SPDK Thread 模型设计与实现_spdk c++-程序员宅基地
技术标签: spring SPDK c++无锁队列 C++后端开发 网络编程 C++Linux后端 Thread
Reactor – 单个CPU Core抽象,主要包含了:
- Lcore对应的CPU Core id
- Threads在该核心下的线程
- Events 这是一个spdk ring,用于事件传递接收
Thread – 线程,但它是spdk抽象出来的线程,主要包含了:
- io_channels资源的抽象,可以是bdev,也可以是具体的tgt
- tailq 线程队列,用于连接下一个线程
- name 线程的名称
- Stats 用于计时统计闲置和忙时时间的
- active_pollers 轮询使用的poller,非定时
- timer_pollers 定时的poller
- messages 这是一个spdk ring,用于消息传递接收
- msg_cache 事件的缓存
1.1 Reactor
对象g_reactor_state有五个状态对应了应用中reactors运行运行状态,
enum spdk_reactor_state {
SPDK_REACTOR_STATE_INVALID = 0,
SPDK_REACTOR_STATE_INITIALIZED = 1,
SPDK_REACTOR_STATE_RUNNING = 2,
SPDK_REACTOR_STATE_EXITING = 3,
SPDK_REACTOR_STATE_SHUTDOWN = 4,
};本文福利, 免费领取C++学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发,音视频开发,Qt开发)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
初始情况下是:
SPDK_REACTOR_STATE_INVALID状态,在spdk app(任意一个target,比如nvmf_tgt)启动时,即调用了spdk_app_start方法,会调用spdk_reactors_init,在这个方法中将会初始化所有需要被初始化的reactors(可以在配置文件中指定需要使用的Core,CPU Core 和reactor是一对一的)。并且会将g_reactor_state设置为SPDK_REACTOR_STATE_INITIALIZED。具体代码如下:
Int spdk_reactors_init(void)
{
// 初始化所有的event mempool
g_spdk_event_mempool = spdk_mempool_create(…);
// 为g_reactors分配内存,g_reactors是一个数组,管理了所有的reactors
posix_memalign((void **)&g_reactors, 64, (last_core + 1) * sizeof(struct spdk_reactor));
// 这里设置了reactor创建线程的方法,之后需要初始化线程的时候将会调用该方法
spdk_thread_lib_init(spdk_reactor_schedule_thread, sizeof(struct spdk_lw_thread));
// 对于每一个启动的reactor,将会初始化它们
// 初始化reactor过程,即为绑定lcore,初始化spdk ring、threads,对rusage无操作
SPDK_ENV_FOREACH_CORE(i) {
reactor = spdk_reactor_get(i);
spdk_reactor_construct(reactor, i);
}
// 设置好状态返回
g_reactor_state = SPDK_REACTOR_STATE_INITIALIZED;
return 0;
}在进入SPDK_REACTOR_STATE_INITIALIZED状态且spdk_app_start在创建了自己的线程并绑定到了reactors后,会调用spdk_reactors_start方法并将g_reactor_state设置为SPDK_REACTOR_STATE_RUNNING状态并会创建所有reactor的线程且轮询。
Void spdk_reactors_start(void) {
SPDK_ENV_FOREACH_CORE(i) {
if (i != current_core) { // 在非master reactor中
reactor = spdk_reactor_get(i); // 得到相应的reactor
// 设置好线程创建后的一个消息,该消息为轮询函数
rc = spdk_env_thread_launch_pinned(reactor->lcore, _spdk_reactor_run, reactor);
