Python构建快速高效的中文文字识别OCR_中文ocr python-程序员宅基地
感谢李奥诃弗斯基的悉心教导完成编译部分工作,万分感谢!
本文使用开源项目chineseocr_lite,已上传百度网盘(2020/3/16),提取码:oade
以下适合Windows系统,需要使用VS进行简单编译,若用Linux系统可直接参考原项目,应该更简单。


安装
1. PyTorch
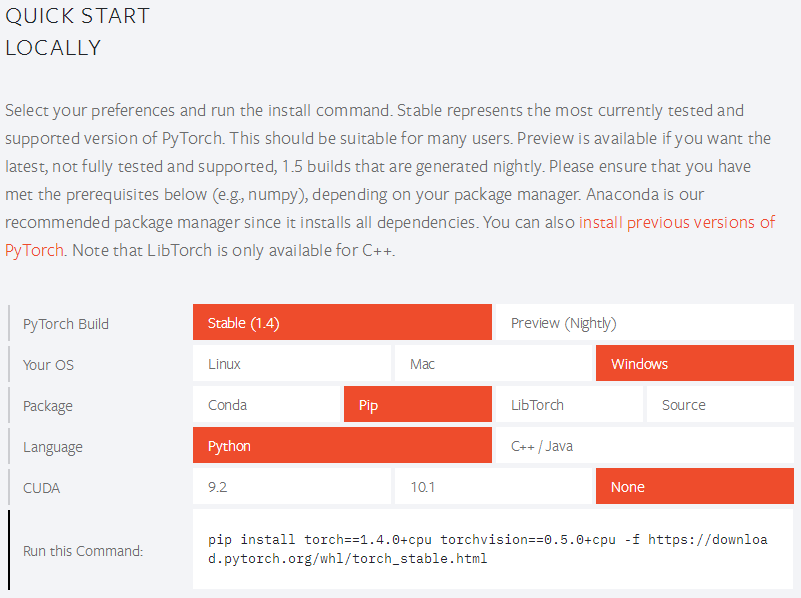
进入PyTorch官网,选择合适自己的版本。
如笔者使用pip且仅CPU环境,执行命令安装:pip install torch==1.4.0+cpu torchvision==0.5.0+cpu -f https://download.pytorch.org/whl/torch_stable.html
2. Python库
pip install web.py==0.40.dev0
3. VS2015及以上
必须装上VC++模块,用于后面编译。
编译PSENET
本人编译好的pse.pyd已上传CSDN,在Win7和Win10的Python3.6版本下测试通过,需要的亲自取。
这步是重头戏
1.打开VS2015→新建项目→Visual C++→项目命名为pse

2.勾上空项目
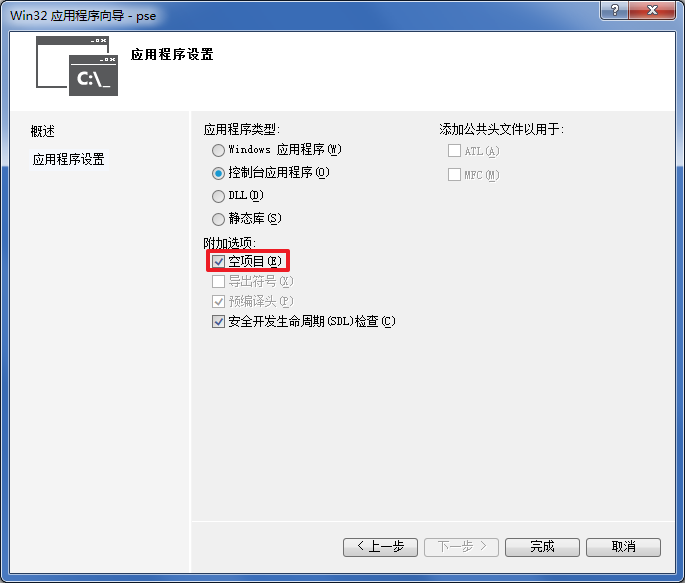
3.配置属性(常规):右键项目pse→属性→配置Release→平台x64→目标文件扩展名.pyd→配置类型动态库(.dll)

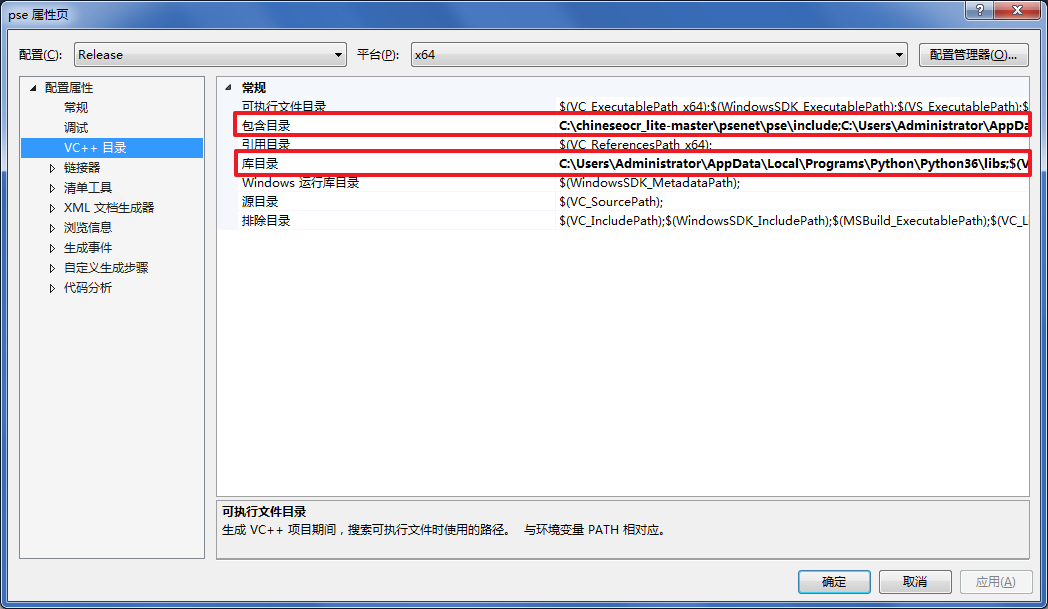
4.配置属性(VC++目录):包含目录添加C:\chineseocr_lite-master\psenet\pse\include(项目文件)和C:\Users\Administrator\AppData\Local\Programs\Python\Python36\include(你的Python),库目录添加C:\Users\Administrator\AppData\Local\Programs\Python\Python36\libs(注意,是libs不是Lib)
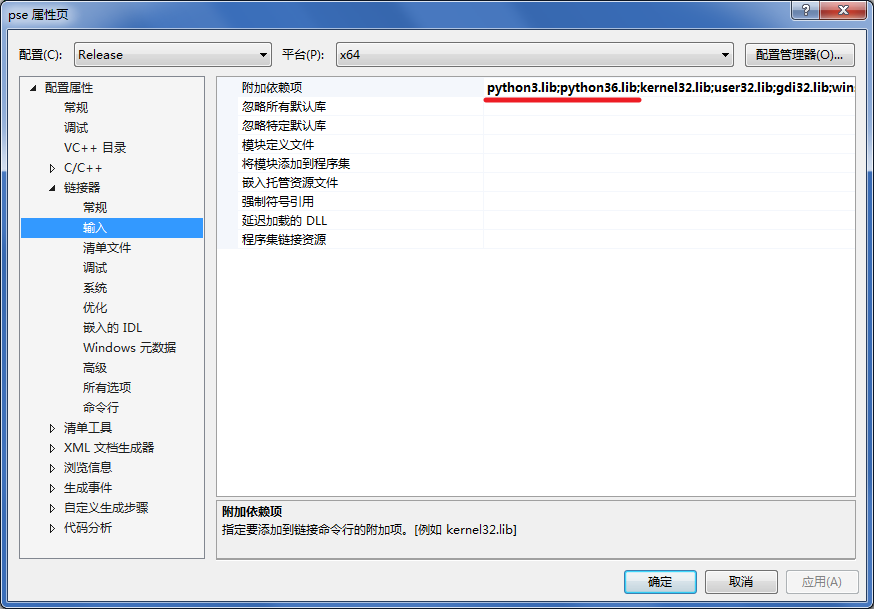
5.附加依赖项:添加python3.lib;python36.lib;
4.配置管理器→活动解决方案配置Release→活动解决方案平台x64

5.把项目\psenet\pse\pse.cpp复制到源文件里→右键项目pse→重新生成
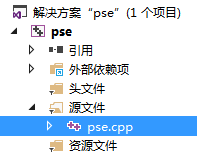
6.在VS项目pse\x64\Release就编译好了我们要的库文件pse.pyd
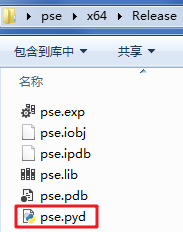
7.将pse.pyd复制到与项目\psenet\pse\pse.cpp同一文件夹下
