【深度学习】基于PyTorch搭建ResNet18、ResNet34、ResNet50、ResNet101、ResNet152网络_resnet34 resnet101-程序员宅基地
技术标签: resnet 深度学习 pytorch resnet18 34 resnet 101 152
一、使用PyTorch搭建ResNet18网络并使用CIFAR10数据集训练测试
1. ResNet18网络结构
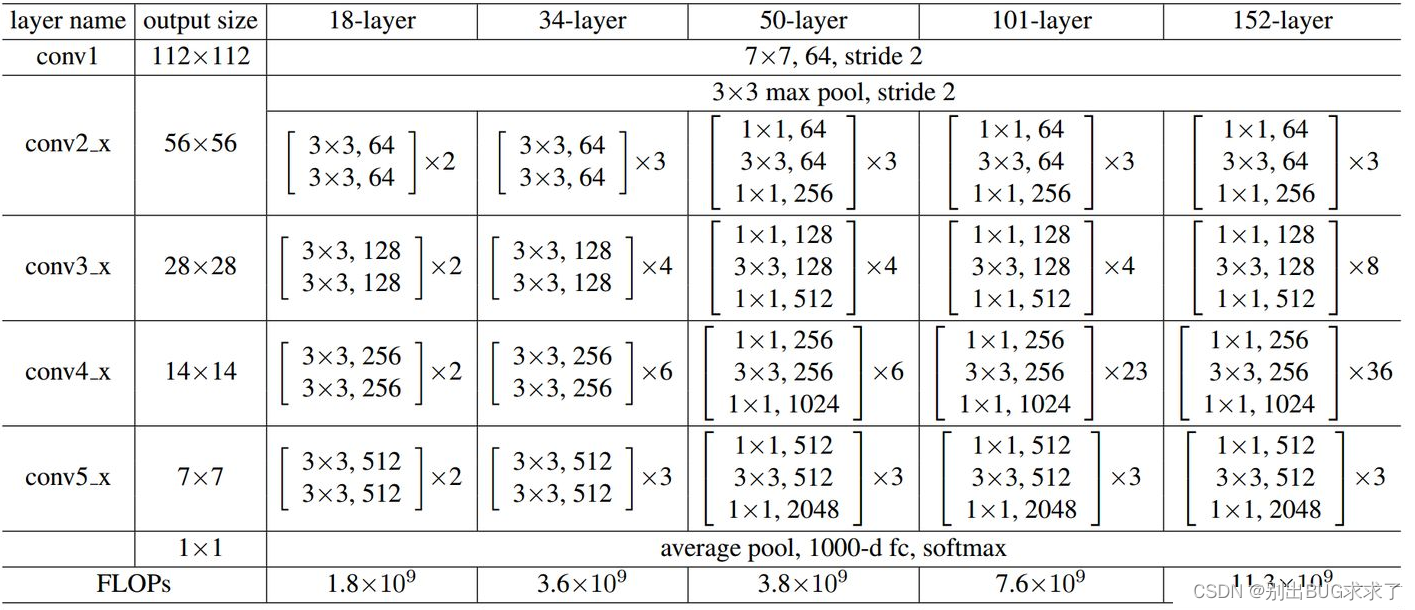
所有不同层数的ResNet:
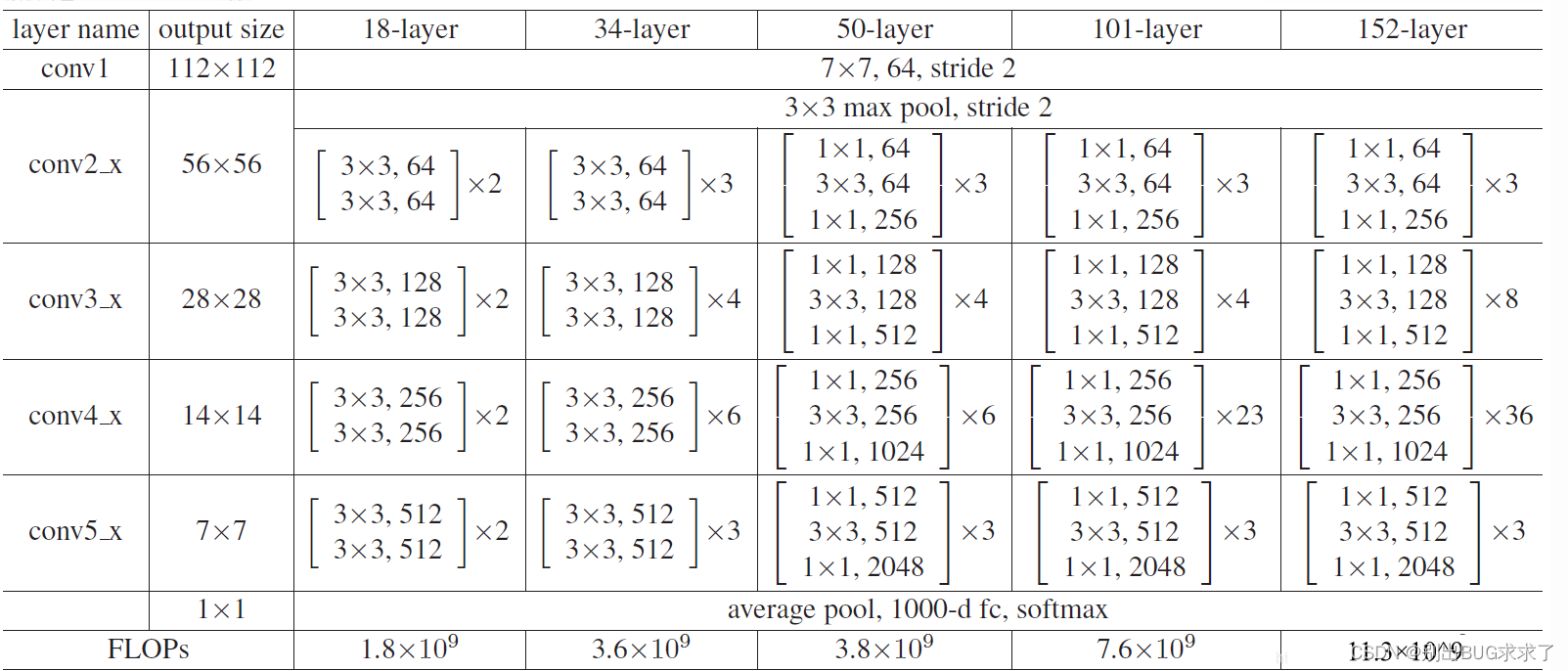
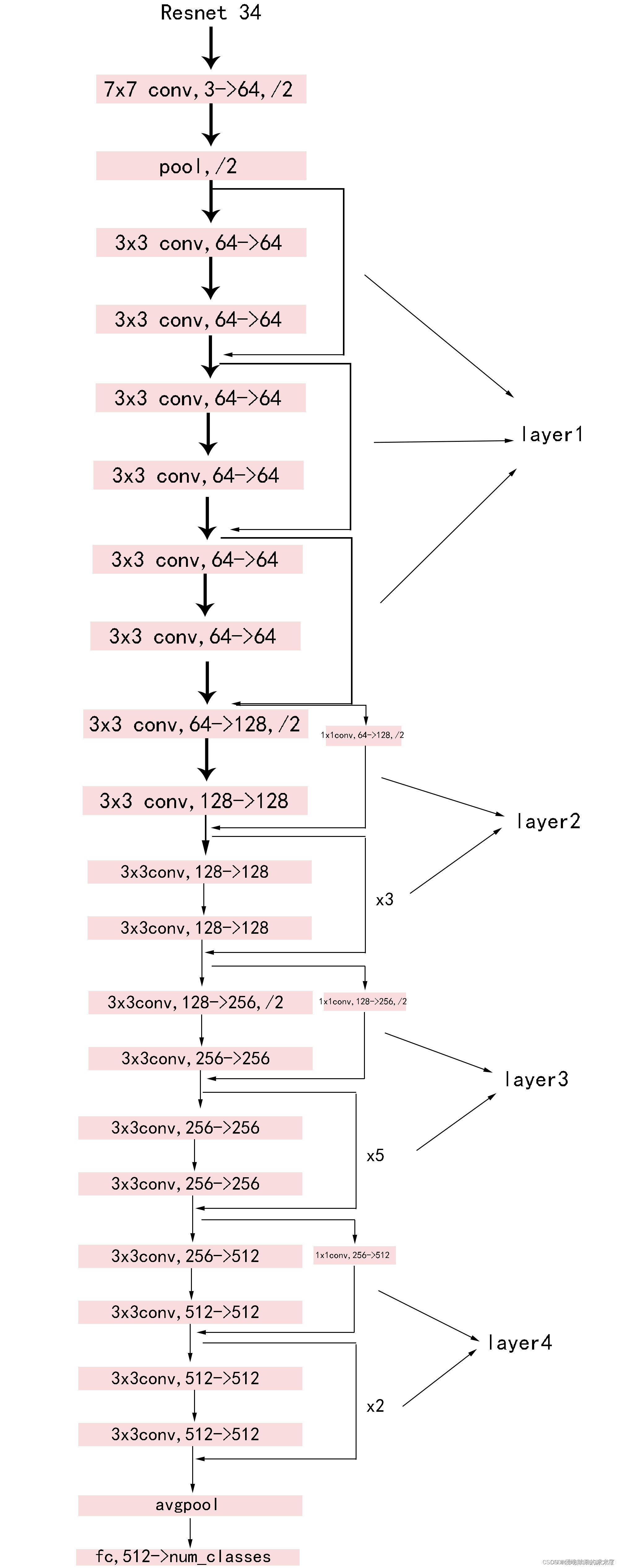
这里给出了我认为比较详细的ResNet18网络具体参数和执行流程图:
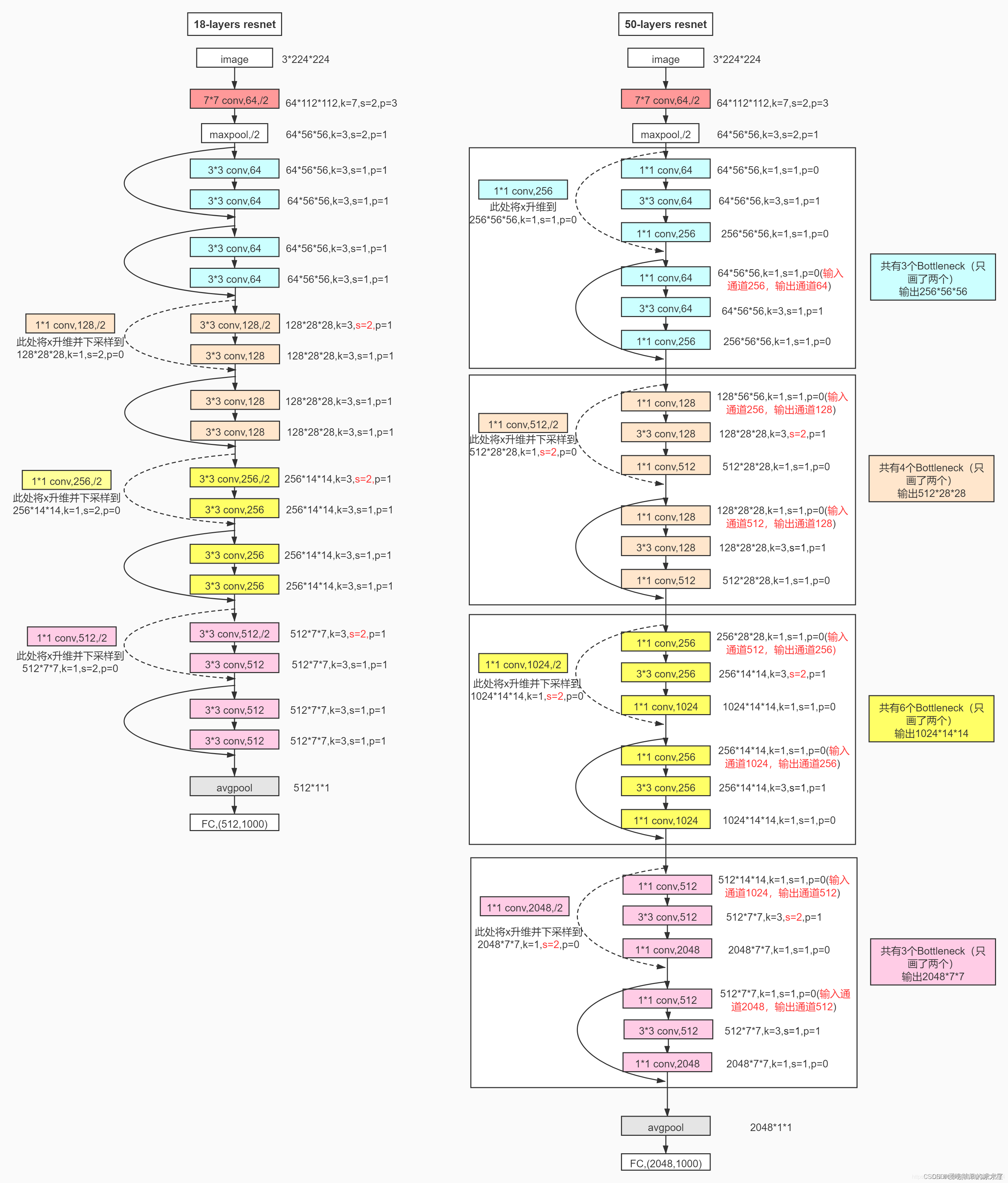
2. 实现代码
这里并未采用BasicBlock和BottleNeck复现ResNet18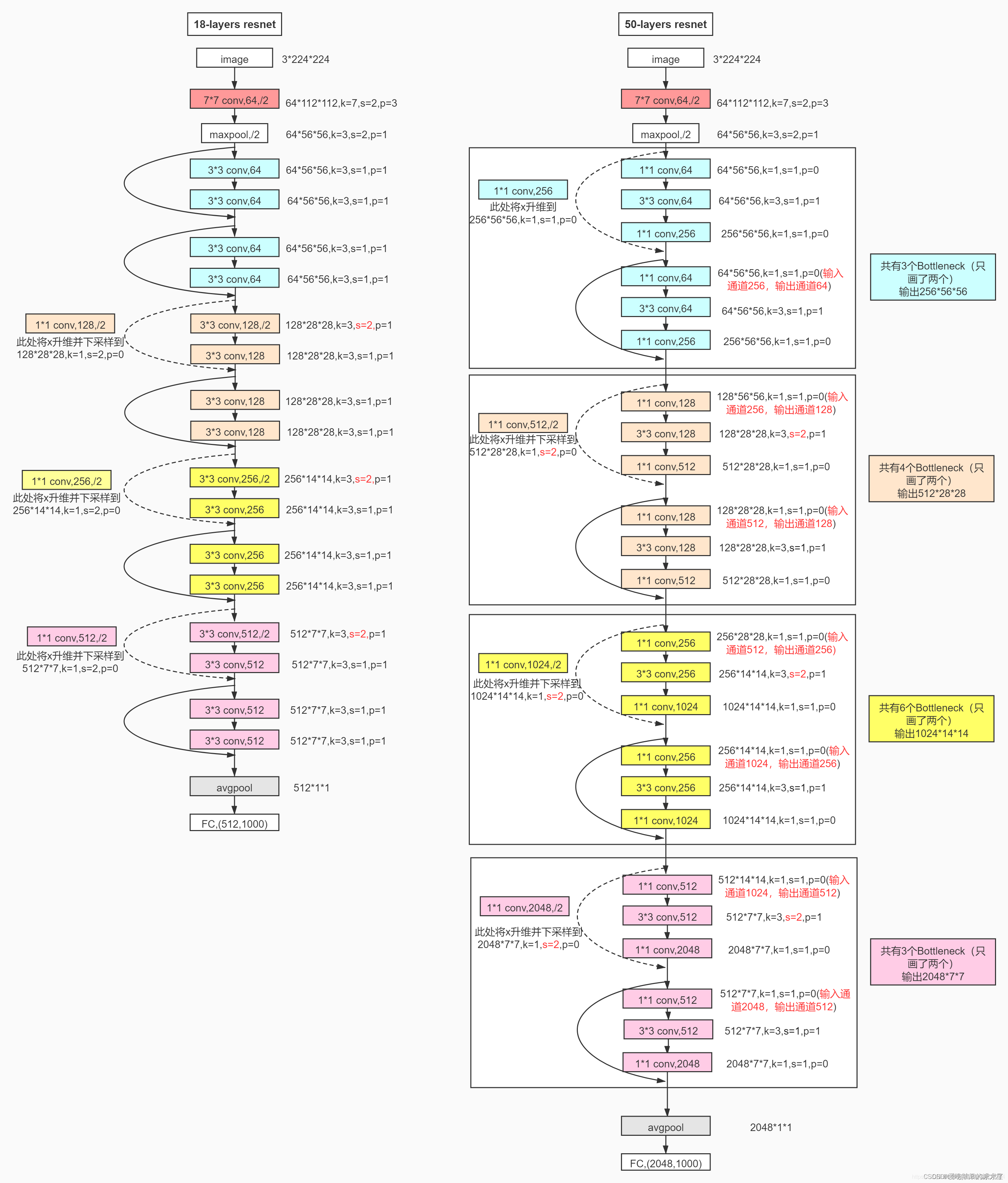
具体ResNet原理细节这里不多做描述,直接上代码
model.py网络模型部分:
import torch
import torch.nn as nn
from torch.nn import functional as F
"""
把ResNet18的残差卷积单元作为一个Block,这里分为两种:一种是CommonBlock,另一种是SpecialBlock,最后由ResNet18统筹调度
其中SpecialBlock负责完成ResNet18中带有虚线(升维channel增加和下采样操作h和w减少)的Block操作
其中CommonBlock负责完成ResNet18中带有实线的直接相连相加的Block操作
注意ResNet18中所有非shortcut部分的卷积kernel_size=3, padding=1,仅仅in_channel, out_channel, stride的不同
注意ResNet18中所有shortcut部分的卷积kernel_size=1, padding=0,仅仅in_channel, out_channel, stride的不同
"""
class CommonBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride): # 普通Block简单完成两次卷积操作
super(CommonBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
def forward(self, x):
identity = x # 普通Block的shortcut为直连,不需要升维下采样
x = F.relu(self.bn1(self.conv1(x)), inplace=True) # 完成一次卷积
x = self.bn2(self.conv2(x)) # 第二次卷积不加relu激活函数
x += identity # 两路相加
return F.relu(x, inplace=True) # 添加激活函数输出
class SpecialBlock(nn.Module): # 特殊Block完成两次卷积操作,以及一次升维下采样
def __init__(self, in_channel, out_channel, stride): # 注意这里的stride传入一个数组,shortcut和残差部分stride不同
super(SpecialBlock, self).__init__()
self.change_channel = nn.Sequential( # 负责升维下采样的卷积网络change_channel
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),
nn.BatchNorm2d(out_channel)
)
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[0], padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
def forward(self, x):
identity = self.change_channel(x) # 调用change_channel对输入修改,为后面相加做变换准备
x = F.relu(self.bn1(self.conv1(x)), inplace=True)
x = self.bn2(self.conv2(x)) # 完成残差部分的卷积
x += identity
return F.relu(x, inplace=True) # 输出卷积单元
class ResNet18(nn.Module):
def __init__(self, classes_num):