// reactor创建好线程并且会自动执行第一个消息
spdk_thread_create(thread_name, tmp_cpumask);
}
}
// 当前CPU core得到reactor,并且开始轮询
reactor = spdk_reactor_get(current_core);
_spdk_reactor_run(reactor);
}之前提到spdk_reactors_init方法中调用了spdk_thread_lib_init方法传入了创建thread的spdk_reactor_schedule_thread方法,在调用spdk_thread_create会回调该方法。这个方法它主要的功能就是告诉这个新创建的线程绑定创建该线程的reactor。
spdk_reactor_schedule_thread(struct spdk_thread *thread)
{
// 得到该线程设置的cpu mask
cpumask = spdk_thread_get_cpumask(thread);
for (i = 0; i < spdk_env_get_core_count(); i++) {
…. // 遍历cpu core
// 通过cpu mask找到对应的核心,并产生event
if (spdk_cpuset_get_cpu(cpumask, core)) {
evt = spdk_event_allocate(core, _schedule_thread, lw_thread, NULL);
break;
}
}
// 传递该event,即对应的reatcor会调用_schedule_thread方法,
spdk_event_call(evt);
}
_schedule_thread(void *arg1, void *arg2)
{
struct spdk_lw_thread *lw_thread = arg1;
struct spdk_reactor *reactor;
// 消息传递到对应的reactor后将该thread加入到reactor中
reactor = spdk_reactor_get(spdk_env_get_current_core());
TAILQ_INSERT_TAIL(&reactor->threads, lw_thread, link);
}
在SPDK_REACTOR_STATE_RUNNING后,此时所有reactor就进入了轮询状态。_spdk_reactor_run函数为线程提供了轮询方法:
static int _spdk_reactor_run(void *arg) {
while (1) {
// 处理reactor上的event消息,消息会在之后讲到
_spdk_event_queue_run_batch(reactor);
// 每一个reactor上注册的thread进行遍历并且处理poller事件
TAILQ_FOREACH_SAFE(lw_thread, &reactor->threads, link, tmp) {
rc = spdk_thread_poll(thread, 0, now);
}
// 检查reactor的状态
if (g_reactor_state != SPDK_REACTOR_STATE_RUNNING) {
break;
}
}
}而当spdk app被调用spdk_app_stop方法后将会相应的通知每一个reactor调用spdk_reactors_stop方法,将g_reactor_state赋值为SPDK_REACTOR_STATE_EXITING,即开始退出了。回到_spdk_reactor_run函数中,轮询将会被跳出,并且执行销毁线程的代码。
static int _spdk_reactor_run(void *arg) {
….. // 轮询
TAILQ_FOREACH_SAFE(lw_thread, &reactor->threads, link, tmp) {
thread = spdk_thread_get_from_ctx(lw_thread);
TAILQ_REMOVE(&reactor->threads, lw_thread, link);
spdk_set_thread(thread);
spdk_thread_exit(thread);
spdk_thread_destroy(thread);
}
}在这之后,主线程的_spdk_reactor_run会返回到spdk_reactors_start中,并将g_reactor_state赋值为SPDK_REACTOR_STATE_SHUTDOWN,返回到spdk_app_start中等待应用退出。
