20000字!一文学会Python数据分析-程序员宅基地
近年来,随着数据科学的逐步发展,Python语言的使用率也越来越高,不仅可以做数据处理,网页开发,更是数据科学、机器学习、深度学习等从业者的首选语言。

TIOBE Index for October 2023
“工欲善其事,必先利其器。” 要做好数据分析,离不开一个好的编程工具,不论是从Python的语法之简洁、开发之高效,招聘岗位之热门来说,Python都是数据科学从业者需要掌握的一门语言。
但一直以来,人们却误以为“学会Python”是件很难的事情。
实则不然,这恰恰是我们选择学Python的理由之一。
事实证明,Python人人皆能学会——千万别不信。
-
老少皆宜 —— 也就是说,“只要你愿意”,根本没有年龄差异。十二岁的孩子可以学;十八岁的大学生可以学;在职工作人员可以学…… 就算你已经退休了,想学就能学,谁也拦不住你。
-
不分性别,男性可以学,女性同样可以学,性别差异在这里完全不存在。
-
不分国界,更没有区域差异 —— 互联网的恩惠在于,你在北京、纽约也好,老虎沟、门头沟也罢,在这个领域里同样完全没有任何具体差异。
尤其是在中国。现状是,中国的人口密度极高,优质教育资源的确就是稀缺…… 但在计算机科学领域,所有的所谓 “优质教育资源” 事实上完全没有任何独特的竞争力 —— 编程领域,实际上是当今世上极为罕见的 “教育机会公平之地”。又不仅在中国如此,事实上,在全球范围内也都是如此。
多年以前,不识字的人被称为文盲……
后来,不识英文,也是文盲。人们发现很多科学文献的主导语言都是英语……
再后来,不会计算机的也算是文盲,因为不会计算机基本操作,很多工作的效率很低下,浪费了很多时间……
近些年,不会数据分析的,也算做文盲了,互联网高速发展,用户行为数据越来越多,
你作为一个个体,每天都在产生各种各样的数据,然后时时刻刻都在被别人使用着、分析着…… 然而你自己却全然没有数据分析能力,甚至不知道这事很重要,是不是感觉很可怕?你看看周边那么多人,有多大的比例想过这事?反正那些天天看机器算法生成的信息流的人好像就是全然不在意自己正在被支配……
怎么办?学呗,学点编程罢 —— 巧了,这还真是个正常人都能学会的技能。
为便于上手学习,在开始前再做两点补充
- 安装开发工具
众所周知,在数据分析相关的编程语言中,有三个重中之重:Python、R、Julia 俗称数据科学三剑客。如果有一个工具能集中编写这三者的代码,为大家省去各种安装开发工具的时间,那简直太好不过了,于是jupyter应运而生,作为“工具的工具”而备受数据科学从业者的青睐!
Jupyter的名字就很好地诠释了这一发集大成的思路,它是 Julia、Python、R 语言的组合,拼写相近于木星(Jupiter),而且现在支持的语言也远超这三种了。
所以需要读者自行下载安装好Anaconda提供的Jupyter notebook或者jupyter lab,以便于更好地运行本文相关代码。安装好后可以直接运行Python,因为里面已经帮你集成好了环境。
- 文章阅读指南
虽然笔者力求极简,带你入门Python,但你依然有可能遇到问题,因为编程语言的知识体系有一个特点,知识点之间不是线性的从前往后,而是呈网状的,经常出现前置引用。所以很多时候可能不经意间就用的是后面的知识点,这是不可避免的,遇到这种情况,注定要反复阅读若干遍,之所以取名叫极简入门,这一部分的目标就在与并不是让你立马学会就去写代码,而是让你脱盲……
好了,接下来,与大家一起开始我们的Python旋风之旅,沿用之前《极简统计学入门》、《SQL数据分析极简入门》的“MVP”思路,用三节的内容梳理一下Python数据分析的核心内容。整个系列框架如下:
-
第1节 Python基础知识
-
1-Python简介
-
2-数据类型
-
3-流程控制
-
4-函数
-
第2节 Pandas基础知识
-
1-Pandas 简介
-
2-Pandas 数据类型
-
3-Pandas 数据选取
-
4-Pandas 条件查询
-
5-Pandas 数据运算
-
6-Pandas 合并拼接
-
7-Pandas 分组聚合
-
8-Pandas 重塑透视
-
第3节 Pandas基础知识
-
9-Pandas 文本数据
-
10-Pandas 时间数据
-
11-Pandas 窗口数据
-
12-Pandas 数据读写
-
13-Pandas 表格样式
-
14-Pandas 数据可视化
第1节 Python基础知识
如果你接触过不同编程语言就会发现,任何编程语言的学习,都离不开3个最基本的核心要素,数据类型、流程控制、函数
数据类型是用来描述数据的性质和特征的,它决定了数据在计算和处理过程中的行为和规则。常见的数据类型包括整数、浮点数、字符串、日期等。简而言之,就是你将要操作的东西具有什么样的特点。
流程控制是指通过条件判断和循环等方式,控制程序按照一定的顺序执行不同的操作步骤。它决定了数据的处理流程,包括判断条件、循环次数、分支选择等。简而言之,就是你要操作这个东西的基本流程是什么。
函数是一段预先定义好的代码,用于执行特定的操作或计算。它接受输入参数,并返回一个结果。函数可以用来对数据进行各种计算、转换、筛选等操作,以满足特定的需求。简而言之,就是你要怎么样才能可复用地操作这一类东西。
我们来看第一个核心要素:数据类型
数据类型
Python中的数据类型有很多,如果我们按照大类来分,可以分为三大数据类型:
① 数字型
整型 int
a = 2022 # 把2022赋值给a type(a) # 查看数据类型:<class 'int'>
int
浮点型 float
b = -21.9 type(b) # 数据类型:<class 'float'>
float
复数型 complex
c = 11 + 36j type(c) # 数据类型:<class 'complex'>
complex
布尔型 bool
d = True type(d) # 数据类型:<class 'bool'>
bool
② 字符串型
str_a = "Certified_Data_Analyst" # 创建字符串:"Certified_Data_Analyst" type(str_a) # 数据类型:<class 'str'>
str
len(str_a) # 字符串长度:
22
str_a[0] # 输出字符串第1个字符
'C'
str_a[10] # 输出字符串第11个字符
'D'
str_a[15] # 输出字符串第16个字符
'A'
str_a[:9] # 输出字符串第1到9个字符
'Certified'
str_a[10:14] # 输出从第11到14个的字符
'Data'
str_a[15:] # 输出从第15个后的所有字符
'Analyst'
str_a * 2 # 输出字符串2次
'Certified_Data_AnalystCertified_Data_Analyst'
`str_a+"_Exam" # 连接字符串`
'Certified_Data_Analyst_Exam'
str_a.upper() # 转换为大写
'CERTIFIED_DATA_ANALYST'
str_a.lower() # 转换为小写
'certified_data_analyst'
int("1024") # 字符串转数字:1024
1024
str(3.14) # 数字转字符串:'3.14'
'3.14'
"Certified_Data_Analyst".split("_") # 分隔符拆分字符串
['Certified', 'Data', 'Analyst']
"Certified_Data_Analyst".replace("_", " ") # 替换字符串"_"为" "
'Certified Data Analyst'
"7".zfill(3) # 左边补0
'007'
③ 容器型
可以容纳多个元素的的对象叫做容器,这个概念比较抽象,你可以这么理解,容器用来存放不同的元素,根据存放特点的不同,常见的容器有以下几种:list列表对象、tuple列表对象、dict列表对象、set集合对象
列表 list()
用中括号[]可以创建一个list变量
[2,3,5,7]
[2, 3, 5, 7]
元组 tuple()
用圆括号()可以创建一个tuple变量
(2,3,5,7)
(2, 3, 5, 7)
集合 set()
用花括号{}可以创建一个集合变量
{2,3,5,7}
{2, 3, 5, 7}
字典 dict()
用花括号{}和冒号:,可以创建一个字典变量
{'a':2,'b':3,'c':5,'d':7}
{'a': 2, 'b': 3, 'c': 5, 'd': 7}
流程控制
分支
举例说明,我们给x赋值-10,然后通过一个分支做判断,当x大于零时候输出"x是正数",当x小于零的时候输出"x是负数",其他情况下输出"x是零"
x = -10 if x > 0: print("x是正数") elif x < 0: print("x是负数") else: print("x是零")
x是负数
循环
举例说明for循环,用for循环来迭代从1到5的数字,并将每个数字打印出来
# for循环 for i in range(1, 6): print(i)
1
2
3
4
5