运行app.py
访问http://127.0.0.1:8080/ocr
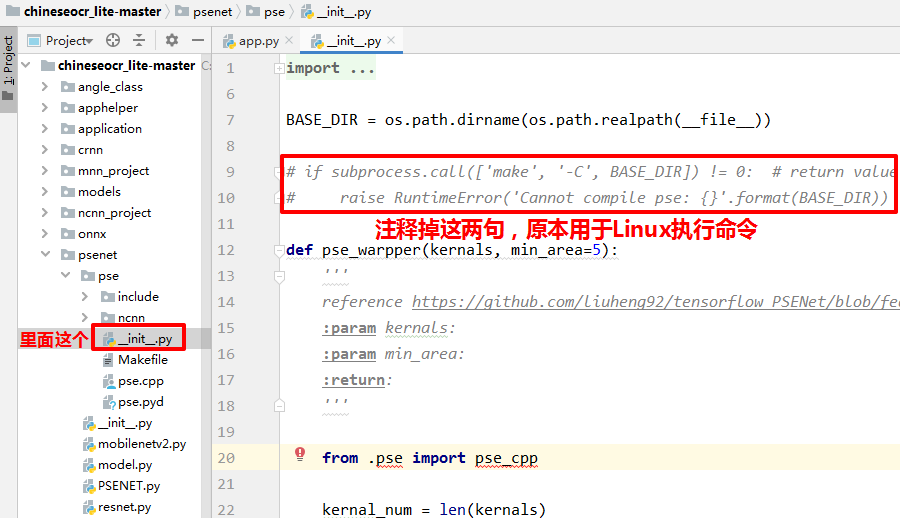
1.报错RuntimeError: Cannot compile pse: C:\chineseocr_lite-master\psenet\pse
注释掉psenet\pse\__init__.py的两行代码
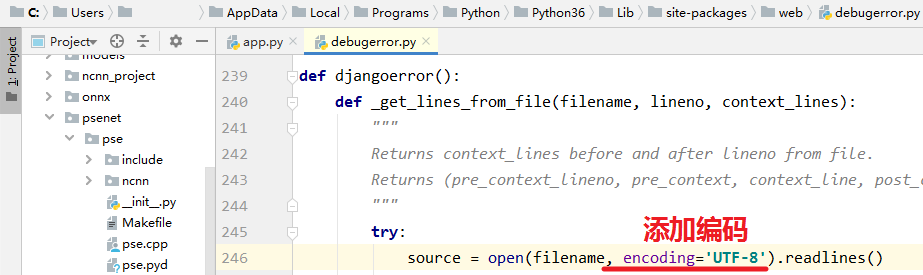
2.报错UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 551: illegal multibyte sequence
点进报错所在代码,添加编码, encoding='UTF-8'
3.报错UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xa7 in position 982: illegal multibyte sequence
同上,添加编码, encoding='UTF-8'
封装接口
原项目使用和未使用的文件较多,本人封装好了接口
GitHub自取:vba34520/chineseocr_lite: Python构建快速高效的中文文字识别OCR
调用ocr.result()即可进行文本预测

GPU版本
- 安装CUDA+cuDNN
- GPU版本PyTorch
- 执行命令
nvidia-smi查看GPU的ID - 修改config.py的GPU_ID
参考文献
智能推荐
“码农”一词是怎么来的?为什么中国程序员会被码农?程序员和农民有什么关联?-程序员宅基地
文章浏览阅读1.7w次。原创: 思齐大神 来源:蚁开源社区很多同学会问,IT行业在中国并不是特别差的行业,而程序员的工资也并不低,但为什么中国的程序员总被称作码农或者说是苦逼的程序员?中国的程序员生活和欧美的有什么不一样?先说两个小段子街边,一对情侣在吵架。女孩对男孩说,“我们分手吧!”男孩沉默半天,开口问道,“我能再说最后一句话吗?”“说吧,婆婆妈妈的。”“我会编程……”“会编程有个屁用啊,现在到处都是会编程的人!”男孩涨红了脸,接着说道,“我会编程……我会变成…童话里,你爱的那个天使……”【程序._码农
Java初学者也能看的懂的AQS_aqs对接-程序员宅基地
文章浏览阅读259次。Java初学者也能看的懂的AQS学习AQS之前,你需要了解以下内容,如果不是很清楚,那么理解本文会有点吃力。(Java初学者得会一下内容)synchronizedCASLock前言synchronized首先我们知道synchronized是Java关键字,上锁释放锁等一切操作都是由JVM控制的。我们只能通过虚拟机的C++才能去研究其底层实现。我们除了判断synchronized是作为方法的修饰符,还是当做同步代码块使用以外,没什么需要我们程序员操作的。cas一种自旋的原子操作,也是J_aqs对接