最后,总结一下reactors和CPU core以及spdk thread关系应该如图1所示
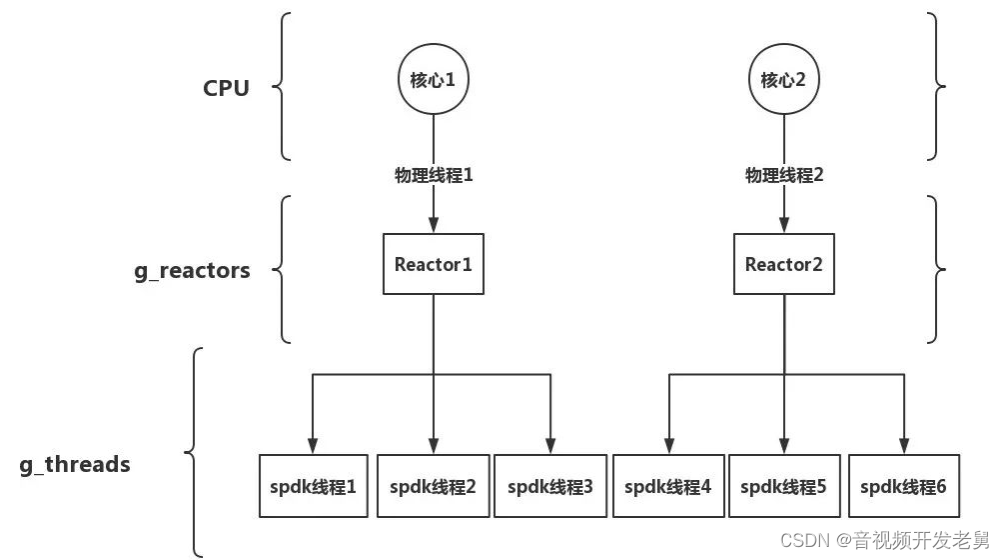
图1 CPU cores、reactors和thread关系图
Reactor生命周期流程图则如图2所示
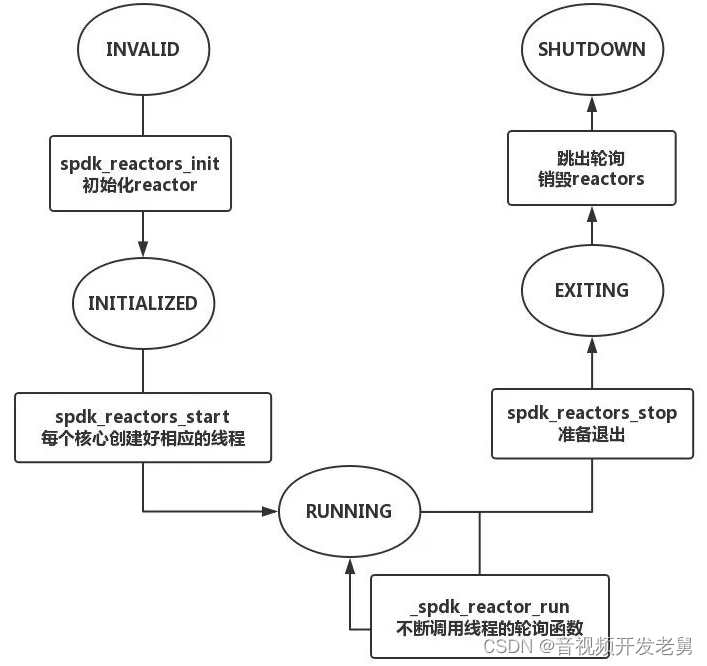
图2 reactor生命周期流程图
1.2 thread
当Reactors进行轮询时,除了处理自己的事件消息之外,还会调用注册在该reactor下面的每一个线程进行轮询。不过通常一个reactor只有一个thread,在spdk应用中,更多的是注册多个poller而不是注册多个thread。具体的轮询方法为:
Int spdk_thread_poll(struct spdk_thread *thread, uint32_t max_msgs, uint64_t now) {
// 首先先处理ring传递过来的消息
msg_count = _spdk_msg_queue_run_batch(thread, max_msgs);
// 调用非定时poller中的方法
TAILQ_FOREACH_REVERSE_SAFE(poller, &thread->active_pollers,
active_pollers_head, tailq, tmp) {
// 调用poller注册的方法之前,会对poller状态检测且转换
if (poller->state == SPDK_POLLER_STATE_UNREGISTERED) {
TAILQ_REMOVE(&thread->active_pollers, poller, tailq);
free(poller);
continue;
}
poller->state = SPDK_POLLER_STATE_RUNNING;
// 调用poller注册的方法
poller_rc = poller->fn(poller->arg);
// poller转换状态
poller->state = SPDK_POLLER_STATE_WAITING;
}
// 调用定时poller中的方法
TAILQ_FOREACH_SAFE(poller, &thread->timer_pollers, tailq, tmp) {
// 类似非定时poller过程,不过会检查是否到了预定的时间
if (now < poller->next_run_tick) break;
}
// 最后统计时间
}Io_device 和 io_channel在thread中也是非常重要的概念。它们的实现都在thread.c中,io_device是设备的抽象,io_channel是对该设备通道的抽象。一个线程可以创建多个io_channel . io_channel只能和一个io_device绑定,并且这个io_channel是别的线程使用不了的。
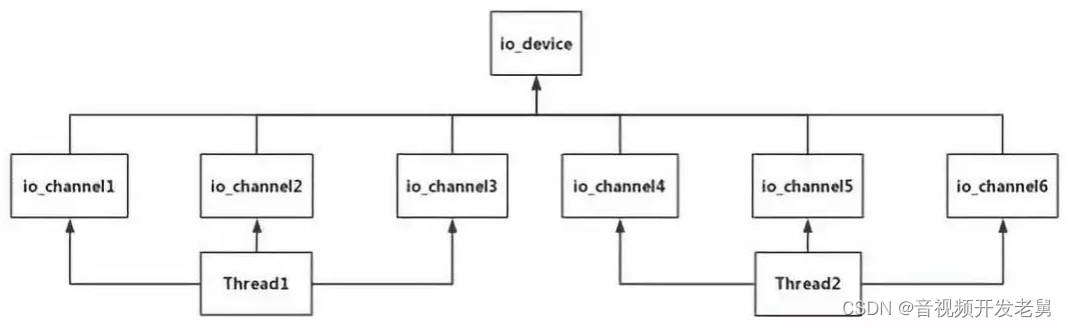
图 3 io_device、io_channel和线程关系图
Io_device结构
struct io_device {
void *io_device; // 抽象的device指针
char name[SPDK_MAX_DEVICE_NAME_LEN + 1]; // 名字
spdk_io_channel_create_cb create_cb; // io_channel创建的回调函数
spdk_io_channel_destroy_cb destroy_cb; // io_channel销毁的回调函数
spdk_io_device_unregister_cb unregister_cb; // io_device解绑的回调函数
struct spdk_thread *unregister_thread; // 不使用该device线程
uint32_t ctx_size; // ctx的大小,将会传给io_channel处理
uint32_t for_each_count; // io_channel的数量
TAILQ_ENTRY(io_device) tailq; // device队列头
uint32_t refcnt; // 计数器
bool unregistered; // 是否该device被注册
};可以看到,io_device实际上只提供了一些自身io_device的操作和io_channel相关的方法,具体的io_device实体其实是那个名字叫io_device的void指针。因为thread中的io_device只提供了thread这一层接口,具体的io操作每一个设备很难被抽象出来,所以这一层的接口只负责管理io_channel的创建、销毁和绑定等。
Io_channel的结构
