Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
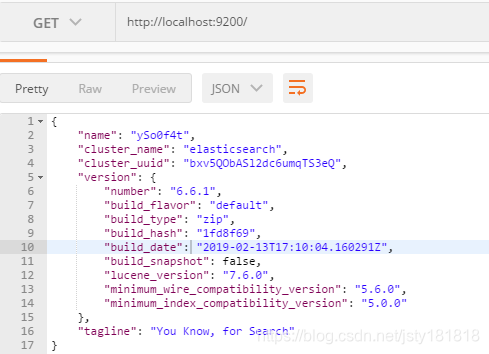
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
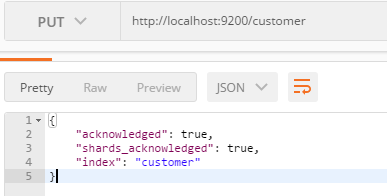
- 创建一个索引:(PUT)
http://localhost:9200/customer
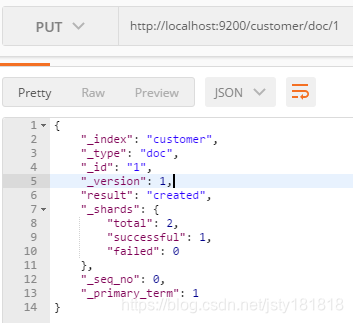
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
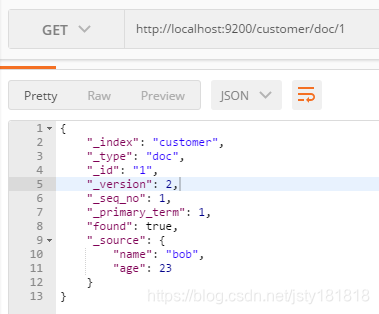
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
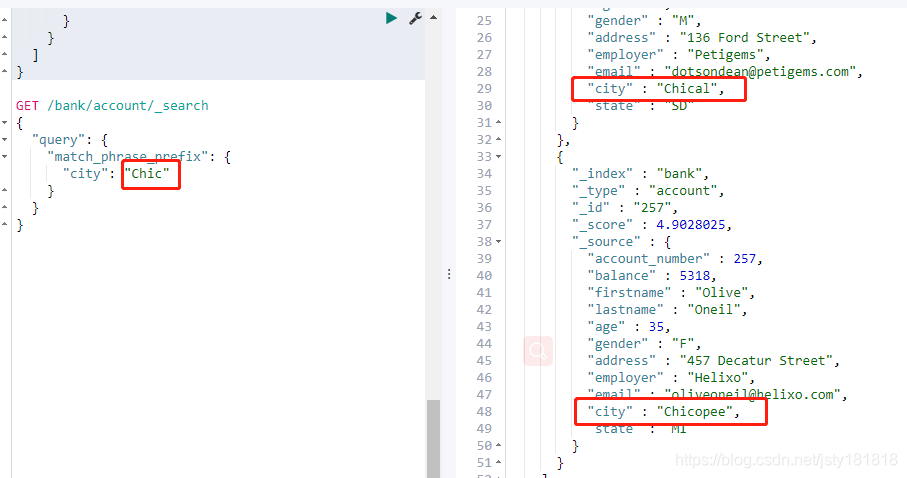
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
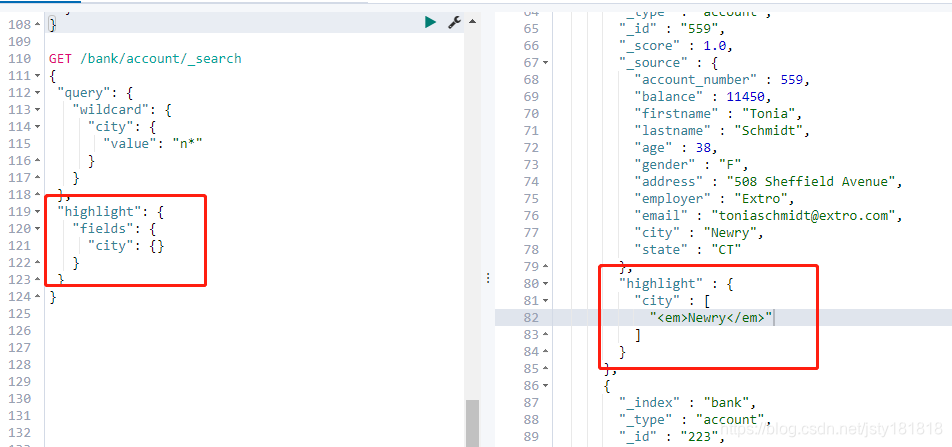
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
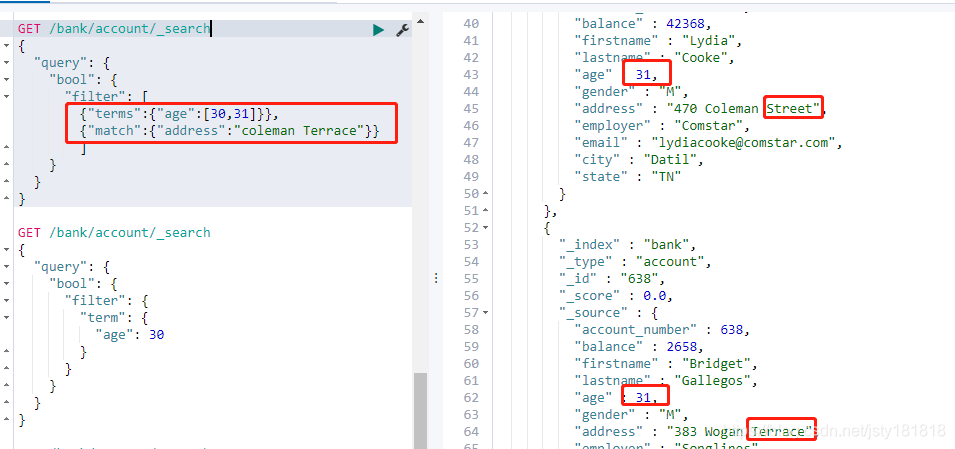
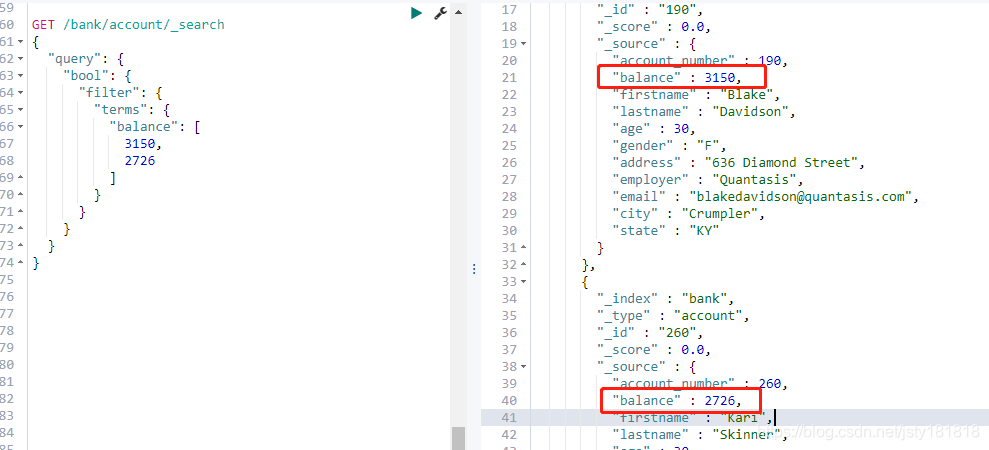
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
彻底扒光 通过智能路由器拆解看其本质-程序员宅基地
文章浏览阅读1.7k次。可以看到很多联发科的MT芯片摘自:https://net.zol.com.cn/531/5312999.html彻底扒光 通过智能路由器拆解看其本质2015-07-23 00:40:00[中关村在线 原创] 作者:陈赫|责编:白宁收藏文章 分享到 评论(24)关注智能路由器拆解的朋友们注意啦!我们已经将这五款产品彻底扒开,将主板的真容展现在了大家的眼前。网友们可以看见这些智能路由器主板的做工和用料,我们还为网友们展示了主要的电子元器件,供大家品评观赏。..._路由器拆解
Java--深入JDK和hotspot底层源码剖析Thread的run()、start()方法执行过程_jdk的源码hotspot跟jdk是分开的-程序员宅基地
