ERP软件(企业资源规划)、CRM软件(客户关系_计算机就业
基于Java在线电影票购买系统设计实现(源码+lw+部署文档+讲解等)-程序员宅基地
文章浏览阅读4.1k次,点赞2次,收藏4次。社会和科技的不断进步带来更便利的生活,计算机技术也越来越平民化。二十一世纪是数据时代,各种信息经过统计分析都可以得到想要的结果,所以也可以更好的为人们工作、生活服务。电影是生活娱乐的一部分,特别对喜欢看电影的用户来说是非常重要的事情。把计算机技术和影院售票相结合可以更符合现代、用户的要求,实现更为方便的购买电影票的方式。本基于Java Web的在线电影票购买系统采用Java语言和Vue技术,框架采用SSM,搭配MySQL数据库,运行在Idea里。
集合的addAll方法--list.addAll(null)会报错--java.lang.NullPointerException-程序员宅基地
文章浏览阅读1.8k次。Exception in thread "main" java.lang.NullPointerException at java.util.ArrayList.addAll(ArrayList.java:559) at com.iflytek.epdcloud.recruit.utils.quartz.Acool.main(Acool.java:16)import java.u..._addall(null)
java获取当天0点到24点的时间戳,获得当前分钟开始结束时间戳_java 获取某分钟的起止时间戳-程序员宅基地
文章浏览阅读4.5k次。public static void main(String[] args) { Calendar todayStart = Calendar.getInstance(); todayStart.set(Calendar.HOUR_OF_DAY, 0); todayStart.set(Calendar.MINUTE, 0); toda..._java 获取某分钟的起止时间戳
北京内推 | 京东AI研究院计算机视觉实验室招聘三维视觉算法研究型实习生-程序员宅基地
文章浏览阅读1.1k次。合适的工作难找?最新的招聘信息也不知道?AI 求职为大家精选人工智能领域最新鲜的招聘信息,助你先人一步投递,快人一步入职!京东 AI 研究院京东 AI 研究院(https://air.jd..._京东计算机视觉实验室
Ubuntu18.04安装配置Qt5.15_ubuntu安装qt5.15-程序员宅基地
文章浏览阅读2.1k次。Ubuntu18.04安装配置Qt5.15 Ubuntu18.04安装配置Qt5.15 Qt选择下载Qt安装Qt5.15.0配置后记 Qt选择 在官方的声明中,Qt5.15是Qt5.x的最后一个LTS版本,增加了即将在2020年底推出的Qt6的部分新特性,为了之后的新_ubuntu安装qt5.15
随便推点
卷积神经网络模型可视化生成热力图_卷积热力图-程序员宅基地
文章浏览阅读2.3k次。使用Grad-CAM++[51]方法对训练好的卷积神经网络模型进行可视化操作生成热力图以查看响应区域。可视化结果如图3.8所示。其中baseline和 ATN可视化需要的权重来自于分类结果对最后一层卷积层提取的特征进行求导。图3.8中共有4组图像,每组图像从左往右依次为原图,根据baseline权重生成的热力图和根据本章提出的ATN网络权重生成的热力图。热力图的红色越深,则表示该部分的权重越高。从生成的热力图可以看到,baseline 生成的热力图中,虽然在人体区域都有响应,但是背景噪声部分的响应权重也_卷积热力图
网络安全实验---防火墙实验-程序员宅基地
文章浏览阅读2w次,点赞13次,收藏82次。文章目录一、实验目的:二、实验环境:三、实验内容:1. 安装天网防火墙2. 使用天网防火墙进行实验3.在上端的菜单栏最左边点击应用程序规则,点击下方需要修改应用的选项可以对其进行流量控制4.调节ip规则配置,将“允许自己ping探测其他机器”改为禁止,查看能否再次收到reply5.添加一条禁止邻居同学主机的FTP连接规则四、心得体会:五.软件共享一、实验目的:通过实验深入理解防火墙的功能和工作原理熟悉天网防火墙个人版的配置和使用二、实验环境:一台xp虚拟机和一台windows10虚拟机在xp上安_防火墙实验
vue项目运行报错:94% asset optimization ERROR Failed to compile with 2 errors13:03:01 error in ./src/ba-程序员宅基地
文章浏览阅读6.7k次。使用vue编写的前端项目运行报错:88% hashing 89% module assets processing 90% chunk assets processing 94% asset optimization ERROR Failed to compile with 2 errors13:03:01 error in ./src/base/components/head..._94% asset optimization
适用于 Linux 的 Windows 子系统安装指南 (Windows 10) (微软官方文档)_hyper-v-vmms 虚拟硬盘文件必须是未压缩和未加密的文件,并且不能是稀疏文件。-程序员宅基地
文章浏览阅读2.2k次,点赞2次,收藏3次。官方原文档微软官方教程地址:传送门安装适用于 Linux 的 Windows 子系统必须先启用“适用于 Linux 的 Windows 子系统”可选功能,然后才能在 Windows 上安装 Linux 分发版。以管理员身份打开 PowerShell 并运行:dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart安装所选的 Linux 分发版打开 Micro_hyper-v-vmms 虚拟硬盘文件必须是未压缩和未加密的文件,并且不能是稀疏文件。
rufus 一款好用的linux u盘,光盘刻录工具_rufus可以刻录光盘吗-程序员宅基地
文章浏览阅读2.2k次。rufus 一款好用的linux u盘,光盘刻录工具:下载(点击普通下载中的“立即下载”): http://share.cnop.net/file/1806028-401886318_rufus可以刻录光盘吗
用VB.net实现对.ini文件的读写操作的类-程序员宅基地
文章浏览阅读142次。Option Explicit OnModule INI 'INICont.bas Ver 1.0+a INI '==================================================================== 'GetIntFromINI( sectionName , keyName , defaultValue, iniPath ) '..._vb.net 读取ini文件 int