struct spdk_io_channel {
struct spdk_thread *thread; // 绑定的线程
struct io_device *dev; // 绑定的io_device
uint32_t ref; // io_channel引用计数
uint32_t destroy_ref; // destroy前被引用的次数
TAILQ_ENTRY(spdk_io_channel) tailq; // io_channel 队列头
spdk_io_channel_destroy_cb destroy_cb; // io_channel销毁的回调函数
};虽然io_channel看起来是很简单的结构体,实际上在创建一个io_device的时候,会要求使用者传入一个io_channel_ctx的大小作为调用的参数,而在给io_channel分配内存的时候,除了分配本身io_channel结构体的大小外,还会额外分配一个io_channel_ctx的大小,这个context可以理解成一个void指针,当用户在使用io_channel的时候,实际上还是通过context的部分去访问io_device。
NVMe-oF实例
nvmf_tgt 是spdk中一个重要的模块,这里详细的写一下它作为一个target实例是如何使用thread、io_device以及io_channel的。
在spdk应用刚启动的时候,reactor模块就会自动加载起来,然后在加载nvmf subsystem的时候,会调用spdk_nvmf_subsystem_init(lib/event/subsystems/nvmf/nvmf_tgt.c)方法,nvmf_tgt其实也是有生命周期,并且有一个状态机去管理它的生命周期。
enum nvmf_tgt_state {
NVMF_TGT_INIT_NONE = 0, // 最初的状态
NVMF_TGT_INIT_PARSE_CONFIG, // 解析配置文件
NVMF_TGT_INIT_CREATE_POLL_GROUPS, // 创建poll groups
NVMF_TGT_INIT_START_SUBSYSTEMS, // 启动subsystem
NVMF_TGT_INIT_START_ACCEPTOR, // 开始接收
NVMF_TGT_RUNNING, // running
NVMF_TGT_FINI_STOP_SUBSYSTEMS,
NVMF_TGT_FINI_DESTROY_POLL_GROUPS,
NVMF_TGT_FINI_STOP_ACCEPTOR,
NVMF_TGT_FINI_FREE_RESOURCES,
NVMF_TGT_STOPPED,
NVMF_TGT_ERROR,
};首先在NVMF_TGT_INIT_PARSE_CONFIG状态中,nvmf_tgt会去解析启动时传入的配置文件,当解析了[nvmf]这个label后,会调用spdk_nvmf_tgt_create这个方法,这个方法将初始化了全局的g_nvmf_tgt变量,同时也将tgt注册成了一个io_device。
1 spdk_io_device_register(tgt,
2 spdk_nvmf_tgt_create_poll_group,
3 spdk_nvmf_tgt_destroy_poll_group,
4 sizeof(struct spdk_nvmf_poll_group),
5 "nvmf_tgt");spdk_nvmf_tgt_create_poll_group和spdk_nvmf_tgt_destroy_poll_group是io_channel创建和销毁的回调方法(在spdk_get_io_channel时调用 create_cb)。第三个参数是io_channel_ctx的size,既然这里传入了spdk_nvmf_poll_group的大小,那么很明显说明在nvmf中io_channel_ctx对象就是spdk_nvmf_poll_group。
当config文件解析完了之后,nvmf_tgt状态到了NVMF_TGT_INIT_CREATE_POLL_GROUPS,这个状态下会为每一个线程都创建相应的poll group。
spdk_for_each_thread(nvmf_tgt_create_poll_group,
NULL,
nvmf_tgt_create_poll_group_done);
static void nvmf_tgt_create_poll_group(void *ctx)
{
struct nvmf_tgt_poll_group *pg;
….
pg->thread = spdk_get_thread();
pg->group = spdk_nvmf_poll_group_create(g_spdk_nvmf_tgt);
….