文章浏览阅读2.1k次,点赞101次,收藏78次。【学习背景】今天主要是来了解Java线程Thread中的run()、start()两个方法的执行有哪些区别,会给出一个简单的测试代码样例,快速理解两者的区别,再从源码层面去追溯start()底层是如何最终调用Thread#run()方法的,个人觉得这样的学习不论对面试,还是实际编程来说都是比较有帮助的。进入正文~学习目录一、代码测试二、源码分析2.1 run()方法2.2 start()方法三、使用总结一、代码测试执行Thread的run()、start()方法的测试代码如下:public_jdk的源码hotspot跟jdk是分开的
透视俄乌网络战之一:数据擦除软件_俄乌网络战观察(一)-程序员宅基地
文章浏览阅读4.4k次,点赞90次,收藏85次。俄乌冲突中,各方势力通过数据擦除恶意软件破坏关键信息基础设施计算机的数据,达到深度致瘫的效果,同时窃取重要敏感信息。_俄乌网络战观察(一)
Maven私服仓库配置-Nexus详解_nexus maven-程序员宅基地
文章浏览阅读1.7w次,点赞23次,收藏139次。Maven 私服是一种特殊的Maven远程仓库,它是架设在局域网内的仓库服务,用来代理位于外部的远程仓库(中央仓库、其他远程公共仓库)。当然也并不是说私服只能建立在局域网,也有很多公司会直接把私服部署到公网,具体还是得看公司业务的性质是否是保密的等等,因为局域网的话只能在公司用,部署到公网的话员工在家里也可以办公使用。_nexus maven
基于AI的计算机视觉识别在Java项目中的使用 (四) —— 准备训练数据_java ocr ai识别训练-程序员宅基地
文章浏览阅读934次。我先用所有的样本数据对模型做几轮初步训练,让深度神经模型基本拟合(数万条记录的训练集,识别率到99%左右),具备初步的识别能力,这时的模型就是“直男”。相较于训练很多轮、拟合程度很高的“油腻男”,它的拟合程度较低,还是“直男愣头青”。..............._java ocr ai识别训练
hibernate 数据库类型 date没有时分秒解决_hibernate解析時間只有年月日沒有時分秒-程序员宅基地
文章浏览阅读688次。一、问题现象: 在数据库表中日期字段中存的日期光有年月日,没有时分秒。二、产生原因:三 解决办法 检查表的相应映射xml文件。 <property name="operateDate" type="Date">如果同上面所写,那问题出在 type类型上了正确写法 :<property name="operateDate" type="java.util..._hibernate解析時間只有年月日沒有時分秒
随便推点