首先,range(1, 6)函数生成一个序列,从1到5(不包括6)。
然后,for循环使用变量i来迭代这个序列中的每个元素。
在每次迭代中,print(i)语句将当前的i值打印出来。
再举例说明while循环:用while循环迭代从1到10的数字,并将每个数字打印出来
# while循环 i = 1 while i <= 10: print(i) i += 1 if i == 6: break
1
2
3
4
5
首先,将i初始化为1。
然后,while循环将在i小于或等于10时执行。在每次循环中,print(i)语句将当前的i值打印出来。
接下来,i += 1语句将i的值递增。在每次循环中,if i == 6: break语句将检查i的值是否等于6。如果是,则使用break语句终止循环。
函数
Python提供了许多常用函数,这部分内容数据分析最基础的内容,有部分函数在Python内置库就已经自带
常用函数:
abs(x) # 返回x的绝对值。 round(x) # 返回最接近x的整数。如果有两个整数与x距离相等,将返回偶数。 pow(x, y) # 返回x的y次方。 sqrt(x) # 返回x的平方根。 max(x1, x2, ...) # 返回一组数中的最大值。 min(x1, x2, ...) # 返回一组数中的最小值。 sum([x1,x2,...]) # 返回可迭代对象中所有元素的和。
也有一些是来自于math库,我们需要用from math import *来引入math库,然后才能调用里面的函数。这个过程就好比你要使用一个工具箱里面的工具,必须先找到工具箱。通过使用这些数学函数,可以进行各种数学计算和数据处理操作。
常用数学函数
# 数学运算函数 from math import * sqrt(x) #x的算术平方根 log(x) #自然对数 log2(x) #以2为底的常用对数 log10(x) #以10为底的常用对数 exp(x) #x的e次幂 modf(x) #返回x的⼩数部分和整数部分 floor(x) #对x向下取值整 ceil(x) #对x向上取整 divmod(x,y) #接受两个数字,返回商和余数的元组(x//y , x%y)# 三角函数 sin(x) #x的正弦值 cos(x) #x的余弦值 tan(x) #x的正切值 asin(x) #x的反正弦值 acos(x) #x的反余弦值 atan(x) #x的反正切值# 排列组合函数
# from itertools import * product() #序列中的元素进行排列, 相当于使用嵌套循环组合 permutations(p[, r]) #从序列p中取出r个元素的组成全排列 combinations(p, r) #从序列p中取出r个元素组成全组合,元素不允许重复 combinations_with_replacement(p, r) #从序列p中取出r个元素组成全组合,允许重复# 简单统计函数 pandas describe() #描述性统计 count() #非空观测数量 sum() #所有值之和 mean() #平均值 median() #中位数 mode() #值的模值 std() #标准差 var() #方差 min() #所有值中的最小值 max() #所有值中的最大值 abs() #绝对值 prod() #数组元素的乘积 corr() #相关系数矩阵 cov() #协方差矩阵# 排序函数 sort() #没有返回值,会改变原有的列表 sorted() #需要用一个变量进行接收,不会修改原有列表# 集合运算符号和函数 & #交集 | #并集 - #差集 ^ #异或集(不相交的部分) intersection() #交集 union() #并集 difference() #补集 symmetric_difference() #异或集(不相交的部分) isdisjoint() #两集合有无相同元素 issubset() #是不是子集 issuperset() #是不是超集# 缺失值处理(Pandas) np.nan (Not a Number) #空值 None #缺失值 pd.NaT #时间格式的空值# 判断缺失值 isnull()/isna() #断Series或DataFrame中是否包含空值 notnull() #与isnull()结果互为取反 isin() #判断Series或DataFrame中是否包含某些值 dropna() #删除Series或DataFrame中的空值 fillna() #填充Series或DataFrame中的空值 ffill()/pad() #用缺失值的前一个值填充 bfill()/backfill() #用缺失值的后一个值填充 replace() #替换Series或DataFrame中的指定值
自定义函数
自定义函数是一种在Python中自行定义的可重复使用代码块的方法。通过定义自己的函数,可以将一系列操作放在一个函数中,并在需要时多次调用该函数。
举例说明,如何创建和调用一个自定义函数:
def linear(x): y = 2*x + 4 return y
在上面的例子中,我们用def linear(x): 定义了一个名为linear的函数,该函数接收一个参数x。
然后函数体内计算了一个y值,它是x的两倍加上4。
这样,我们调用linea函数的时候,并传入一个参数x时,函数将返回计算得到的y值。例如,如果我们调用linear(3),函数将返回10,因为2*3 + 4 = 10。
可以根据具体的需求来编写自定义函数,并在程序中调用它们。
再看一个稍微复杂一点的例子(PS:建议初学者先跳过这个例子)
`# 斐波那契数列(通过迭代方法实现) def fib(n): n1=1;n2=1;n3=1 if n<1: print('输入有误!') return 0 else: while (n-2) > 0 : n3 = n2 + n1 n1 = n2 n2 = n3 n -= 1 return n3 result = fib(35) result`
9227465
# 斐波那契数列(通过递归方法实现)
def fib(n):
if n < 1:
print('输入有误!')
return -1
elif n == 1 or n == 2:
return 1
else:
return fib(n-1) + fib(n-2)
result = fib(35)
result
9227465
# 斐波那契数列(通过矩阵方法实现) import numpy as np def dotx(a,n): for i in range(1,n+1): if i == 1: b = a else : b = np.dot(a,b) return b def fib(n): a = np.array([[1,1],[1,0]]) r = dotx(a,n) return r[0,1] result = fib(35) result
9227465`
第2节 1 Pandas简介
---------------
说好开始学Python,怎么到了Pandas?
前面说过,既然定义为极简入门,我们只抓核心中的核心。
那怎么样挑核心重点呢?
在你不熟悉的情况下,肯定需要请教别人,需要注意的是,不要去问应该学什么编程语言,而是去问,如果只学一门编程语言,应该学什么?
这样,问题就从多分类的选择题,变成了一道优化题!有人说选择大于努力,而现实中的情况是,我们选的不是答案只有对与错的问题,而是在好、次好与更好之间选更好,这个道理看似简单,但却不容易做到,小到你学Python应该优先学什么,大到一个国家的资源配置应该优先发展什么?本质上都是最优化问题。
回到今天的主题,如果学Python语言,但只学一个库,你要学什么?有人说人工智能好啊,我要学算法,错!算法再牛也需要你从底层的数据开始,所以答案肯定是Pandas,这属于做数据分析处理数据必知必会的内容。
今天的故事,要从08年北京奥运会那年说起,远在纽约一家量化投资公司的打工人Wes McKinney,由于在日常数据分析工作中 想多摸会儿鱼 备受Excel与SQL等工具的折磨,于是他开始构建了一个新项目 **Pandas**,用来解决数据处理过程中遇到的全部任务。

Wes McKinney
### 什么是Pandas?
Pandas是一个开源的Python库,主要用于数据分析、数据处理、数据可视化。
Pandas作为Python数据分析的核心包,提供了大量的数据分析函数,包括数据处理、数据抽取、数据集成、数据计算等基本的数据分析手段。
Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)的简称。
千万记得Pandas不是咱们的国宝大熊猫的复数形式!!!(尽管这一强调极有可能适得其反,但还是忍不住贴一张panda的图)

Panda
### 为什么Pandas必学?
* 比SQL语句还要简洁,查询数据事半功倍!简单
* 基于Numpy数值计算,数据处理高效运算!高效
* 支持数值、文本和可视化,快速灵活完成数据需求!强大
如果用一个字来说明,那就是“快”。这个快指的是你从开始构思到写完代码的时间,毫不夸张地说,当你把数据需求用文字梳理清楚的时候,基本上也就相当于用Python实现了这一过程,因为在Python的世界,所见即所得