}再看spdk_nvmf_poll_group_create中,
struct spdk_nvmf_poll_group * spdk_nvmf_poll_group_create(struct spdk_nvmf_tgt *tgt)
{
struct spdk_io_channel *ch;
ch = spdk_get_io_channel(tgt);
….
return spdk_io_channel_get_ctx(ch);
}在spdk_get_io_channel中,会先去检查传入的io_device是不是已经注册好了的,如果已经注册了,将会创建一个新的io_channel返回,创建的过程会回调在注册io_device时注册的io_channel创建方法(即方法spdk_nvmf_tgt_create_poll_group)。
static int spdk_nvmf_tgt_create_poll_group(void *io_device, void *ctx_buf)
{
….. // 初始化transport 、nvmf subsystem等
// 注册一个poller
group->poller = spdk_poller_register(spdk_nvmf_poll_group_poll, group, 0);
group->thread = spdk_get_thread();
return 0;
}在spdk_nvmf_poll_group_poll中,因为spdk_nvmf_poll_group对象中有transport的poll group,所以它会调用对应的transport的poll_group_poll方法,比如rdma的poll_group_poll就会轮询rdma注册的poller处理每个在相应的qpair来的请求,进入rdma的状态机将请求处理好。
然后这个状态就结束了,之后再初始化好了nvmf subsystem相关的东西之后,到了状态NVMF_TGT_INIT_START_ACCEPTOR。在这个状态中,只注册了一个poller。
1 g_acceptor_poller = spdk_poller_register(acceptor_poll, g_spdk_nvmf_tgt,
2 g_spdk_nvmf_tgt_conf->acceptor_poll_rate);这个poller调用的transport的方法,不断的监听是不是有新的fd连接进来,如果有就调用new_qpair的回调。
总结
spdk thread 模型是spdk无锁化的基础,在一个线程中,当分配一个任务后,一直会运行到任务结束为止,这确保了不需要进行线程之间的切换而带来额外的损耗。同时,高效的spdk ring提供了不同线程之间的消息传递,这就使得任务结束的结果可以高效的传递给别的处理线程。而io_device和io_channel的设计保证了资源的抽象访问以及独立的路径不去争抢资源池,并且块设备由于是对块进行操作的所以也十分适合抽象成io_device。正是因为以上几点才让spdk线程模型能够达到无锁化且为多个target提供了基础线程框架的支持。
本文福利, 免费领取C++学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发,音视频开发,Qt开发)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
智能推荐
python控制蓝牙音响_[ESP32+MicroPython]智能音响控制-程序员宅基地
文章浏览阅读2k次。blinker支持多种智能音响控制,如天猫精灵、百度小度、小米小爱、京东叮咚等。这里以天猫精灵控制为例,blinker DIY支持将设备模拟成三种类型的智能家居:插座、灯、传感器。Blinker支持多种语音助手控制,如天猫精灵、百度小度,本节以天猫精灵控制为例。示例程序及blinker模块天猫精灵基本接入方法通常语音助手都是对特定的设备类型进行支持,确定设备类型后,才能响应对应的语音指令。使用bl..._blinker支持micpython么
C程序设计(第五版)第6章 利用数组处理批量数据-程序员宅基地
文章浏览阅读7.4k次。
(赠源码)python+django+Mysql上课点名系统03391-计算机毕业设计-程序员宅基地
文章浏览阅读112次。对于本上课点名系统的设计来说,它主要是采用后台采用了B/S的结构,它是应用mysql数据库,python等技术动态编程以及数据库进行努力学习和大量实践,并运用到了整个系统的设计当中,具体根据网上上课点名系统的现状来进行开发的,具体根据学生需求实现网上上课点名系统网络化的管理,各类信息有序地进行存储,进入上课点名系统页面之后,方可开始操作主控界面,系统功能包括管理员服务端:后台首页、系统用户(管理员、任课老师、学校领导、班主任、学生注册)、模块管理(课程类别、课程信息、课程签到、公告信息、签到提醒)。