super(ResNet18, self).__init__()
self.prepare = nn.Sequential( # 所有的ResNet共有的预处理==》[batch, 64, 56, 56]
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1)
)
self.layer1 = nn.Sequential( # layer1有点特别,由于输入输出的channel均是64,故两个CommonBlock
CommonBlock(64, 64, 1),
CommonBlock(64, 64, 1)
)
self.layer2 = nn.Sequential( # layer234类似,由于输入输出的channel不同,故一个SpecialBlock,一个CommonBlock
SpecialBlock(64, 128, [2, 1]),
CommonBlock(128, 128, 1)
)
self.layer3 = nn.Sequential(
SpecialBlock(128, 256, [2, 1]),
CommonBlock(256, 256, 1)
)
self.layer4 = nn.Sequential(
SpecialBlock(256, 512, [2, 1]),
CommonBlock(512, 512, 1)
)
self.pool = nn.AdaptiveAvgPool2d(output_size=(1, 1)) # 卷积结束,通过一个自适应均值池化==》 [batch, 512, 1, 1]
self.fc = nn.Sequential( # 最后用于分类的全连接层,根据需要灵活变化
nn.Dropout(p=0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(256, classes_num) # 这个使用CIFAR10数据集,定为10分类
)
def forward(self, x):
x = self.prepare(x) # 预处理
x = self.layer1(x) # 四个卷积单元
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pool(x) # 池化
x = x.reshape(x.shape[0], -1) # 将x展平,输入全连接层
x = self.fc(x)
return x
train.py训练部分(使用CIFAR10数据集):
import torch
import visdom
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from PIL import Image
from matplotlib import pyplot as plt
import numpy as np
from ResNet18 import ResNet18
from torch.nn import CrossEntropyLoss
from torch import optim
BATCH_SIZE = 512 # 超参数batch大小
EPOCH = 30 # 总共训练轮数
save_path = "./CIFAR10_ResNet18.pth" # 模型权重参数保存位置
# classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # CIFAR10数据集类别
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 创建GPU运算环境
print(device)
data_transform = {
# 数据预处理
"train": transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]),
"val": transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
}
# 加载数据集,指定训练或测试数据,指定于处理方式
train_data = datasets.CIFAR10(root='./CIFAR10/', train=True, transform=data_transform["train"], download=True)
test_data = datasets.CIFAR10(root='./CIFAR10/', train=False, transform=data_transform["val"], download=True)
train_dataloader = torch.utils.data.DataLoader(train_data, BATCH_SIZE, True, num_workers=0)
test_dataloader = torch.utils.data.DataLoader(test_data, BATCH_SIZE, False, num_workers=0)