### 怎么学Pandas?
把大象放进冰箱里需要三步,打开冰箱门、把大象塞进去、关上冰箱门。同样地,怎么学Pandas,也需要三步
第一步,必须了解Pandas的数据结构。在之前的系列文章里面说过,学习语言学习的三板斧,数据结构,流程控制,自定义函数。这里pandas虽然只是一个库,但同样有其数据结构。
* pandas 简介
* pandas 数据类型
* Series
* DataFrame
* pandas 数据查看
第二步,必须学会用Pandas做数据处理。这是你做数据分析的基本功,里面包含如下内容
* pandas 条件查询
* pandas 数据计算
* pandas 合并连接
* pandas 分组聚合
* pandas 数据重塑
第三步,掌握一些Pandas高阶与展示技巧。这是你分析或展示的必备技能
* pandas 文本数据
* pandas 时间数据
* pandas 窗口数据
* pandas 数据读写
* pandas 表格样式
* pandas 数据可视化
第2节 2 Pandas数据类型
Pandas 有两种自己独有的基本数据结构。需要注意的是,它固然有着两种数据结构,因为它依然是 Python 的一个库,所以 Python 中有的数据类型在这里依然适用。我们分别看一下这两种数据结构:
#### Series
Series:一维数组。该结构能够放置各种数据类型,比如字符、整数、浮点数等
我们先引入pandas包,这里有一个约定成俗的写法`import pandas as pd` 将pandas引入,并命其别名为pd
接着将列表`[2,3,5,7,11]`放到pd.Series()里面
import pandas as pd s = pd.Series([2,3,5,7,11],name = ‘A’) s
0 2
1 3
2 5
3 7
4 11
Name: A, dtype: int64
Time- Series:以时间为索引的Series
同样的,将列`['2024-01-01 00:00:00', '2024-01-01 03:00:00','2024-01-01 06:00:00']` 放到pd.DatetimeIndex()里面
dts1 = pd.DatetimeIndex([‘2024-01-01 00:00:00’, ‘2024-01-01 03:00:00’,‘2024-01-01 06:00:00’]) dts1
DatetimeIndex([‘2024-01-01 00:00:00’, ‘2024-01-01 03:00:00’,
‘2024-01-01 06:00:00’],
dtype=‘datetime64[ns]’, freq=None)
还有另外一种写法`pd.date_range` 可以按一定的频率生成时间序列
dts2 = pd.date_range(start=‘2024-01-01’, periods=6, freq=‘3H’) dts2
DatetimeIndex([‘2024-01-01 00:00:00’, ‘2024-01-01 03:00:00’,
‘2024-01-01 06:00:00’, ‘2024-01-01 09:00:00’,
‘2024-01-01 12:00:00’, ‘2024-01-01 15:00:00’],
dtype=‘datetime64[ns]’, freq=‘3H’)
dts3 = pd.date_range(‘2024-01-01’, periods=6, freq=‘d’) dts3
DatetimeIndex([‘2024-01-01’, ‘2024-01-02’, ‘2024-01-03’, ‘2024-01-04’,
‘2024-01-05’, ‘2024-01-06’],
dtype=‘datetime64[ns]’, freq=‘D’)
#### DataFrame
DataFrame:二维的表格型数据结构,可以理解为Series的容器,通俗地说,就是可以把Series放到DataFrame里面。
它是一种二维表格型数据的结构,既有行索引,也有列索引。行索引是 index,列索引是 columns。类似于初中数学里,在二维平面里用坐标轴来定位平面中的点。
注意,DataFrame又是Pandas的核心!接下来的内容基本上以DataFrame为主
先来看看如何创建DataFrame,上面说过Series也好,DataFrame也罢,本质上都是容器。
千万别被”容器“这个词吓住了,通俗来说,就是里面可以放东西的东西。
**从字典创建DataFrame**
相当于给里面放dict:先创建一个字典`d`,再把`d`放进了`DataFrame`里命名为`df`
d = {‘A’: [1, 2, 3], ‘B’: [4, 5, 6], ‘C’: [7, 8, 9]} df = pd.DataFrame(data = d) df
|
| A | B | C |
| --- | --- | --- | --- |
| 0 | 1 | 4 | 7 |
| 1 | 2 | 5 | 8 |
| 2 | 3 | 6 | 9 |
**从列表创建DataFrame**
先创建了一个列表`d`,再把`d`放进了`DataFrame`里命名为`df1`
d = [[4, 7, 10],[5, 8, 11],[6, 9, 12]] df1 = pd.DataFrame( data = d, index=[‘a’, ‘b’, ‘c’], columns=[‘A’, ‘B’, ‘C’]) df1
|
| A | B | C |
| --- | --- | --- | --- |
| a | 4 | 7 | 10 |
| b | 5 | 8 | 11 |
| c | 6 | 9 | 12 |
**从数组创建DataFrame**
数组(array)对你来说可能是一个新概念,在Python里面,创建数组需要引入一个类似于Pandas的库,叫做Numpy。与前面引入Pandas类似,我们用 `import numpy as np`来引入numpy,命其别名为np。
同样的,先创建一个数组`d`,再把`d`放进了`DataFrame`里命名为`df2`
import numpy as np d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) df2 = pd.DataFrame(data = d, index=[‘a’, ‘b’, ‘c’], columns=[‘A’, ‘B’, ‘C’]) df2
|
| A | B | C |
| --- | --- | --- | --- |
| a | 1 | 2 | 3 |
| b | 4 | 5 | 6 |
| c | 7 | 8 | 9 |
以上,我们用了不同的方式来创建DataFrame,接下来,我们看看创建好后,如何查看数据
* * *
第2节 3 Pandas数据查看
----------------
这里我们创建一个`DataFrame`命名为`df`:
import numpy as np import pandas as pd d = np.array([[81, 28, 24, 25, 96], [ 8, 35, 56, 98, 39], [13, 39, 55, 36, 3], [70, 54, 69, 48, 12], [63, 80, 97, 25, 70]]) df = pd.DataFrame(data = d, columns=list(‘abcde’)) df
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 2 | 13 | 39 | 55 | 36 | 3 |
| 3 | 70 | 54 | 69 | 48 | 12 |
| 4 | 63 | 80 | 97 | 25 | 70 |
查看前2行
df.head(2)
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
| 1 | 8 | 35 | 56 | 98 | 39 |
查看后2行
df.tail(2)
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 3 | 70 | 54 | 69 | 48 | 12 |
| 4 | 63 | 80 | 97 | 25 | 70 |
查看随机2行
df.sample(2)
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 3 | 70 | 54 | 69 | 48 | 12 |
#### 按列选取
单列选取,我们有3种方式可以实现
第一种,直接在`[]`里面写上要筛选的列名
df[‘a’]
0 81
1 8
2 13
3 70
4 63
Name: a, dtype: int64
第二种,在`.iloc[]`里的逗号前面写上要筛选的行索引,在.iloc\[\]里的逗号后面写上要删选的列索引。其中写`:`代表所有,写`0:3`代表从索引0到2
df.iloc[0:3,0]
0 81
1 8
2 13
Name: a, dtype: int64
第三种,直接`.`后面写上列名
df.a
0 81
1 8
2 13
3 70
4 63
Name: a, dtype: int64
同样的,选择多列常见的也有3种方式:
第一种,直接在`[]`里面写上要筛选的列名组成的列表`['a','c','d']`
df[[‘a’,‘c’,‘d’]]
|
| a | c | d |
| --- | --- | --- | --- |
| 0 | 81 | 24 | 25 |
| 1 | 8 | 56 | 98 |
| 2 | 13 | 55 | 36 |
| 3 | 70 | 69 | 48 |
| 4 | 63 | 97 | 25 |
第二种,在`.iloc[]`里面行索引位置写`:`选取所有行,列索引位置写上要筛选的列索引组成的列表`[0,2,3]`
df.iloc[:,[0,2,3]]
|
| a | c | d |
| --- | --- | --- | --- |
| 0 | 81 | 24 | 25 |
| 1 | 8 | 56 | 98 |
| 2 | 13 | 55 | 36 |
| 3 | 70 | 69 | 48 |
| 4 | 63 | 97 | 25 |
第三种,在`.loc[]`里面的行索引位置写`:`来选取所有行,在列索引位置写上要筛选的列索引组成的列表`['a','c','d']`
df.loc[:,[‘a’,‘c’,‘d’]]
|
| a | c | d |
| --- | --- | --- | --- |
| 0 | 81 | 24 | 25 |
| 1 | 8 | 56 | 98 |
| 2 | 13 | 55 | 36 |
| 3 | 70 | 69 | 48 |
| 4 | 63 | 97 | 25 |
#### 按行选取
直接选取第一行
df[0:1]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
用`loc`选取第一行
df.loc[0:0]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
选取任意多行
df.iloc[[1,3],]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 3 | 70 | 54 | 69 | 48 | 12 |
选取连续多行
df.iloc[1:4,:]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 2 | 13 | 39 | 55 | 36 | 3 |
| 3 | 70 | 54 | 69 | 48 | 12 |
#### 指定行列
指定行列值
df.iat[2,2] # 根据行列索引
55
df.at[2,‘c’] # 根据行列名称
55
指定行列区域
df.iloc[[2,3],[1,4]]
|
| b | e |
| --- | --- | --- |
| 2 | 39 | 3 |
| 3 | 54 | 12 |
以上是关于如何查看一个DataFrame里的数据,包括用`[]`、`iloc`、`iat`等方式选取数据,接下来我们来看如何用条件表达式来筛选数据:
* * *
第2节 4 Pandas条件查询
----------------