移动端之禁止长按复制文字(兼容ios)_vue ios 禁止复制-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏2次。移动端之禁止长按复制文字在css中设置以下即可 *{ -webkit-touch-callout:none; /*系统默认菜单被禁用*/ -webkit-user-select:none; /*webkit浏览器*/ -khtml-user-select:none; /*早期浏览器*/ -moz-user-select:none;/*火狐*/ -ms-user-select:none; /*IE10*/ user-select:none;}在添加完_vue ios 禁止复制
Pycharm Debug调试(纯干货)-程序员宅基地
文章浏览阅读3w次,点赞65次,收藏374次。内容目录(原文见公众号python宝或www.xmmup.com)一、打断点二、代码调试三、界面小图标介绍四、控制台介绍# 数字转换为大写人民币import sysimport io..._pycharm debug
android MediaPlayer + GLSurfaceView播放视频_mediaplayer glsurfaceview-程序员宅基地
文章浏览阅读4.7k次。1、配置layout<?xml version="1.0" encoding="utf-8"?><LinearLayout ="http://schemas.android.com/apk/res/android" android:layout_width="match_parent" android:layout_height="match_parent" android:orientation="vertical" >_mediaplayer glsurfaceview
随便推点
机器学习模型对比_机器学习的模型比较-程序员宅基地
文章浏览阅读1k次。1.SVM和LR(逻辑回归)1.1 相同点都是线性分类器。本质上都是求一个最佳分类超平面。都是监督学习算法。 都是判别模型。通过决策函数,判别输入特征之间的差别来进行分类。常见的判别模型有:KNN、SVM、LR。 常见的生成模型有:朴素贝叶斯,隐马尔可夫模型。1.2 不同点损失函数不同,LR的损失函数为交叉熵;svm的损失函数自带正则化,而LR需要在损失函数的基础上加上正则化。 两个模型对数据和参数的敏感程度不同。SVM算法中仅支持向量起作用,大部分样本的增减对模型无影响;而L_机器学习的模型比较
纯C语言完整代码操作单链表(初始化、插入、删除、查找...)-程序员宅基地
文章浏览阅读901次,点赞3次,收藏10次。C语言操作单链表
实战打靶集锦-027-SoSimple1_sosimple 写入试验场-程序员宅基地
文章浏览阅读1.6k次,点赞32次,收藏47次。本文简单记录了博主的一次打靶经历,涉及wordpress扫描与爆破、social-warfare远程代码执行漏洞、sudo命令提权等_sosimple 写入试验场
用opencv的dnn模块做yolov5目标检测_opencv yolov5-程序员宅基地
文章浏览阅读7w次,点赞271次,收藏1.1k次。最近在微信公众号里看到多篇讲解yolov5在openvino部署做目标检测文章,但是没看到过用opencv的dnn模块做yolov5目标检测的。于是,我就想着编写一套用opencv的dnn模块做yolov5目标检测的程序。在编写这套程序时,遇到的bug和解决办法,在这篇文章里讲述一下。在yolov5之前的yolov3和yolov4的官方代码都是基于darknet框架的实现的,因此opencv的dnn模块做目标检测时,读取的是.cfg和.weight文件,那时候编写程序很顺畅,没有遇到bug。但是yolo_opencv yolov5
3的倍数(暴力搜索)_3的倍数csdn-程序员宅基地
文章浏览阅读168次。牛客小白月赛20D 3的倍数题目链接算法分析n最大为15,范围比较小,所以直接来采用爆搜就行算法实现#include<iostream>#include<cstdio>#include<string>#include<cstring>#include<math.h>using namespace std;int ch[20][30];//ch[i][j]记录第i个字符串中j的个数,j为字符转换后的数字int dp[30];/_3的倍数csdn
【腾讯优测干货分享】如何降低App的待机内存(二)——规范测试流程及常见问题...-程序员宅基地
文章浏览阅读71次。本文来自于腾讯优测公众号(wxutest),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/806TiugiSJvFI7fH6eVA5w作者:腾讯TMQ专项测试团队导语最近小优听说,隔壁的腾讯TMQ团队出了一本新书——《移动App性能评测与优化》,便借阅了一本,读完感觉写得确实很赞。这本书体系化地介绍了移动应用性能评测与优化的方方面面,如内存,电量..._如何降低app的待机内存