# # 展示图片
# x = 0
# for images, labels in train_data:
# plt.subplot(3,3,x+1)
# plt.tight_layout()
# images = images.numpy().transpose(1, 2, 0) # 把channel那一维放到最后
# plt.title(str(classes[labels]))
# plt.imshow(images)
# plt.xticks([])
# plt.yticks([])
# x += 1
# if x == 9:
# break
# plt.show()
# 创建一个visdom,将训练测试情况可视化
viz = visdom.Visdom()
# 测试函数,传入模型和数据读取接口
def evalute(model, loader):
# correct为总正确数量,total为总测试数量
correct = 0
total = len(loader.dataset)
# 取测试数据
for x, y in loader:
x, y = x.to(device), y.to(device)
# validation和test过程不需要反向传播
model.eval()
with torch.no_grad():
out = model(x) # 计算测试数据的输出logits
# 计算出out在第一维度上最大值对应编号,得模型的预测值
prediction = out.argmax(dim=1)
# 预测正确的数量correct
correct += torch.eq(prediction, y).float().sum().item()
# 最终返回正确率
return correct / total
net = ResNet18()
net.to(device) # 实例化网络模型并送入GPU
net.load_state_dict(torch.load(save_path)) # 使用上次训练权重接着训练
optimizer = optim.Adam(net.parameters(), lr=0.001) # 定义优化器
loss_function = CrossEntropyLoss() # 多分类问题使用交叉熵损失函数
best_acc, best_epoch = 0.0, 0 # 最好准确度,出现的轮数
global_step = 0 # 全局的step步数,用于画图
for epoch in range(EPOCH):
running_loss = 0.0 # 一次epoch的总损失
net.train() # 开始训练
for step, (images, labels) in enumerate(train_dataloader, start=0):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item() # 将一个epoch的损失累加
# 打印输出当前训练的进度
rate = (step + 1) / len(train_dataloader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
print("\repoch: {} train loss: {:^3.0f}%[{}->{}]{:.3f}".format(epoch+1, int(rate * 100), a, b, loss), end="")
# 记录test的loss
viz.line([loss.item()], [global_step], win='loss', update='append')
# 每次记录之后将横轴x的值加一
global_step += 1
# 在每一个epoch结束,做一次test
if epoch % 1 == 0:
# 使用上面定义的evalute函数,测试正确率,传入测试模型net,测试数据集test_dataloader
test_acc = evalute(net, test_dataloader)
print(" epoch{} test acc:{}".format(epoch+1, test_acc))
# 根据目前epoch计算所得的acc,看看是否需要保存当前状态(即当前的各项参数值)以及迭代周期epoch作为最好情况
if test_acc > best_acc:
# 保存最好数据
best_acc = test_acc
best_epoch = epoch
# 保存最好的模型参数值状态
torch.save(net.state_dict(), save_path)
# 记录validation的val_acc
viz.line([test_acc], [global_step], win='test_acc', update='append')
print("Finish !")