在pandas中,可以使用条件筛选来选择满足特定条件的数据
import pandas as pd d = np.array([[81, 28, 24, 25, 96], [ 8, 35, 56, 98, 39], [13, 39, 55, 36, 3], [70, 54, 69, 48, 12], [63, 80, 97, 25, 70]]) df = pd.DataFrame(data = d, columns=list(‘abcde’)) df
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 2 | 13 | 39 | 55 | 36 | 3 |
| 3 | 70 | 54 | 69 | 48 | 12 |
| 4 | 63 | 80 | 97 | 25 | 70 |
单一条件 df[df[‘a’]>60] df.loc[df[‘a’]>60]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 0 | 81 | 28 | 24 | 25 | 96 |
| 3 | 70 | 54 | 69 | 48 | 12 |
| 4 | 63 | 80 | 97 | 25 | 70 |
单一条件&多列 df.loc[(df[‘a’]>60) ,[‘a’,‘b’,‘d’]]
|
| a | b | d |
| --- | --- | --- | --- |
| 0 | 81 | 28 | 25 |
| 3 | 70 | 54 | 48 |
| 4 | 63 | 80 | 25 |
多条件 df[(df[‘a’]>60) & (df[‘b’]>60)]
|
| a | b | c | d | e |
| --- | --- | --- | --- | --- | --- |
| 4 | 63 | 80 | 97 | 25 | 70 |
多条件 筛选行 & 指定列筛选列 df.loc[(df[‘a’]>60) & (df[‘b’]>60) ,[‘a’,‘b’,‘d’]]
|
| a | b | d |
| --- | --- | --- | --- |
| 4 | 63 | 80 | 25 |
以上是使用条件筛选来选取数据 ,接下来我们来看如何对数据进行数学计算
* * *
`
第2节 5 Pandas数学计算
===================
import pandas as pd d = np.array([[81, 28, 24, 25, 96], [ 8, 35, 56, 98, 39], [13, 39, 55, 36, 3], [70, 54, 69, 48, 12], [63, 80, 97, 25, 70]]) df = pd.DataFrame(data = d, columns=list('abcde')) df
|
| a | b | c | d | e |
| — | — | — | — | — | — |
| 0 | 81 | 28 | 24 | 25 | 96 |
| 1 | 8 | 35 | 56 | 98 | 39 |
| 2 | 13 | 39 | 55 | 36 | 3 |
| 3 | 70 | 54 | 69 | 48 | 12 |
| 4 | 63 | 80 | 97 | 25 | 70 |
聚合计算
聚合计算是指对数据进行汇总和统计的操作。常用的聚合计算方法包括计算均值、求和、最大值、最小值、计数等。
df['a'].mean()
47.0
df['a'].sum()
235
df['a'].max()
81
df['a'].min()
8
df['a'].count()
5
df['a'].median() # 中位数
63.0
df['a'].var() #方差
1154.5
df['a'].skew() # 偏度
-0.45733193928530436
df['a'].kurt() # 峰度
-2.9999915595685325
df['a'].cumsum() # 累计求和
0 81
1 89
2 102
3 172
4 235
Name: a, dtype: int64
df['a'].cumprod() # 累计求积
0 81
1 648
2 8424
3 589680
4 37149840
Name: a, dtype: int64
df['a'].diff() # 差分
0 NaN
1 -73.0
2 5.0
3 57.0
4 -7.0
Name: a, dtype: float64
df['a'].mad() # 平均绝对偏差
29.2
按行、列聚合计算
df.sum(axis=0) # 按列求和汇总到最后一行
a 235
b 236
c 301
d 232
e 220
dtype: int64
`df.sum(axis=1) # 按行求和汇总到最后一列`
0 254
1 236
2 146
3 253
4 335
dtype: int64
df.describe() # 描述性统计
|
| a | b | c | d | e |
| — | — | — | — | — | — |
| count | 5.000000 | 5.000000 | 5.000000 | 5.000000 | 5.000000 |
| mean | 47.000000 | 47.200000 | 60.200000 | 46.400000 | 44.000000 |
| std | 33.977934 | 20.656718 | 26.395075 | 30.369392 | 39.083244 |
| min | 8.000000 | 28.000000 | 24.000000 | 25.000000 | 3.000000 |
| 25% | 13.000000 | 35.000000 | 55.000000 | 25.000000 | 12.000000 |
| 50% | 63.000000 | 39.000000 | 56.000000 | 36.000000 | 39.000000 |
| 75% | 70.000000 | 54.000000 | 69.000000 | 48.000000 | 70.000000 |
| max | 81.000000 | 80.000000 | 97.000000 | 98.000000 | 96.000000 |
agg函数
对整个DataFrame批量使用多个聚合函数
df.agg(['sum', 'mean','max','min','median'])
|
| a | b | c | d | e |
| — | — | — | — | — | — |
| sum | 235.0 | 236.0 | 301.0 | 232.0 | 220.0 |
| mean | 47.0 | 47.2 | 60.2 | 46.4 | 44.0 |
| max | 81.0 | 80.0 | 97.0 | 98.0 | 96.0 |
| min | 8.0 | 28.0 | 24.0 | 25.0 | 3.0 |
| median | 63.0 | 39.0 | 56.0 | 36.0 | 39.0 |
对DataFramed的某些列应用不同的聚合函数
df.agg({'a':['max','min'],'b':['sum','mean'],'c':['median']})
|
| a | b | c |
| — | — | — | — |
| max | 81.0 | NaN | NaN |
| min | 8.0 | NaN | NaN |
| sum | NaN | 236.0 | NaN |
| mean | NaN | 47.2 | NaN |
| median | NaN | NaN | 56.0 |
apply、applymap、map函数
在Python中如果想要对数据使用函数,可以借助apply(),applymap(),map()对数据进行转换,括号里面可以是直接函数式,或者自定义函数(def)或者匿名函数(lambad)
1、当我们要对数据框(DataFrame)的数据进行按行或按列操作时用apply()
df.apply(lambda x :x.max()-x.min(),axis=1) #axis=1,表示按行对数据进行操作 #从下面的结果可以看出,我们使用了apply函数之后,系统自动按行找最大值和最小值计算,每一行输出一个值
0 72
1 90
2 52
3 58
4 72
dtype: int64
df.apply(lambda x :x.max()-x.min(),axis=0) #默认参数axis=0,表示按列对数据进行操作 #从下面的结果可以看出,我们使用了apply函数之后,系统自动按列找最大值和最小值计算,每一列输出一个值
a 73
b 52
c 73
d 73
e 93
dtype: int64
2、当我们要对数据框(DataFrame)的每一个数据进行操作时用applymap(),返回结果是DataFrame格式
df.applymap(lambda x : 1 if x>60 else 0) #从下面的结果可以看出,我们使用了applymap函数之后, #系统自动对每一个数据进行判断,判断之后输出结果
|
| a | b | c | d | e |
| — | — | — | — | — | — |
| 0 | 1 | 0 | 0 | 0 | 1 |
| 1 | 0 | 0 | 0 | 1 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 0 | 0 |
| 4 | 1 | 1 | 1 | 0 | 1 |
3、当我们要对Series的每一个数据进行操作时用map()
df['a'].map(lambda x : 1 if x>60 else 0)
0 1
1 0
2 0
3 1
4 1
Name: a, dtype: int64
总结:
apply() 函数可以在DataFrame或Series上应用自定义函数,可以在行或列上进行操作。
applymap() 函数只适用于DataFrame,可以在每个元素上应用自定义函数。
map() 函数只适用于Series,用于将每个元素映射到另一个值。
以上是数学运算部分,包括聚合计算、批量应用聚合函数,以及对Series和DataFrame进行批量映射,接下来我们来看如何对数据进行合并拼接
第2节 6 Pandas合并连接
在pandas中,有多种方法可以合并和拼接数据。常见的方法包括append()、concat()、merge()。
追加(Append)
append()函数用于将一个DataFrame或Series对象追加到另一个DataFrame中。
import pandas as pd df1 = pd.DataFrame({'A': ['a', 'b'], 'B': [1, 2]}) df1
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
df2 = pd.DataFrame({'A': [ 'b', 'c','d'], 'B': [2, 3, 4]}) df2
|
| A | B |
| — | — | — |
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | d | 4 |
`df1.append(df2,ignore_index=True)`
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | b | 2 |
| 3 | c | 3 |
| 4 | d | 4 |
合并(Concat)
concat()函数用于沿指定轴将多个对象(比如Series、DataFrame)堆叠在一起。可以沿行或列方向进行拼接。 先看一个上下堆叠的例子
先看一个上下堆叠的例子
df1 = pd.DataFrame({'A': ['a', 'b'], 'B': [1, 2]}) df1
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
df2 = pd.DataFrame({'A': [ 'b', 'c','d'], 'B': [2, 3, 4]}) df2
|
| A | B |
| — | — | — |
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | d | 4 |