springbbot运行无法编译成功,找不到jar包报错:Error:(3, 46) java: 程序包org.springframework.context.annotation不存在-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏2次。文章目录问题描述:解决方案:问题描述:提示:idea springbbot运行无法编译成功,找不到jar包报错E:\ideaProject\demokkkk\src\main\java\com\example\demo\config\WebSocketConfig.javaError:(3, 46) java: 程序包org.springframework.context.annotation不存在Error:(4, 46) java: 程序包org.springframework.conte_error:(3, 46) java: 程序包org.springframework.context.annotation不存在
react常见面试题_recate面试-程序员宅基地
文章浏览阅读6.4k次,点赞6次,收藏36次。1、redux中间件中间件提供第三方插件的模式,自定义拦截 action -> reducer 的过程。变为 action -> middlewares -> reducer 。这种机制可以让我们改变数据流,实现如异步 action ,action 过滤,日志输出,异常报告等功能。常见的中间件:redux-logger:提供日志输出redux-thunk:处理异步操作..._recate面试
交叉编译jpeglib遇到的问题-程序员宅基地
文章浏览阅读405次。由于要在开发板中加载libjpeg,不能使用gcc编译的库文件给以使用,需要自己配置使用另外的编译器编译该库文件。/usr/bin/ld:.libs/jaricom.o:RelocationsingenericELF(EM:40)/usr/bin/ld:.libs/jaricom.o:RelocationsingenericELF(EM:40)...._jpeg_utils.lo: relocations in generic elf (em: 8) error adding symbols: file
【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)-程序员宅基地
文章浏览阅读578次,点赞10次,收藏17次。【办公类-22-06】周计划系列(1)“信息窗” (2024年调整版本)
SEO优化_百度seo resetful-程序员宅基地
文章浏览阅读309次。SEO全称为Search Engine Optimization,中文解释为搜索引擎优化。一般指通过对网站内部调整优化及站外优化,使网站满足搜索引擎收录排名需求,在搜索引擎中提高关键词排名,从而把精准..._百度seo resetful
回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法-程序员宅基地
文章浏览阅读438次。回归预测 | Matlab实现HPO-ELM猎食者算法优化极限学习机的数据回归预测_猎食者优化算法