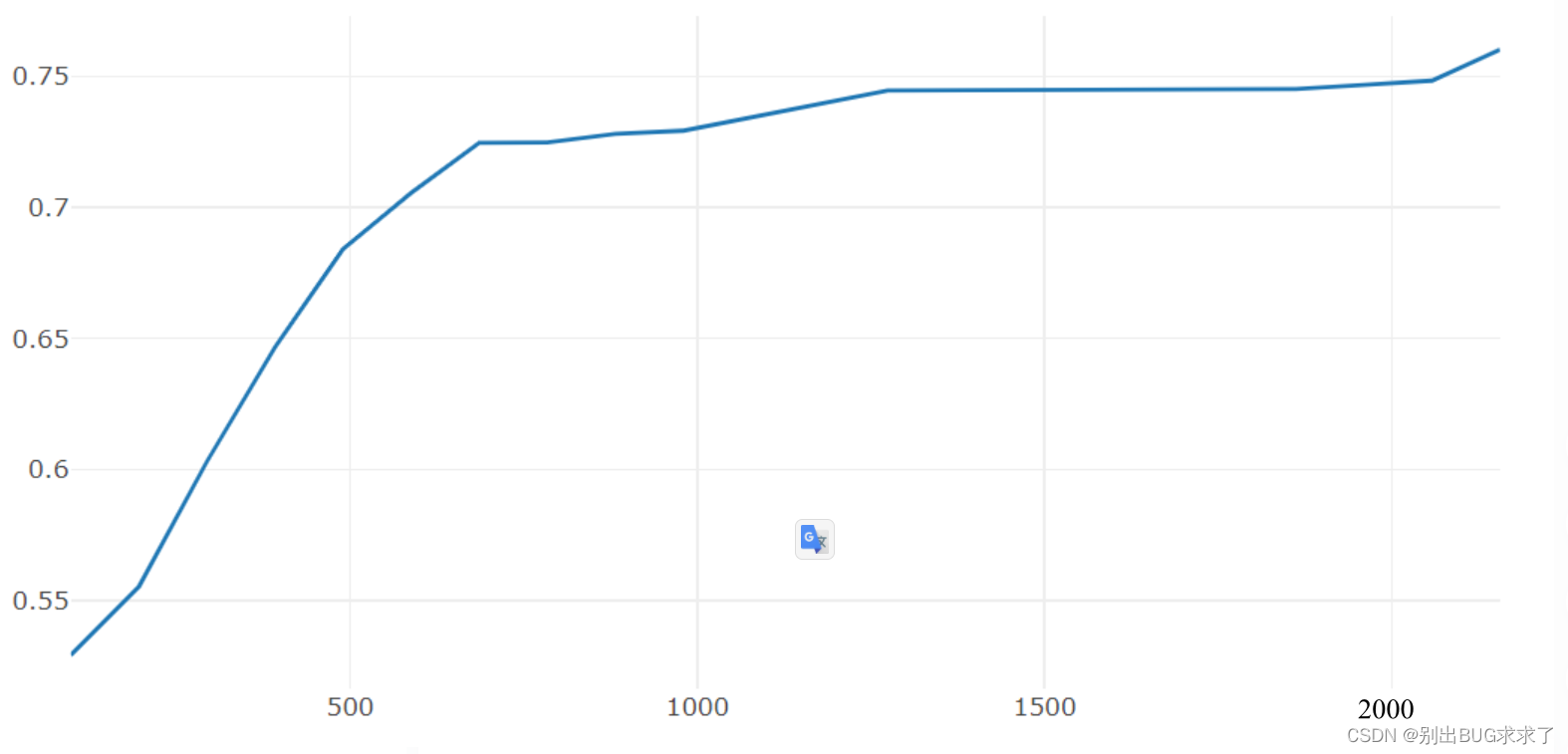
3. 训练测试结果
训练损失:
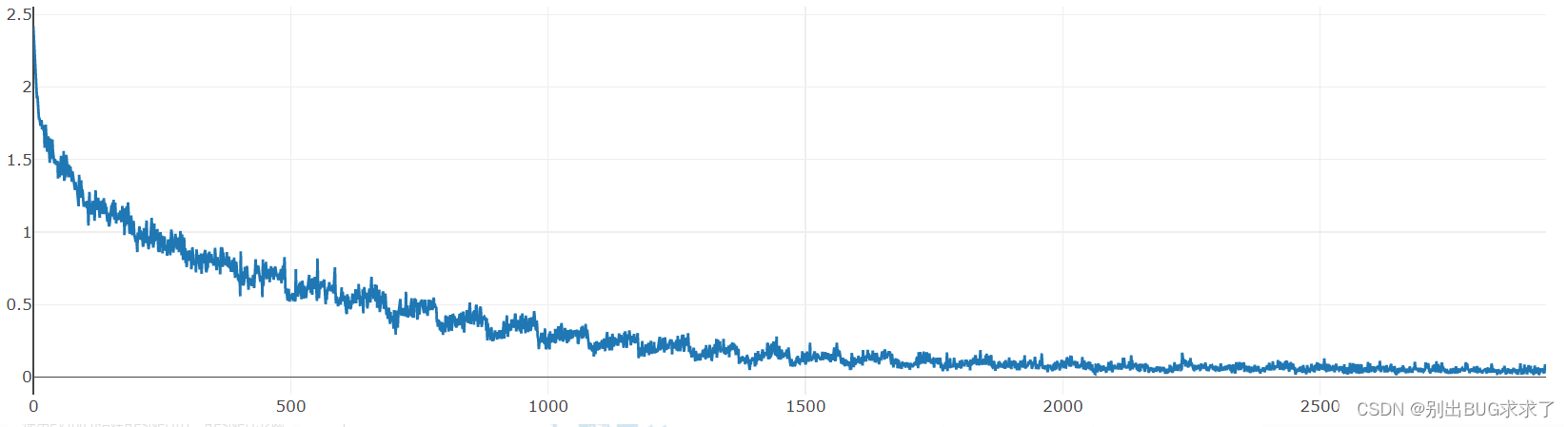
每一个epoch结束之后的测试:
训练时多次修改超参数,最后经过30次epoch之后的测试准确度达到了0.7471,没有在训练下去也没有明显提升,初学深度神经网络,第一次搭建ResNet,我的数据处理等方面处理的有一定欠缺,大家有好的建议也可以提出来
二、使用PyTorch搭建ResNet34网络
1. ResNet34网络结构
参照ResNet18的搭建,由于34层和18层几乎相同,叠加卷积单元数即可,所以没有写注释,具体可以参考我的ResNet18搭建中的注释,ResNet34的训练部分也可以参照。
2. 实现代码
import torch
import torch.nn as nn
from torch.nn import functional as F
class CommonBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride):
super(CommonBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
def forward(self, x):
identity = x
x = F.relu(self.bn1(self.conv1(x)), inplace=True)
x = self.bn2(self.conv2(x))
x += identity
return F.relu(x, inplace=True)
class SpecialBlock(nn.Module):
def __init__(self, in_channel, out_channel, stride):
super(SpecialBlock, self).__init__()
self.change_channel = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride[0], padding=0, bias=False),
nn.BatchNorm2d(out_channel)
)
self.conv1 = nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride[0], padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channel)
self.conv2 = nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=stride[1], padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channel)
def forward(self, x):
identity = self.change_channel(x)
x = F.relu(self.bn1(self.conv1(x)), inplace=True)
x = self.bn2(self.conv2(x))
x += identity
return F.relu(x, inplace=True)
class ResNet34(nn.Module):
def __init__(self, classes_num):
super(ResNet34, self).__init__()
self.prepare = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1)
)
self.layer1 = nn.Sequential(
CommonBlock(64, 64, 1),
CommonBlock(64, 64, 1),
CommonBlock(64, 64, 1)
)
self.layer2 = nn.Sequential(
SpecialBlock(64, 128, [2, 1]),
CommonBlock(128, 128, 1),
CommonBlock(128, 128, 1),
CommonBlock(128, 128, 1)
)
self.layer3 = nn.Sequential(
SpecialBlock(128, 256, [2, 1]),
CommonBlock(256, 256, 1),
CommonBlock(256, 256, 1),
CommonBlock(256, 256, 1),
CommonBlock(256, 256, 1),
CommonBlock(256, 256, 1)
)
self.layer4 = nn.Sequential(
SpecialBlock(256, 512, [2, 1]),
CommonBlock(512, 512, 1),
CommonBlock(512, 512, 1)
)
self.pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.fc = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(256, classes_num)
)
def forward(self, x):
x = self.prepare(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pool(x)
x = x.reshape(x.shape[0], -1)
x = self.fc(x)
return x
三、使用PyTorch搭建ResNet50网络
看过我之前ResNet18和ResNet34搭建的朋友可能想着可不可以把搭建18和34层的方法直接用在50层以上的ResNet的搭建中,我也尝试过。但是ResNet50以上的网络搭建不像是18到34层只要简单修改卷积单元数目就可以完成,ResNet50以上的三种网络都是一个样子,只是层数不同,所以完全可以将34到50层作为一个搭建分水岭。
加上我初学PyTorch和深度神经网络,对于采用BasicBlock和BottleNeck的高效率构建还不是很懂,所以这里给出了类似前两种ResNet的简单暴力堆叠网络层的构建方法
1. ResNet50网络结构
所有不同层数的ResNet:
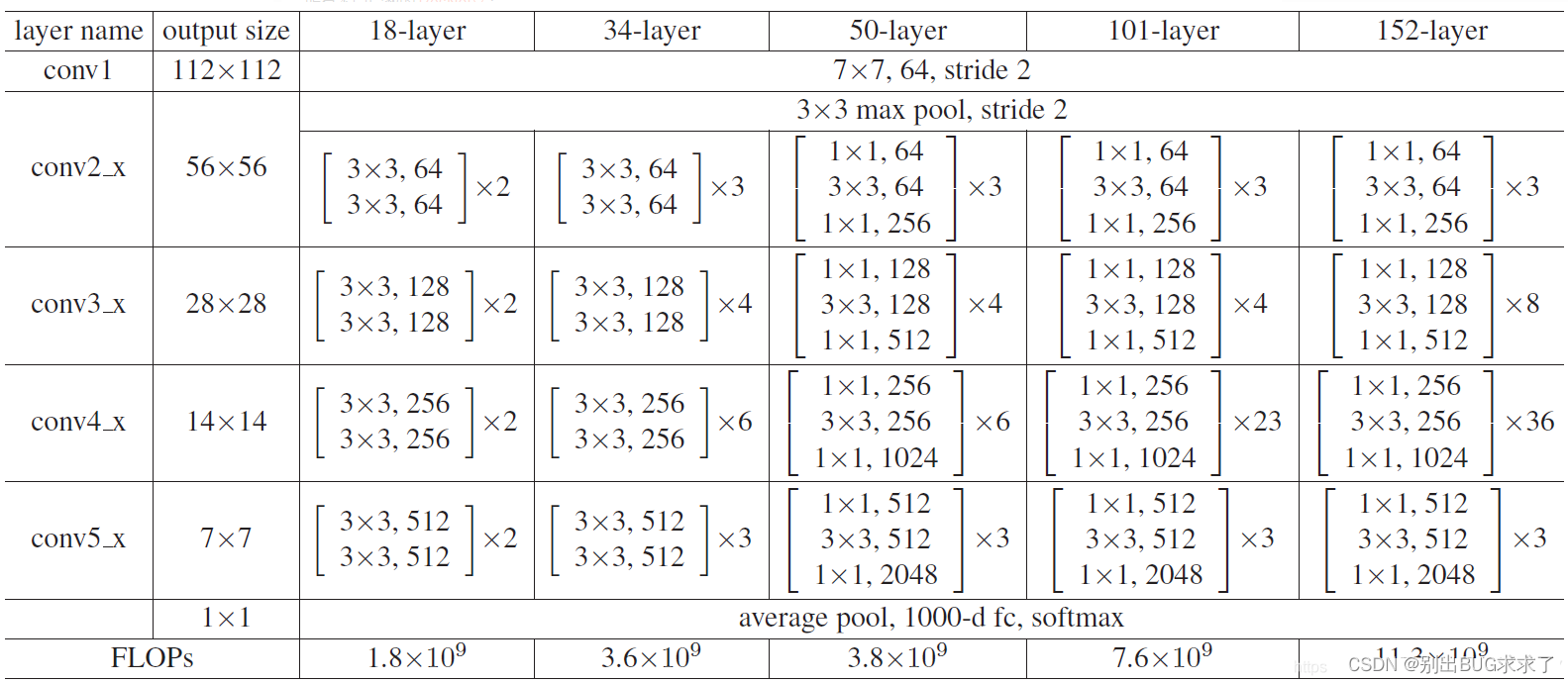
这里给出了我认为比较详细的ResNet50网络具体参数和执行流程图:
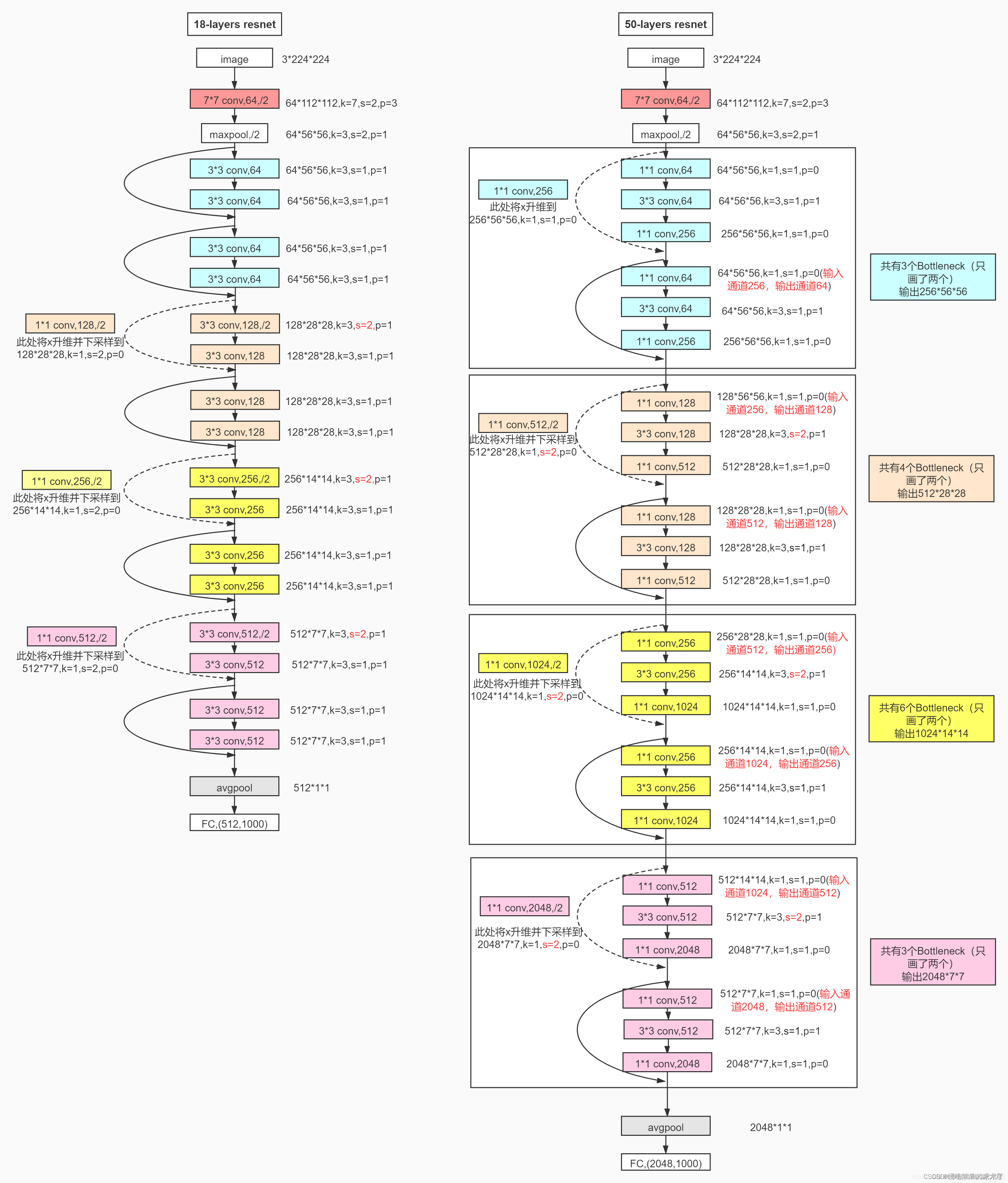
2. 实现代码
model.py模型部分:
import torch
import torch.nn as nn
from torch.nn import functional as F
"""
这里的ResNet50的搭建是暴力形式,直接累加完成搭建,没采用BasicBlock和BottleNeck
第一个DownSample类,用于定义shortcut的模型函数,完成两个layer之间虚线的shortcut,负责layer1虚线的升4倍channel以及其他layer虚线的升2倍channel
观察每一个layer的虚线处升channel仅仅是升channel前后的数量不同以及stride不同,对于kernel_size和padding都分别是1和0,不作为DownSample网络类的模型参数
参数in_channel即是升之前的通道数, out_channel即是升之后的通道数, stride即是每一次升channel不同的stride步长,对于layer1升通道的stride=1,其他layer升通道的stride=2,注意不同
"""
"""
运行时一定要注意:
本网络中的ResNet50类中forward函数里面:layer1_shortcut1.to('cuda:0');layer2_shortcut1.to('cuda:0')等语句,是将实例化的DownSample
网络模型放到train.py训练脚本中定义的GPU同一环境下,不加此句一般会如下报错:
Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
"""
class DownSample(nn.Module):
def __init__(self, in_channel, out_channel, stride): # 传入下采样的前后channel数以及stride步长
super(DownSample, self).__init__() # 继承父类
self.down = nn.Sequential( # 定义一个模型容器down
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, padding=0, bias=False), # 负责虚线shortcut的唯一且重要的一次卷积
nn.BatchNorm2d(out_channel), # 在卷积和ReLU非线性激活之间,添加BatchNormalization
nn.ReLU(inplace=True) # shortcut最后加入一个激活函数,置inplace=True原地操作,节省内存