pd.concat([df1,df2],axis =0) # 上下拼接
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | d | 4 |
再看一个左右堆叠的例子
df1 = pd.DataFrame({'A': ['a', 'b']}) df1
|
| A |
| — | — |
| 0 | a |
| 1 | b |
df2 = pd.DataFrame({'B': [1, 2], 'C': [2, 4]}) df2
|
| B | C |
| — | — | — |
| 0 | 1 | 2 |
| 1 | 2 | 4 |
pd.concat([df1,df2],axis =1) # 左右拼接
|
| A | B | C |
| — | — | — | — |
| 0 | a | 1 | 2 |
| 1 | b | 2 | 4 |
连接(Merge)
merge()函数用于根据一个或多个键将两个DataFrame的行连接起来。类似于SQL中的JOIN操作。

数据连接 1 (pd.merge)
先看一下 inner 和 outer连接
df1 = pd.DataFrame({'A': ['a', 'b', 'c'], 'B': [1, 2, 3]}) df1
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
df2 = pd.DataFrame({'A': [ 'b', 'c','d'], 'B': [2, 3, 4]}) df2
|
| A | B |
| — | — | — |
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | d | 4 |
pd.merge(df1,df2,how = 'inner')
|
| A | B |
| — | — | — |
| 0 | b | 2 |
| 1 | c | 3 |
pd.merge(df1,df2,how = 'outer')
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
| 3 | d | 4 |
数据连接 2 (pd.merge)
再看左右链接的例子:
df1 = pd.DataFrame({'A': ['a', 'b', 'c'], 'B': [1, 2, 3]}) df1
|
| A | B |
| — | — | — |
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
df2 = pd.DataFrame({'A': [ 'b', 'c','d'], 'C': [2, 3, 4]}) df2
|
| A | C |
| — | — | — |
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | d | 4 |
pd.merge(df1,df2,how = 'left',on = "A") # 左连接
|
| A | B | C |
| — | — | — | — |
| 0 | a | 1 | NaN |
| 1 | b | 2 | 2.0 |
| 2 | c | 3 | 3.0 |
pd.merge(df1,df2,how = 'right',on = "A") # 右连接
|
| A | B | C |
| — | — | — | — |
| 0 | b | 2.0 | 2 |
| 1 | c | 3.0 | 3 |
| 2 | d | NaN | 4 |
pd.merge(df1,df2,how = 'inner',on = "A") # 内连接
|
| A | B | C |
| — | — | — | — |
| 0 | b | 2 | 2 |
| 1 | c | 3 | 3 |
pd.merge(df1,df2,how = 'outer',on = "A") # 外连接
|
| A | B | C |
| — | — | — | — |
| 0 | a | 1.0 | NaN |
| 1 | b | 2.0 | 2.0 |
| 2 | c | 3.0 | 3.0 |
| 3 | d | NaN | 4.0 |
补充1个小技巧
df1[df1['A'].isin(df2['A'])] # 返回在df1中列'A'的值在df2中也存在的行
|
| A | B |
| — | — | — |
| 1 | b | 2 |
| 2 | c | 3 |
df1[~df1['A'].isin(df2['A'])] # 返回在df1中列'A'的值在df2中不存在的行
|
| A | B |
| — | — | — |
| 0 | a | 1 |
第2节 7 Pandas分组聚合
分组聚合(group by)顾名思义就是分2步:
-
先分组:根据某列数据的值进行分组。用
groupby()对某列进行分组 -
后聚合:将结果应用聚合函数进行计算。在
agg()函数里应用聚合函数计算结果,如sum()、mean()、count()、max()、min()等,用于对每个分组进行聚合计算。
import pandas as pd import numpy as np import random
df = pd.DataFrame({'A': ['a', 'b', 'a', 'b','a', 'b'], 'B': ['L', 'L', 'M', 'N','M', 'M'], 'C': [107, 177, 139, 3, 52, 38], 'D': [22, 59, 38, 50, 60, 82]}) df
|
| A | B | C | D |
| — | — | — | — | — |
| 0 | a | L | 107 | 22 |
| 1 | b | L | 177 | 59 |
| 2 | a | M | 139 | 38 |
| 3 | b | N | 3 | 50 |
| 4 | a | M | 52 | 60 |
| 5 | b | M | 38 | 82 |
单列分组
① 对单列分组后应用sum聚合函数
df.groupby('A').sum()
|
| C | D |
| — | — | — |
| A |
|
|
| — | — | — |
| a | 298 | 120 |
| b | 218 | 191 |
② 对单列分组后应用单个指定的聚合函数
df.groupby('A').agg({'C': 'min'}).rename(columns={'C': 'C_min'})
|
| C_min |
| — | — |
| A |
|
| — | — |
| a | 52 |
| b | 3 |
③ 对单列分组后应用多个指定的聚合函数
df.groupby(['A']).agg({'C':'max','D':'min'}).rename(columns={'C':'C_max','D':'D_min'})
|
| C_max | D_min |
| — | — | — |
| A |
|
|
| — | — | — |
| a | 139 | 22 |
| b | 177 | 50 |
两列分组
① 对多列分组后应用sum聚合函数:
df.groupby(['A', 'B']).sum()
|
|
| C | D |
| — | — | — | — |
| A | B |
|
|
| — | — | — | — |
| a | L | 107 | 22 |
| M | 191 | 98 |
| b | L | 177 | 59 |
| M | 38 | 82 |
| N | 3 | 50 |
② 对两列进行group 后,都应用max聚合函数
df.groupby(['A','B']).agg({'C':'max'}).rename(columns={'C': 'C_max'})
|
|
| C_max |
| — | — | — |
| A | B |
|
| — | — | — |
| a | L | 107 |
| M | 139 |
| b | L | 177 |
| M | 38 |
| N | 3 |
③ 对两列进行分组group 后,分别应用max、min聚合函数
df.groupby(['A','B']).agg({'C':'max','D':'min'}).rename(columns={'C':'C_max','D':'D_min'})
|
|
| C_max | D_min |
| — | — | — | — |
| A | B |
|
|
| — | — | — | — |
| a | L | 107 | 22 |
| M | 139 | 38 |
| b | L | 177 | 59 |
| M | 38 | 82 |
| N | 3 | 50 |
补充1: 应用自定义的聚合函数
df = pd.DataFrame({'A': ['a', 'b', 'a', 'b','a', 'b'], 'B': ['L', 'L', 'M', 'N','M', 'M'], 'C': [107, 177, 139, 3, 52, 38], 'D': [22, 59, 38, 50, 60, 82]}) df
|
| A | B | C | D |
| — | — | — | — | — |
| 0 | a | L | 107 | 22 |
| 1 | b | L | 177 | 59 |
| 2 | a | M | 139 | 38 |
| 3 | b | N | 3 | 50 |
| 4 | a | M | 52 | 60 |
| 5 | b | M | 38 | 82 |
# 使用自定义的聚合函数计算每个分组的最大值和最小值 def custom_agg(x): return x.max() - x.min() result = df[['B','C']].groupby('B').agg({'C': custom_agg}) result
|
| C |
| — | — |
| B |
|
| — | — |
| L | 70 |
| M | 101 |
| N | 0 |
补充2: 开窗函数(类似于SQL里面的over partition by):
使用transform函数计算每个分组的均值
# 使用transform函数计算每个分组的均值 df['B_C_std'] = df[['B','C']].groupby('B')['C'].transform('mean') df
|
| A | B | C | D | B_C_std |
| — | — | — | — | — | — |
| 0 | a | L | 107 | 22 | 142.000000 |
| 1 | b | L | 177 | 59 | 142.000000 |
| 2 | a | M | 139 | 38 | 76.333333 |
| 3 | b | N | 3 | 50 | 3.000000 |
| 4 | a | M | 52 | 60 | 76.333333 |
| 5 | b | M | 38 | 82 | 76.333333 |
补充3: 分组聚合拼接字符串 pandas实现类似 group_concat 功能
假设有这样一个数据:
df = pd.DataFrame({ '姓名': ['张三', '张三', '张三', '李四', '李四', '李四'], '科目': ['语文', '数学', '英语', '语文', '数学', '英语'] }) df
|
| 姓名 | 科目 |
| — | — | — |
| 0 | 张三 | 语文 |
| 1 | 张三 | 数学 |
| 2 | 张三 | 英语 |
| 3 | 李四 | 语文 |
| 4 | 李四 | 数学 |
| 5 | 李四 | 英语 |
补充:按某列分组,将另一列文本拼接合并
按名称分组,把每个人的科目拼接到一个字符串:
# 对整个group对象中的所有列应用join 连接元素 (df.astype(str)# 先将数据全转为字符 .groupby('姓名')# 分组 .agg(lambda x : ','.join(x)))[['科目']]# join 连接元素
|
| 科目 |
| — | — |
| 姓名 |
|
| — | — |
| 张三 | 语文,数学,英语 |
| 李四 | 语文,数学,英语 |
第2节 8-1 Pandas 数据重塑 - 数据变形