【JZOJ5262】【GDOI2018模拟8.12】树(DP,性质题)_gdoi2018省选模拟树-程序员宅基地
文章浏览阅读460次。DescriptionSolution首先我们可以知道两个性质:1、路径u-v和路径v-w可以合并为路径u-w;2、路径u1-v1加路径u2-v2和路径u1-v2加路径u2-v1是等价的(就是起始点和终点可以互换) 那么知道这些性质之后就很好做了。我们只用知道每个点多少次做起点和多少次做终点。 我们设f[i]表示满足i子树的需求i上的值要是多少。 那么枚举i的所有儿子,判断a[i]-f[i],_gdoi2018省选模拟树
[PTA]7-65 字符串替换 (15 分)含思路_字符串替换pta-程序员宅基地
文章浏览阅读2.8k次,点赞4次,收藏28次。我们进行简单的运算即可实现倒序。_字符串替换pta
linux网络设置_linux如何开启网络连接-程序员宅基地
文章浏览阅读4k次,点赞5次,收藏22次。traceroute 180.101.50.188————————测试到180.101.50.188有多少个网关。vim /etc/sysconfig/static-routes——————————修改。netstat -antp | grep 22———————查看端口号22的相关信息。systemctl restart network————————————重启。systemctl restart network————————重新启动。_linux如何开启网络连接
pr中,视频导入后,视频画面大小显示不完整应该如何解决?_avi视频到pr里会放大-程序员宅基地
文章浏览阅读4w次,点赞23次,收藏6次。本人pr小白,今天编辑视频时候遇到了问题,也解决了,所以分享记录一下。问题一视频下面原来有字幕的,可是导入的视频变大了,现在看不到了怎么办?还有就是,频导入之后画质好像变糊了又是为什么?解决:将箭头放到要编辑的视频那里,右击,然后点击设为帧大小这样完整的视频就出来了。问题二如果视频模糊,就是序列设置的不对 要先新建序列一般的都是1920×1080本人博客:https://blog.csdn.net/weixin_46654114本人b站求关注:https://space.bi_avi视频到pr里会放大
随便推点
SeetaFace2 Android 平台编译_seetafacerecognizer2.0.ats-程序员宅基地
文章浏览阅读4.1k次。SeetaFace2 Android 平台编译项目地址:https://github.com/seetafaceengine/SeetaFace2SeetaFace2 人脸识别引擎包括了搭建一套全自动人脸识别系统所需的三个核心模块,即:人脸检测模块 FaceDetector、面部关键点定位模块 FaceLandmarker 以及人脸特征提取与比对模块 FaceRecognizer。面部关键点定位支持 5 点 和 81 点定位,两个辅助模块 FaceTracker 和 QualityAssessor 用_seetafacerecognizer2.0.ats