)
def forward(self, x):
out = self.down(x) # 前向传播函数仅仅完成down这个容器的操作
return out
"""
第一个ResNet50类,不使用BottleNeck单元完成ResNet50层以上的搭建,直接使用forward再加上前面的DownSample模型类函数,指定ResNet50所有参数构建模型
"""
class ResNet50(nn.Module):
def __init__(self, classes_num): # ResNet50仅传一个分类数目,将涉及的所有数据写死,具体数据可以参考下面的图片
super(ResNet50, self).__init__()
# 在进入layer1234之间先进行预处理,主要是一次卷积一次池化,从[batch, 3, 224, 224] => [batch, 64, 56, 56]
self.pre = nn.Sequential(
# 卷积channel从原始数据的3通道,采用64个卷积核,升到64个channel,卷积核大小、步长、padding均固定
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64), # 卷积后紧接一次BatchNormalization
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1) # 预处理最后的一次最大池化操作,数据固定
)
"""
每一个layer的操作分为使用一次的first,和使用多次的next组成,first负责每个layer的第一个单元(有虚线)的三次卷积,next负责剩下单元(直连)的三次卷积
"""
# --------------------------------------------------------------
self.layer1_first = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0, bias=False), # layer1_first第一次卷积保持channel不变,和其他layer的first区别
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False), # layer1_first第二次卷积stride和其他layer_first的stride不同
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False), # layer1_first第三次卷积和其他layer一样,channel升4倍
nn.BatchNorm2d(256) # 注意最后一次卷积结束不加ReLU激活函数
)
self.layer1_next = nn.Sequential(
nn.Conv2d(256, 64, kernel_size=1, stride=1, padding=0, bias=False), # layer1_next的第一次卷积负责将channel减少,减少训练参数量
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False), # layer1_next的最后一次卷积负责将channel增加至可以与shortcut相加
nn.BatchNorm2d(256)
)
# -------------------------------------------------------------- # layer234操作基本相同,这里仅介绍layer2
self.layer2_first = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0, bias=False), # 与layer1_first第一次卷积不同,需要降channel至1/2
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=False), # 注意这里的stride=2与layer34相同,与layer1区别
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False), # 再次升channel
nn.BatchNorm2d(512)
)
self.layer2_next = nn.Sequential(
nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0, bias=False), # 负责循环普通的操作
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
# --------------------------------------------------------------
self.layer3_first = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
self.layer3_next = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
# --------------------------------------------------------------
self.layer4_first = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.layer4_next = nn.Sequential(
nn.Conv2d(2048, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 经过最后的自适应均值池化为[batch, 2048, 1, 1]
# 定义最后的全连接层
self.fc = nn.Sequential(
nn.Dropout(p=0.5), # 以0.5的概率失活神经元
nn.Linear(2048 * 1 * 1, 1024), # 第一个全连接层
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(1024, classes_num) # 第二个全连接层,输出类结果
)
"""
forward()前向传播函数负责将ResNet类中定义的网络层复用,再与上面的DownSample类完美组合
"""
def forward(self, x):
out = self.pre(x) # 对输入预处理,输出out = [batch, 64, 56, 56]
"""
每一层layer操作由两个部分组成,第一个是带有虚线的卷积单元,其他的是循环完成普通的shortcut为直连的卷积单元
"""
layer1_shortcut1 = DownSample(64, 256, 1) # 使用DownSample实例化一个网络模型layer1_shortcut1,参数即是虚线处升channel数据,注意stride=1
layer1_shortcut1.to('cuda:0')
layer1_identity1 = layer1_shortcut1(out) # 调用layer1_shortcut1对卷积单元输入out计算虚线处的identity,用于后面与卷积单元输出相加
out = self.layer1_first(out) # 调用layer1_first完成layer1的第一个特殊的卷积单元
out = F.relu(out + layer1_identity1, inplace=True) # 将identity与卷积单元输出相加,经过relu激活函数
for i in range(2): # 使用循环完成后面几个相同输入输出相同操作的卷积单元
layer_identity = out # 直接直连identity等于输入
out = self.layer1_next(out) # 输入经过普通卷积单元
out = F.relu(out + layer_identity, inplace=True) # 两路结果相加,再经过激活函数
# --------------------------------------------------------------后面layer234都是类似的,这里仅介绍layer2
layer2_shortcut1 = DownSample(256, 512, 2) # 注意后面layer234输入输出channel不同,stride=2都是如此
layer2_shortcut1.to('cuda:0')
layer2_identity1 = layer2_shortcut1(out)
out = self.layer2_first(out)
out = F.relu(out + layer2_identity1, inplace=True) # 完成layer2的第一个卷积单元
for i in range(3): # 循环执行layer2剩下的其他卷积单元
layer_identity = out
out = self.layer2_next(out)