=============================
数据重塑(Reshaping)
数据重塑,顾名思义就是给数据做各种变形,主要有以下几种:
-
df.pivot 数据变形
-
df.pivot_table 数据透视表
-
df.stack/unstack 数据堆叠
-
df.melt 数据融合
-
df.cross 数据交叉表
df.pivot( ) 数据变形
根据索引(index)、列(column)(values)值), 对原有DataFrame(数据框)进行变形重塑,俗称长表转宽表

import pandas as pd import numpy as np
df = pd.DataFrame( { '姓名': ['张三', '张三', '张三', '李四', '李四', '李四'], '科目': ['语文', '数学', '英语', '语文', '数学', '英语'], '成绩': [91, 80, 100, 80, 100, 96]}) df
|
| 姓名 | 科目 | 成绩 |
| — | — | — | — |
| 0 | 张三 | 语文 | 91 |
| 1 | 张三 | 数学 | 80 |
| 2 | 张三 | 英语 | 100 |
| 3 | 李四 | 语文 | 80 |
| 4 | 李四 | 数学 | 100 |
| 5 | 李四 | 英语 | 96 |
长转宽:使用 df.pivot 以姓名为index,以各科目为columns,来统计各科成绩:
df = pd.DataFrame( { '姓名': ['张三', '张三', '张三', '李四', '李四', '李四'], '科目': ['语文', '数学', '英语', '语文', '数学', '英语'], '成绩': [91, 80, 100, 80, 100, 96]}) df
|
| 姓名 | 科目 | 成绩 |
| — | — | — | — |
| 0 | 张三 | 语文 | 91 |
| 1 | 张三 | 数学 | 80 |
| 2 | 张三 | 英语 | 100 |
| 3 | 李四 | 语文 | 80 |
| 4 | 李四 | 数学 | 100 |
| 5 | 李四 | 英语 | 96 |
df.pivot(index='姓名', columns='科目', values='成绩')
| 科目 | 数学 | 英语 | 语文 |
|---|---|---|---|
| 姓名 | |||
| — | — | — | — |
| 张三 | 80 | 100 | 91 |
| 李四 | 100 | 96 | 80 |
pd.melt() 数据融合

df = pd.DataFrame( { '姓名': ['张三', '张三', '张三', '李四', '李四', '李四'], '科目': ['语文', '数学', '英语', '语文', '数学', '英语'], '成绩': [91, 80, 100, 80, 100, 96]}) df1 = pd.pivot(df, index='姓名', columns='科目', values='成绩').reset_index() df1
| 科目 | 姓名 | 数学 | 英语 | 语文 |
|---|---|---|---|---|
| 0 | 张三 | 80 | 100 | 91 |
| 1 | 李四 | 100 | 96 | 80 |
宽表变长表:使用 df.pivot 以姓名为标识变量的列id_vars,以各科目为value_vars,来统计各科成绩:
df1.melt(id_vars=['姓名'], value_vars=['数学', '英语', '语文'])
|
| 姓名 | 科目 | value |
| — | — | — | — |
| 0 | 张三 | 数学 | 80 |
| 1 | 李四 | 数学 | 100 |
| 2 | 张三 | 英语 | 100 |
| 3 | 李四 | 英语 | 96 |
| 4 | 张三 | 语文 | 91 |
| 5 | 李四 | 语文 | 80 |
pd.pivot_table() 数据透视
random.seed(1024) df = pd.DataFrame( {'专业': np.repeat(['数学与应用数学', '计算机', '统计学'], 4), '班级': ['1班','1班','2班','2班']*3, '科目': ['高数', '线代'] * 6, '平均分': [random.randint(60,100) for i in range(12)], '及格人数': [random.randint(30,50) for i in range(12)]}) df
|
| 专业 | 班级 | 科目 | 平均分 | 及格人数 |
| — | — | — | — | — | — |
| 0 | 数学与应用数学 | 1班 | 高数 | 61 | 34 |
| 1 | 数学与应用数学 | 1班 | 线代 | 90 | 42 |
| 2 | 数学与应用数学 | 2班 | 高数 | 84 | 33 |
| 3 | 数学与应用数学 | 2班 | 线代 | 80 | 43 |
| 4 | 计算机 | 1班 | 高数 | 93 | 34 |
| 5 | 计算机 | 1班 | 线代 | 66 | 43 |
| 6 | 计算机 | 2班 | 高数 | 88 | 45 |
| 7 | 计算机 | 2班 | 线代 | 92 | 44 |
| 8 | 统计学 | 1班 | 高数 | 83 | 46 |
| 9 | 统计学 | 1班 | 线代 | 83 | 41 |
| 10 | 统计学 | 2班 | 高数 | 84 | 49 |
| 11 | 统计学 | 2班 | 线代 | 66 | 49 |
各个专业对应科目的及格人数和平均分
pd.pivot_table(df, index=['专业','科目'], values=['及格人数','平均分'], aggfunc={'及格人数':np.sum,"平均分":np.mean})
|
|
| 及格人数 | 平均分 |
| — | — | — | — |
| 专业 | 科目 |
|
|
| — | — | — | — |
| 数学与应用数学 | 线代 | 85 | 85.0 |
| 高数 | 67 | 72.5 |
| 统计学 | 线代 | 90 | 74.5 |
| 高数 | 95 | 83.5 |
| 计算机 | 线代 | 87 | 79.0 |
| 高数 | 79 | 90.5 |
补充说明:
df.pivot_table()和df.pivot()都是Pandas中用于将长表转换为宽表的方法,但它们在使用方式和功能上有一些区别。
- 使用方式:
-
df.pivot()方法接受三个参数:index、columns和values,分别指定新表的索引、列和值。 -
df.pivot_table()方法接受多个参数,其中最重要的是index、columns和values,用于指定新表的索引、列和值。此外,还可以使用aggfunc参数指定对重复值进行聚合操作的函数,默认为均值。
- 处理重复值:
-
df.pivot()方法在长表中存在重复值时会引发错误。因此,如果长表中存在重复值,就需要先进行去重操作,或者使用其他方法来处理重复值。 -
df.pivot_table()方法可以在长表中存在重复值的情况下进行透视操作,并可以使用aggfunc参数指定对重复值进行聚合操作的函数,默认为均值。
- 聚合操作:
-
df.pivot()方法不支持对重复值进行聚合操作,它只是简单地将长表中的数据转换为宽表。 -
df.pivot_table()方法支持对重复值进行聚合操作。可以使用aggfunc参数来指定聚合函数,例如求均值、求和、计数等。
总的来说,df.pivot()方法适用于长表中不存在重复值的情况,而df.pivot_table()方法适用于长表中存在重复值的情况,并且可以对重复值进行聚合操作。根据具体的数据结构和分析需求,选择合适的方法来进行转换操作。
第2节 8-2 Pandas 数据重塑 - 数据堆叠
数据堆叠
df = pd.DataFrame({'专业': np.repeat(['数学与应用数学', '计算机', '统计学','物理学'], 6), '班级': ['1班','2班','3班']*8, '科目': ['高数', '线代'] * 12, '平均分': [random.randint(60,100) for i in range(24)], '及格人数': [random.randint(30,50) for i in range(24)]}) df2 = pd.pivot_table(df, index=['专业','科目'], values=['及格人数','平均分'], aggfunc={'及格人数':np.sum,"平均分":np.mean}) df2
|
|
| 及格人数 | 平均分 |
| — | — | — | — |
| 专业 | 科目 |
|
|
| — | — | — | — |
| 数学与应用数学 | 线代 | 107 | 76.000000 |
| 高数 | 107 | 65.000000 |
| 物理学 | 线代 | 111 | 82.333333 |
| 高数 | 115 | 78.666667 |
| 统计学 | 线代 | 107 | 71.000000 |
| 高数 | 122 | 74.000000 |
| 计算机 | 线代 | 122 | 78.333333 |
| 高数 | 137 | 74.000000 |
stacked = df2.stack()
“压缩”后的DataFrame或Series(具有MultiIndex作为索引), stack() 的逆操作是unstack(),默认情况下取消最后压缩的那个级别:
堆叠stack(),顾名思义就是把透视结果堆到一起。接下来我们把透视后堆叠的数据一步步展开unstack():
stacked.unstack()
|
|
| 及格人数 | 平均分 |
| — | — | — | — |
| 专业 | 科目 |
|
|
| — | — | — | — |
| 数学与应用数学 | 线代 | 107.0 | 76.000000 |
| 高数 | 107.0 | 65.000000 |
| 物理学 | 线代 | 111.0 | 82.333333 |
| 高数 | 115.0 | 78.666667 |
| 统计学 | 线代 | 107.0 | 71.000000 |
| 高数 | 122.0 | 74.000000 |
| 计算机 | 线代 | 122.0 | 78.333333 |
| 高数 | 137.0 | 74.000000 |
stacked.unstack(level=1)
|
| 科目 | 线代 | 高数 |
| — | — | — | — |
| 专业 |
|
|
|
| — | — | — | — |
| 数学与应用数学 | 及格人数 | 107.000000 | 107.000000 |
| 平均分 | 76.000000 | 65.000000 |
| 物理学 | 及格人数 | 111.000000 | 115.000000 |
| 平均分 | 82.333333 | 78.666667 |
| 统计学 | 及格人数 | 107.000000 | 122.000000 |
| 平均分 | 71.000000 | 74.000000 |
| 计算机 | 及格人数 | 122.000000 | 137.000000 |
| 平均分 | 78.333333 | 74.000000 |
stacked.unstack(level=0)
|
| 专业 | 数学与应用数学 | 物理学 | 统计学 | 计算机 |
| — | — | — | — | — | — |
| 科目 |
|
|
|
|
|
| — | — | — | — | — | — |
| 线代 | 及格人数 | 107.0 | 111.000000 | 107.0 | 122.000000 |
| 平均分 | 76.0 | 82.333333 | 71.0 | 78.333333 |
| 高数 | 及格人数 | 107.0 | 115.000000 | 122.0 | 137.000000 |
| 平均分 | 65.0 | 78.666667 | 74.0 | 74.000000 |
第2节 8-3 Pandas 数据重塑 - 数据交叉表
数据交叉表
交叉表显示了每个变量的不同类别组合中观察到的频率或计数。通俗地说,就是根据不同列的数据统计了频数