Oracle删除约束和主键的语句_oracle删除主键的sql语句-程序员宅基地
文章浏览阅读3.2w次,点赞4次,收藏34次。1.删除约束语句:alter table 表名 drop constraint 约束名;alter table mz_sf4 drop constraint pk_id1;2.删除主键语句:alter table 表名 drop primary key;alter table mz_sf3 drop primary key;如果出错:ORA-02273:此唯一主键已_oracle删除主键的sql语句
MySQL~InnoDB的备份和主从复制-程序员宅基地
文章浏览阅读989次,点赞9次,收藏13次。这份面试题几乎包含了他在一年内遇到的所有面试题以及答案,甚至包括面试中的细节对话以及语录,可谓是细节到极致,甚至简历优化和怎么投简历更容易得到面试机会也包括在内!也包括教你怎么去获得一些大厂,比如阿里,腾讯的内推名额!某位名人说过成功是靠99%的汗水和1%的机遇得到的,而你想获得那1%的机遇你首先就得付出99%的汗水!你只有朝着你的目标一步一步坚持不懈的走下去你才能有机会获得成功!成功只会留给那些有准备的人!《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》点击传送门即可获取。
大数据平台核心技术 学堂在线 雨课堂 第八讲作业答案 人文交流月_vertectorization-程序员宅基地
文章浏览阅读2k次。关于Vertectorization哪些是正确的( )相对于其他编程模型,sql在大数据领域有哪些好处( )哪些部分适合做codegen( )关于内存计算描述不正确的有( )_vertectorization
java汉字拼音简码_java生成首字母拼音简码的总结-程序员宅基地
文章浏览阅读306次。百度找到了某论坛高人写的java(具体论坛记不清了),直接用来调用,再次非常感谢,基本上实现了我的需求package MD5;import java.util.Scanner;public class ChineseToPinYin {/*** 汉字转拼音缩写** @param str* 要转换的汉字字符串* @return String 拼音缩写*/public Strin..._java生成拼音码
C++ 数据结构——堆排序_数据结构堆排序c++-程序员宅基地
文章浏览阅读93次。/* 堆排序 */#include <iostream>using namespace std;int *data;void Sift(int k,int last){ int i,j,temp; i=k;j=2*i+1; while (j<=last) { if(j<last&&data[j]<data[j+1]) j++; if(data[i]>data[j]) _数据结构堆排序c++