out = F.relu(out + layer_identity, inplace=True)
# --------------------------------------------------------------
layer3_shortcut1 = DownSample(512, 1024, 2)
layer3_shortcut1.to('cuda:0')
layer3_identity1 = layer3_shortcut1(out)
out = self.layer3_first(out)
out = F.relu(out + layer3_identity1, inplace=True)
for i in range(5):
layer_identity = out
out = self.layer3_next(out)
out = F.relu(out + layer_identity, inplace=True)
# --------------------------------------------------------------
layer4_shortcut1 = DownSample(1024, 2048, 2)
layer4_shortcut1.to('cuda:0')
layer4_identity1 = layer4_shortcut1(out)
out = self.layer4_first(out)
out = F.relu(out + layer4_identity1, inplace=True)
for i in range(2):
layer_identity = out
out = self.layer4_next(out)
out = F.relu(out + layer_identity, inplace=True)
# 最后一个全连接层
out = self.avg_pool(out) # 经过最后的自适应均值池化为[batch, 2048, 1, 1]
out = out.reshape(out.size(0), -1) # 将卷积输入[batch, 2048, 1, 1]展平为[batch, 2048*1*1]
out = self.fc(out) # 经过最后一个全连接单元,输出分类out
return out
ResNet50的训练可以参照前面ResNet18搭建中的训练和测试部分:
经过手写ResNet50网络模型的暴力搭建,我认识到了要想把ResNet及其其他复杂网络的搭建,前提必须要把模型整个流程环节全部弄清楚
例如,ResNet50里面每一次的shortcut里面的升维操作的in_channel,out_channel,kernel_size,stride,padding的参数大小变化
每一个卷积单元具体参数都是什么样的,如何才能最大化简化代码;
还有就是搭建复杂的网络模型中,一定要做到步步为营,一步步搭建并检验,每一步都要理解有理有据,最后才能将整个网络搭建起来
还有一个意外收获就是在训练过程中,发现了这样的报错:
Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
原来是因为输入的数据类型为torch.cuda.FloatTensor,说明输入数据在GPU中。模型参数的数据类型为torch.FloatTensor,说明模型还在CPU
故在ResNet50的forward()函数中对实例化的DownSample网络添加到和train.py对ResNet50实例化的网络模型的同一个GPU下,解决了错误
四、使用PyTorch搭建ResNet101、ResNet152网络
参照前面ResNet50的搭建,由于50层以上几乎相同,叠加卷积单元数即可,所以没有写注释。
ResNet101和152的搭建注释可以参照我的ResNet50搭建中的注释
ResNet101和152的训练可以参照我的ResNet18搭建中的训练部分
ResNet101和152可以依旧参照ResNet50的网络图片:
1. 网络结构
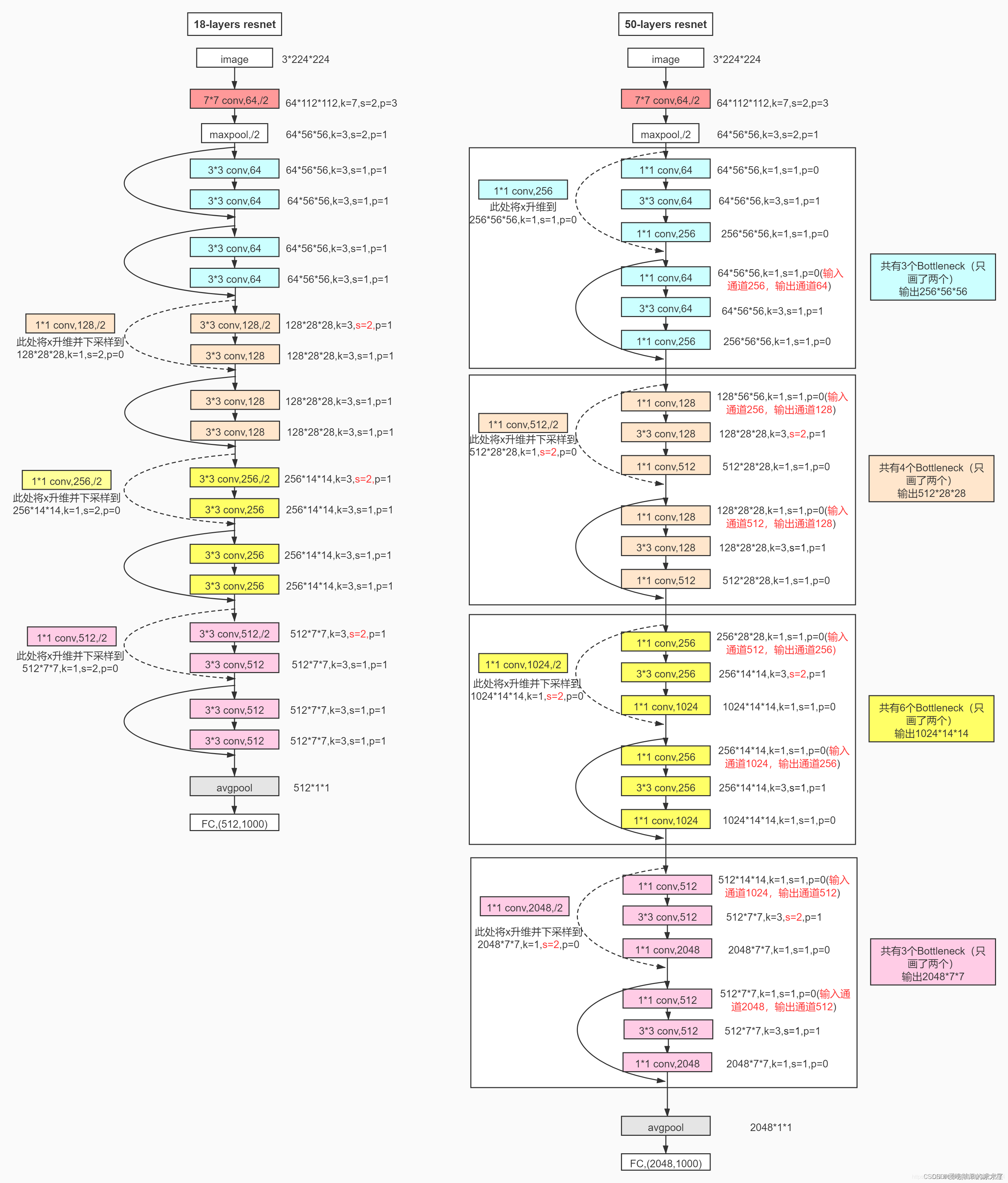
2. 实现代码
(1)ResNet101的model.py模型:
import torch
import torch.nn as nn
from torch.nn import functional as F
class DownSample(nn.Module):
def __init__(self, in_channel, out_channel, stride):
super(DownSample, self).__init__()
self.down = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
def forward(self, x):
out = self.down(x)
return out
class ResNet101(nn.Module):
def __init__(self, classes_num): # 指定分类数
super(ResNet101, self).__init__()
self.pre = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# --------------------------------------------------------------------
self.layer1_first = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256)
)
self.layer1_next = nn.Sequential(
nn.Conv2d(256, 64, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256)
)
# --------------------------------------------------------------------
self.layer2_first = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
self.layer2_next = nn.Sequential(
nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
# --------------------------------------------------------------------
self.layer3_first = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
self.layer3_next = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
# --------------------------------------------------------------------
self.layer4_first = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.layer4_next = nn.Sequential(
nn.Conv2d(2048, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
# --------------------------------------------------------------------
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(2048 * 1 * 1, 1000),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(1000, classes_num)
)
def forward(self, x):
out = self.pre(x)
# --------------------------------------------------------------------
layer1_shortcut = DownSample(64, 256, 1)
layer1_shortcut.to('cuda:0')
layer1_identity = layer1_shortcut(out)
out = self.layer1_first(out)
out = F.relu(out + layer1_identity, inplace=True)
for i in range(2):
identity = out
out = self.layer1_next(out)
out = F.relu(out + identity, inplace=True)
# --------------------------------------------------------------------
layer2_shortcut = DownSample(256, 512, 2)
layer2_shortcut.to('cuda:0')