df = pd.DataFrame( { 'High': ["高", "高", "高", "中", "中", "中", "低", "低", "低", "高", "低"], 'Weight': ["重", "轻", "中", "中", "轻", "重", "重", "轻", "中", "重", "轻"] }) df
`pd.crosstab(df['High'], df['Weight'])`
| Weight | 中 | 轻 | 重 |
|---|---|---|---|
| High | |||
| — | — | — | — |
| 中 | 1 | 1 | 1 |
| 低 | 1 | 2 | 1 |
| 高 | 1 | 1 | 2 |
双层crosstab
df = pd.DataFrame( { 'High': ["高", "高", "高", "中", "中", "中", "低", "低", "低", "高", "低"], 'Weight': ["重", "轻", "中", "中", "轻", "重", "重", "轻", "中", "重", "轻"], 'Size': ["大", "中", "小", "中", "中", "大", "中", "小", "小", "大", "小"]}) df
|
| High | Weight | Size |
| — | — | — | — |
| 0 | 高 | 重 | 大 |
| 1 | 高 | 轻 | 中 |
| 2 | 高 | 中 | 小 |
| 3 | 中 | 中 | 中 |
| 4 | 中 | 轻 | 中 |
| 5 | 中 | 重 | 大 |
| 6 | 低 | 重 | 中 |
| 7 | 低 | 轻 | 小 |
| 8 | 低 | 中 | 小 |
| 9 | 高 | 重 | 大 |
| 10 | 低 | 轻 | 小 |
`pd.crosstab(df['High'], [df['Weight'], df['Size']], rownames=['High'], colnames=['Weight', 'Size'])`
| Weight | 中 | 轻 | 重 |
|---|---|---|---|
| Size | 中 | 小 | 中 |
| — | — | — | — |
| High | |||
| — | — | — | — |
| 中 | 1 | 0 | 1 |
| 低 | 0 | 1 | 0 |
| 高 | 0 | 1 | 1 |
另一种 宽表转长表 pd.wide_to_long()
np.random.seed(123) df = pd.DataFrame({"A1970" : {0 : "a", 1 : "b", 2 : "c"}, "A1980" : {0 : "d", 1 : "e", 2 : "f"}, "B1970" : {0 : 2.5, 1 : 1.2, 2 : .7}, "B1980" : {0 : 3.2, 1 : 1.3, 2 : .1}, "X" : dict(zip(range(3), np.random.randn(3))) }) df["id"] = df.index df
|
| A1970 | A1980 | B1970 | B1980 | X | id |
| — | — | — | — | — | — | — |
| 0 | a | d | 2.5 | 3.2 | -1.085631 | 0 |
| 1 | b | e | 1.2 | 1.3 | 0.997345 | 1 |
| 2 | c | f | 0.7 | 0.1 | 0.282978 | 2 |
把id 列用作标识列
pd.wide_to_long(df, ["A", "B"], i="id", j="year")
|
|
| X | A | B |
| — | — | — | — | — |
| id | year |
|
|
|
| — | — | — | — | — |
| 0 | 1970 | -1.085631 | a | 2.5 |
| 1 | 1970 | 0.997345 | b | 1.2 |
| 2 | 1970 | 0.282978 | c | 0.7 |
| 0 | 1980 | -1.085631 | d | 3.2 |
| 1 | 1980 | 0.997345 | e | 1.3 |
| 2 | 1980 | 0.282978 | f | 0.1 |
df = pd.DataFrame({ 'famid': [1, 1, 1, 2, 2, 2, 3, 3, 3], 'birth': [1, 2, 3, 1, 2, 3, 1, 2, 3], 'ht1': [2.8, 2.9, 2.2, 2, 1.8, 1.9, 2.2, 2.3, 2.1], 'ht2': [3.4, 3.8, 2.9, 3.2, 2.8, 2.4, 3.3, 3.4, 2.9] }) df
|
| famid | birth | ht1 | ht2 |
| — | — | — | — | — |
| 0 | 1 | 1 | 2.8 | 3.4 |
| 1 | 1 | 2 | 2.9 | 3.8 |
| 2 | 1 | 3 | 2.2 | 2.9 |
| 3 | 2 | 1 | 2.0 | 3.2 |
| 4 | 2 | 2 | 1.8 | 2.8 |
| 5 | 2 | 3 | 1.9 | 2.4 |
| 6 | 3 | 1 | 2.2 | 3.3 |
| 7 | 3 | 2 | 2.3 | 3.4 |
| 8 | 3 | 3 | 2.1 | 2.9 |
把famid, birth 两列用作标识列
l = pd.wide_to_long(df, stubnames='ht', i=['famid', 'birth'], j='age') l
|
|
|
| ht |
| — | — | — | — |
| famid | birth | age |
|
| — | — | — | — |
| 1 | 1 | 1 | 2.8 |
| 2 | 3.4 |
| 2 | 1 | 2.9 |
| 2 | 3.8 |
| 3 | 1 | 2.2 |
| 2 | 2.9 |
| 2 | 1 | 1 | 2.0 |
| 2 | 3.2 |
| 2 | 1 | 1.8 |
| 2 | 2.8 |
| 3 | 1 | 1.9 |
| 2 | 2.4 |
| 3 | 1 | 1 | 2.2 |
| 2 | 3.3 |
| 2 | 1 | 2.3 |
| 2 | 3.4 |
| 3 | 1 | 2.1 |
| 2 | 2.9 |
第3节 9 Pandas 文本数据
import pandas as pd
1、cat() 拼接字符串
d = pd.DataFrame(['a', 'b', 'c'],columns = ['A']) d
|
| A |
| — | — |
| 0 | a |
| 1 | b |
| 2 | c |
将某列元素拼接一列特定字符串
d['A'].str.cat(['A', 'B', 'C'], sep=',')
0 a,A
1 b,B
2 c,C
Name: A, dtype: object
将某列的元素合并为一个字符串
d['A'].str.cat(sep=',')
'a,b,c'
2、split() 切分字符串
import numpy as np import pandas as pd d = pd.DataFrame(['a_b_c', 'c_d_e', np.nan, 'f_g_h'],columns = ['A']) d
|
| A |
| — | — |
| 0 | a_b_c |
| 1 | c_d_e |
| 2 | NaN |
| 3 | f_g_h |
将某列的字符串元素进行切分
d['A'].str.split('_')
0 [a, b, c]
1 [c, d, e]
2 NaN
3 [f, g, h]
Name: A, dtype: object
3、get() 获取指定位置的字符串
d = pd.DataFrame(['a_b_c', 'c_d_e', np.nan, 'f_g_h'],columns = ['A']) d['A']
0 a_b_c
1 c_d_e
2 NaN
3 f_g_h
Name: A, dtype: object
d['A'].str.get(2)
0 b
1 d
2 NaN
3 g
Name: A, dtype: object
4、join() 对每个字符都用给定的字符串拼接起来(不常用)
d = pd.DataFrame(['a_b_c', 'c_d_e', np.nan, 'f_g_h'],columns = ['A']) d['A']
0 a_b_c
1 c_d_e
2 NaN
3 f_g_h
Name: A, dtype: object
d['A'].str.join("!")
0 a!_!b!_!c
1 c!_!d!_!e
2 NaN
3 f!_!g!_!h
Name: A, dtype: object
5、contains() 是否包含表达式 (很常用)
d['A'].str.contains('d')
0 False
1 True
2 NaN
3 False
Name: A, dtype: object
d.fillna('0')[d.fillna('0')['A'].str.contains('d')]
|
| A |
| — | — |
| 1 | c_d_e |
d.fillna('0')[d['A'].fillna('0').str.contains('d|e')] #表示或的关系用"A|B",表示且用'A.*B|B.*A'
|
| A |
| — | — |
| 1 | c_d_e |
6、replace() 替换
d['A'].str.replace("_", ".")
0 a.b.c
1 c.d.e
2 NaN
3 f.g.h
Name: A, dtype: object
7、repeat() 重复
d['A'].str.repeat(3)
0 a_b_ca_b_ca_b_c
1 c_d_ec_d_ec_d_e
2 NaN
3 f_g_hf_g_hf_g_h
Name: A, dtype: object
8、pad() 左右补齐
d['A'].str.pad(10, fillchar="0")
0 00000a_b_c
1 00000c_d_e
2 NaN
3 00000f_g_h
Name: A, dtype: object
d['A'].str.pad(10, side="right", fillchar="?")
0 a_b_c?????
1 c_d_e?????
2 NaN
3 f_g_h?????
Name: A, dtype: object
9、center() 中间补齐
d['A'].str.center(10, fillchar="?")
0 ??a_b_c???
1 ??c_d_e???
2 NaN
3 ??f_g_h???
Name: A, dtype: object
10、ljust() 右边补齐
d['A'].str.ljust(10, fillchar="?")
0 a_b_c?????
1 c_d_e?????
2 NaN
3 f_g_h?????
Name: A, dtype: object
11、rjust() 左边补齐
d['A'].str.rjust(10, fillchar="?")
0 ?????a_b_c
1 ?????c_d_e
2 NaN
3 ?????f_g_h
Name: A, dtype: object
12、zfill() 左边补0
d['A'].str.zfill(10)
0 00000a_b_c
1 00000c_d_e
2 NaN
3 00000f_g_h
Name: A, dtype: object
13、wrap() 在指定的位置加回车符号
d['A'].str.wrap(3)
0 a_b\n_c
1 c_d\n_e
2 NaN
3 f_g\n_h
Name: A, dtype: object
14、slice() 按给定点的开始结束位置切割字符串
d['A'].str.slice(1,3)
0 _b
1 _d
2 NaN
3 _g
Name: A, dtype: object
15、slice_replace() 使用给定的字符串,替换指定的位置的字符
d['A'].str.slice_replace(1, 3, "?")