layer2_identity = layer2_shortcut(out)
out = self.layer2_first(out)
out = F.relu(out + layer2_identity, inplace=True)
for i in range(3):
identity = out
out = self.layer2_next(out)
out = F.relu(out + identity, inplace=True)
# --------------------------------------------------------------------
layer3_shortcut = DownSample(512, 1024, 2)
layer3_shortcut.to('cuda:0')
layer3_identity = layer3_shortcut(out)
out = self.layer3_first(out)
out = F.relu(out + layer3_identity, inplace=True)
for i in range(22):
identity = out
out = self.layer3_next(out)
out = F.relu(out + identity, inplace=True)
# --------------------------------------------------------------------
layer4_shortcut = DownSample(1024, 2048, 2)
layer4_shortcut.to('cuda:0')
layer4_identity = layer4_shortcut(out)
out = self.layer4_first(out)
out = F.relu(out + layer4_identity, inplace=True)
for i in range(2):
identity = out
out = self.layer4_next(out)
out = F.relu(out + identity, inplace=True)
# --------------------------------------------------------------------
out = self.avg_pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
(2) ResNet152的model.py模型:
import torch
import torch.nn as nn
from torch.nn import functional as F
class DownSample(nn.Module):
def __init__(self, in_channel, out_channel, stride):
super(DownSample, self).__init__()
self.down = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride, padding=0, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True)
)
def forward(self, x):
out = self.down(x)
return out
class ResNet152(nn.Module):
def __init__(self, classes_num): # 指定了分类数目
super(ResNet152, self).__init__()
self.pre = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
# -----------------------------------------------------------------------
self.layer1_first = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256)
)
self.layer1_next = nn.Sequential(
nn.Conv2d(256, 64, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256)
)
# -----------------------------------------------------------------------
self.layer2_first = nn.Sequential(
nn.Conv2d(256, 128, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
self.layer2_next = nn.Sequential(
nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512)
)
# -----------------------------------------------------------------------
self.layer3_first = nn.Sequential(
nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
self.layer3_next = nn.Sequential(
nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1024, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(1024)
)
# -----------------------------------------------------------------------
self.layer4_first = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
self.layer4_next = nn.Sequential(
nn.Conv2d(2048, 512, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 2048, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(2048)
)
# -----------------------------------------------------------------------
self.avg_pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(2048 * 1 * 1, 1000),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(1000, classes_num)
)
def forward(self, x):
out = self.pre(x)
# -----------------------------------------------------------------------
layer1_shortcut = DownSample(64, 256, 1)
# layer1_shortcut.to('cuda:0')
layer1_identity = layer1_shortcut(out)
out = self.layer1_first(out)
out = F.relu(out + layer1_identity, inplace=True)
for i in range(2):
identity = out
out = self.layer1_next(out)
out = F.relu(out + identity, inplace=True)
# -----------------------------------------------------------------------
layer2_shortcut = DownSample(256, 512, 2)
# layer2_shortcut.to('cuda:0')
layer2_identity = layer2_shortcut(out)
out = self.layer2_first(out)
out = F.relu(out + layer2_identity, inplace=True)
for i in range(7):
identity = out
out = self.layer2_next(out)
out = F.relu(out + identity, inplace=True)
# -----------------------------------------------------------------------
layer3_shortcut = DownSample(512, 1024, 2)
# layer3_shortcut.to('cuda:0')
layer3_identity = layer3_shortcut(out)
out = self.layer3_first(out)
out = F.relu(out + layer3_identity, inplace=True)
for i in range(35):
identity = out
out = self.layer3_next(out)
out = F.relu(out + identity, inplace=True)
# -----------------------------------------------------------------------
layer4_shortcut = DownSample(1024, 2048, 2)
# layer4_shortcut.to('cuda:0')
layer4_identity = layer4_shortcut(out)
out = self.layer4_first(out)
out = F.relu(out + layer4_identity, inplace=True)
for i in range(2):
identity = out
out = self.layer4_next(out)
out = F.relu(out + identity, inplace=True)
# -----------------------------------------------------------------------
out = self.avg_pool(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
智能推荐
win7更改计算机时间,win7系统自动更改日期时间是怎么回事-程序员宅基地
文章浏览阅读1.9k次。工具/原料硬件:计算机操作系统:Windows7方法/步骤1.Windows7系统不能更改日期和时间的解决方法2.在本地组策略编辑器窗口,展开Windows设置 - 安全设置 - 本地策略;3.在本地策略中找到:用户权限分配,左键点击:用户权限分配,在用户权限分配对应的右侧窗口找到:更改系统时间,并左键双击:更改系统时间;4.在打开的更改系统时间 属性窗口,我们点击:添加用户或组(U);5.在选择..._win7系统时间老是自己跳变
Python-Django-模型_pycharm怎么创建orm模型-程序员宅基地
文章浏览阅读1k次。一、ORM 模型介绍1 、 ORM 模型对象关系映射(英语:(Object Relational Mapping,简称ORM,或ORM,或OR mapping),是一种程序技术,用于实现面向对象编程语言里不同类型系统的数据之间的转换。面向对象是从软件工程基本原则(如耦合、聚合、封装)的基础上发展起来的,而关系数据库则是从数学理论发展而来的,两套理论存在显著的区别。为了解决这个不匹配的现象,对象关系映射技术应运而生。对象关系映射(Object-Relational Mapping)提供了概念性的、_pycharm怎么创建orm模型
如何搭建一套完整的智能安防视频监控平台?关于设备与软件选型的几点建议_前端摄像头的选型依据-程序员宅基地
文章浏览阅读250次。球机摄像头:球机为一体化设备,可以通过云台控制进行转动、变倍和自动聚焦等操作,若需要对设备周边切换场景监控,如大门口、户外活动场所等,可以选择球机。_前端摄像头的选型依据
前端学PHP之正则表达式基础语法_正则表达式主要用于字符串模式匹配或字符串匹配,即什么操作-程序员宅基地
文章浏览阅读177次。前面的话 正则表达式是用于描述字符排列和匹配模式的一种语法规则。它主要用于字符串的模式分割、匹配、查找及替换操作。在PHP中,正则表达式一般是由正规字符和一些特殊字符(类似于通配符)联合构成的一个文本模式的程序性描述。正则表达式有三个作用:1、匹配,也常常用于从字符串中析取信息;2、用新文本代替匹配文本;3、将一个字符串拆分为一组更小的信息块。本文将详细介绍PHP中的正则表达式基础语法 _正则表达式主要用于字符串模式匹配或字符串匹配,即什么操作
桌面上计算机未响应,win7系统打开计算机未响应的解决方法-程序员宅基地
文章浏览阅读415次。很多小伙伴都遇到过win7系统打开计算机未响应的困惑吧,一些朋友看过网上零散的win7系统打开计算机未响应的处理方法,并没有完完全全明白win7系统打开计算机未响应是如何解决的,今天小编准备了简单的解决办法,只需要按照1、点击win7 32位旗舰版系统电脑的开始菜单,打开控制面板; 2、在控制面板中选择外观和个性化;的顺序即可轻松解决,具体的win7系统打开计算机未响应教程就在下文,一起来看看吧!..._电脑打开计算机未响应
【Android】实现键盘收起的时候,输入框UI也消失_安卓收起键盘-程序员宅基地
文章浏览阅读498次。之前对软键盘操作,实现对点击输入框出现软键盘(即手机默认的键盘)现在有一个需求是:软键盘收起的时候,咱的输入框UI也消失。_安卓收起键盘
随便推点
批处理获取所有文件、文件夹名字_bat获取文件夹下所有文件名和文件夹名称-程序员宅基地
文章浏览阅读1.6w次,点赞14次,收藏45次。已收藏下面这个链接的方法也不错excel批处理技巧:如何制作文件档案管理系统excel批处理技巧:如何制作文件档案管理系统http://www.360doc.com/content/18/0913/13/18781560_786337463.shtml有时候我们整理文件的时候需要列出文件夹里面所有的文件名或者文件夹名,生成一个文件目录,一个个重命名然后复制到word或者记事本的方法显示有点太繁琐了。网上有一些自动生成文件目录的程序,比如我之前一直在用的DirIndex.exe。但最近我发现_bat获取文件夹下所有文件名和文件夹名称
计算机视觉图像检测之从EasyDL到BML_easydl paddlex bml-程序员宅基地
文章浏览阅读914次,点赞18次,收藏18次。部署方式选择公有云部署,训练方式均可。增量训练的意思是在之前训练的模型基础上再次进行训练,如果事先没有进行过训练,这一项为不可选中状态。回到Postman,参数栏按如下方式填写,其中第一个KEY-VALUE值直接照写,client_id和client_secret的VALUE值分别为上一步获取的AK、SK。如果数据集质量够高,每种标签标注效果都很好,也可以在模型训练时再进行数据增强,或者直接跳过这一步。在导入界面配置导入信息,选择本地导入,导入压缩包(其他导入方式请自行测试),如图1.1.2。_easydl paddlex bml
红帽oracle关系,redhat和oracle linux kernel对应关系-程序员宅基地
文章浏览阅读1.4k次。Red Hat Enterprise Linux Version / UpdateRed Hat Enterprise Linux – Kernel version / redhat-release stringOracle Linux – Kernel version / release stringsRed Hat Enterprise Linux 7Red Hat Enterprise Li..._oracle linux redhat 对应关系
2020年中南大学研究生招生夏令营机试题_中南大学 计算机 夏令营 笔试-程序员宅基地
文章浏览阅读804次。2020年中南大学研究生招生夏令营机试题题目链接A题题目描述众所周知,彩虹有7种颜色,我们给定七个 字母和颜色 的映射,如下所示:‘A’ -> “red”‘B’ -> “orange”‘C’ -> “yellow”‘D’ -> “green”‘E’ -> “cyan”‘F’ -> “blue”‘G’ -> “purple”但是在某一..._中南大学 计算机 夏令营 笔试
Cmake的option与cmake_dependent_option-程序员宅基地
文章浏览阅读2.9k次。一、介绍cmake提供了一组内置宏,用户可以自己设置。只有当该集合中的其他条件为真时,该宏才会向用户提供一个选项。语法include(CMakeDependentOption)CMAKE_DEPENDENT_OPTION(USE_FOO "Use Foo" ON "USE_BAR;NOT USE_ZOT" OFF)如果USE_BAR为true而USE_ZOT为false,则提供一个默认为ON的选项USE_FOO。否则,它将USE_FOO设._cmake_dependent_option
C++ =default-程序员宅基地
文章浏览阅读5.2k次,点赞10次,收藏34次。在c++中如果我们自行定义了一个构造函数,那么编译器就不会再次生成默认构造函数,我们先看如下的代码我们定义一个类,这个类没有定义构造函数,此时在下面一段代码依然可以正常使用,我们加上一个自定义构造函数:此时编译器会报错,原因很简单,我们自定义了一个构造函数,以前的默认构造函数没了,我们要用如下的方式调用:如果我们还要使用无参构造函数得在定义时自己写个好了此时不报错了,但是这样写代码执行效率没有编译器生成的自定义函数的效率高,为了解决这个问题,C++11 标准引入了一个新特性:default 函数。程_c++ =default