0 a?_c
1 c?_e
2 NaN
3 f?_h
Name: A, dtype: object
16、count() 计算给定单词出现的次数
d['A'].str.count("b")
0 1.0
1 0.0
2 NaN
3 0.0
Name: A, dtype: float64
17、startswith() 判断是否以给定的字符串开头
d['A'].str.startswith("a")
0 True
1 False
2 NaN
3 False
Name: A, dtype: object
18、endswith() 判断是否以给定的字符串结束
d['A'].str.endswith("e")
0 False
1 True
2 NaN
3 False
Name: A, dtype: object
19、findall() 查找所有符合正则表达式的字符,以数组形式返回
d['A'].str.findall("[a-z]")
0 [a, b, c]
1 [c, d, e]
2 NaN
3 [f, g, h]
Name: A, dtype: object
20、match() 检测是否全部匹配给点的字符串或者表达式
d['A'].str.match("[d-z]")
0 False
1 False
2 NaN
3 True
Name: A, dtype: object
21、extract() 抽取匹配的字符串出来,注意要加上括号,把你需要抽取的东西标注上
d['A'].str.extract("([d-z])")
|
| 0 |
| — | — |
| 0 | NaN |
| 1 | d |
| 2 | NaN |
| 3 | f |
22、len() 计算字符串的长度
d['A'].str.len()
0 5.0
1 5.0
2 NaN
3 5.0
Name: A, dtype: float64
23、strip() 去除前后的空白字符
df = pd.DataFrame(['a_b ', ' d_e ', np.nan, 'f_g '],columns = ['B']) df['B']
0 a_b
1 d_e
2 NaN
3 f_g
Name: B, dtype: object
df['B'].str.strip()
0 a_b
1 d_e
2 NaN
3 f_g
Name: B, dtype: object
24、rstrip() 去除后面的空白字符
df['B'].str.rstrip()
0 a_b
1 d_e
2 NaN
3 f_g
Name: B, dtype: object
25、lstrip() 去除前面的空白字符
df['B'].str.lstrip()
0 a_b
1 d_e
2 NaN
3 f_g
Name: B, dtype: object
26、partition() 把字符串数组切割称为DataFrame,注意切割只是切割称为三部分,分隔符前,分隔符,分隔符后
d['A'] .str.partition('_')
|
| 0 | 1 | 2 |
| — | — | — | — |
| 0 | a | _ | b_c |
| 1 | c | _ | d_e |
| 2 | NaN | NaN | NaN |
| 3 | f | _ | g_h |
27、rpartition() 从右切起
d['A'].str.rpartition('_')
|
| 0 | 1 | 2 |
| — | — | — | — |
| 0 | a_b | _ | c |
| 1 | c_d | _ | e |
| 2 | NaN | NaN | NaN |
| 3 | f_g | _ | h |
28、lower() 全部小写
`d['A'].str.lower()`
0 a_b_c
1 c_d_e
2 NaN
3 f_g_h
Name: A, dtype: object
29、upper() 全部大写
`d['A'].str.upper()`
0 A_B_C
1 C_D_E
2 NaN
3 F_G_H
Name: A, dtype: object
30、find() 从左边开始,查找给定字符串的所在位置
d['A'].str.find('d')
0 -1.0
1 2.0
2 NaN
3 -1.0
Name: A, dtype: float64
31、rfind() 从右边开始,查找给定字符串的所在位置
d['A'].str.rfind('d')
0 -1.0
1 2.0
2 NaN
3 -1.0
Name: A, dtype: float64
32、index() 查找给定字符串的位置,注意,如果不存在这个字符串,那么会报错!
d['A'].str.index('_')
0 1.0
1 1.0
2 NaN
3 1.0
Name: A, dtype: float64
33、rindex() 从右边开始查找,给定字符串的位置
d['A'].str.rindex('_')
0 3.0
1 3.0
2 NaN
3 3.0
Name: A, dtype: float64
34、capitalize() 首字符大写
d['A'].str.capitalize()
0 A_b_c
1 C_d_e
2 NaN
3 F_g_h
Name: A, dtype: object
35、swapcase() 大小写互换
d['A'].str.capitalize()
0 A_b_c
1 C_d_e
2 NaN
3 F_g_h
Name: A, dtype: object
36、isalnum() 是否全部是数字和字母组成
d['A'].str.isalnum()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
37、isalpha() 是否全部是字母
d['A'].str.isalpha()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
38、isdigit() 是否全部都是数字
d['A'].str.isdigit()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
39、isspace() 是否空格
d['A'].str.isspace()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
40、islower() 是否全部小写
d['A'].str.islower()
0 True
1 True
2 NaN
3 True
Name: A, dtype: object
41、isupper() 是否全部大写
d['A'].str.isupper()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
42、istitle() 是否只有首字母为大写,其他字母为小写
d['A'].str.istitle()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
43、isnumeric() 是否是数字
d['A'].str.isnumeric()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
44、isdecimal() 是否全是数字
d['A'].str.isdecimal()
0 False
1 False
2 NaN
3 False
Name: A, dtype: object
第3节 10 Pandas 时序数据
在Pandas中,时间序列(Time Series)是一种特殊的数据类型,用于处理时间相关的数据。Pandas提供了丰富的功能和方法,方便对时间序列数据进行处理和分析。下面是一些针对时间序列的常用操作:
创建时间序列数据
方式① 使用to_datetime创建时间序列:直接传入列表即可
import pandas as pd # 将列表转换为时间戳 date_range = pd.to_datetime(['2024-01-01', '2024-01-02', '2024-01-03']) date_range
DatetimeIndex(['2024-01-01', '2024-01-02', '2024-01-03'], dtype='datetime64[ns]', freq=None)
方式② 使用pd.date_range()创建一段连续的时间范围:使用指定参数即可
import pandas as pd date_range = pd.date_range(start='2024-01-01', end='2024-12-31', freq='D') date_range
DatetimeIndex(['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04',
'2024-01-05', '2024-01-06', '2024-01-07', '2024-01-08',
'2024-01-09', '2024-01-10',
...
'2024-12-22', '2024-12-23', '2024-12-24', '2024-12-25',
'2024-12-26', '2024-12-27', '2024-12-28', '2024-12-29',
'2024-12-30', '2024-12-31'],
dtype='datetime64[ns]', length=366, freq='D')
其中,start是起始日期,end是结束日期,freq是频率,这里设置为’D’表示每天。
方式③ 使用Timestamp()函数创建一个特定的时间戳:使用指定参数即可
import pandas as pd timestamp = pd.Timestamp(year=2023, month=1, day=1, hour=12, minute=30, second=45) timestamp
Timestamp('2023-01-01 12:30:45')
方式④ 使用 datetime 模块创建时间戳:使用指定参数即可
import pandas as pd from datetime import datetime timestamp = datetime(2023, 1, 1, 12, 30, 45) print(timestamp)
2023-01-01 12:30:45
时长数据计算
计算一下两个时间数据之差
`import pandas as pd # 创建两个固定时间 start_time = pd.Timestamp('2024-01-01 12:00:00') end_time = pd.Timestamp('2024-01-02 14:30:00') # 计算时间差 time_diff = end_time - start_time time_diff`
Timedelta('1 days 02:30:00')
一个固定时间加上pd.Timedelta类型的时间差
pd.Timestamp('2024-01-02 14:30:00')+pd.Timedelta('1 days 02:30:00')
Timestamp('2024-01-03 17:00:00')
时序索引
接下来,我们看看日期做索引的情况
将日期作为索引创建时间序列:
import pandas as pd data = [1, 2, 3, 4, 5] dates = pd.date_range(start='2024-01-01', periods=5, freq='D') ts = pd.Series(data, index=dates) ts
2024-01-01 1
2024-01-02 2
2024-01-03 3
2024-01-04 4
2024-01-05 5
Freq: D, dtype: int64
其中,periods是时间序列的长度,freq是频率,这里设置为’D’表示每天。
时间序列的索引和切片:使用日期进行索引:
import pandas as pd ts['2024-01-01']
1
使用日期范围进行切片:
import pandas as pd ts['2024-01-01':'2024-01-05']
2024-01-01 1
2024-01-02 2
2024-01-03 3
2024-01-04 4
2024-01-05 5
Freq: D, dtype: int64
也可以使用切片操作对数据进行访问
import pandas as pd ts[1:4]
2024-01-02 2
2024-01-03 3
2024-01-04 4
Freq: D, dtype: int64
时间序列的重采样:将时间序列从高频率转换为低频率:
import pandas as pd ts.resample('W').mean()
2024-01-07 3.0
Freq: W-SUN, dtype: float64
其中,'W’表示按周进行重采样,mean()表示计算每周的平均值。
时间序列的滚动计算:计算滚动平均值:
import pandas as pd ts.rolling(window=3).mean()
2024-01-01 NaN
2024-01-02 NaN
2024-01-03 2.0
2024-01-04 3.0
2024-01-05 4.0
Freq: D, dtype: float64
其中,window=3表示窗口大小为3,即计算每3个数据的平均值。
时间序列的时间偏移:将时间序列向前或向后移动:
import pandas as pd ts.shift(1)
2024-01-01 NaN
2024-01-02 1.0
2024-01-03 2.0
2024-01-04 3.0
2024-01-05 4.0
Freq: D, dtype: float64
其中,1表示向后移动1个时间单位。
时间访问器dt
在 Pandas 中,可以使用 dt 访问器来访问时间戳或时间序列中的各个时间部分,例如年、月、日、小时、分钟、秒等。通过使用 dt 访问器,你可以方便地提取和操作时间信息。
下面是一些常用的 dt 访问器的示例:
import pandas as pd # 创建一个时间序列 timestamps = pd.Series(pd.date_range('2023-01-01', periods=5, freq='D')) timestamps
0 2023-01-01
1 2023-01-02
2 2023-01-03
3 2023-01-04
4 2023-01-05
dtype: datetime64[ns]
# 提取年份 year = timestamps.dt.year year
0 2023
1 2023
2 2023
3 2023
4 2023
dtype: int64
# 提取月份 month = timestamps.dt.month month
0 1
1 1
2 1
3 1
4 1
dtype: int64
# 提取日期 day = timestamps.dt.day day
0 1
1 2
2 3
3 4
4 5
dtype: int64
# 提取小时 hour = timestamps.dt.hour hour
0 0
1 0
2 0
3 0
4 0
dtype: int64
# 提取分钟 minute = timestamps.dt.minute minute
0 0
1 0
2 0
3 0
4 0
dtype: int64
# 提取秒数 second = timestamps.dt.second second
0 0
1 0
2 0
3 0
4 0
dtype: int64
# 获取季度 quarter = timestamps.dt.quarter quarter
0 1
1 1
2 1
3 1
4 1
dtype: int64
# 获取周数 week = timestamps.dt.isocalendar().week week
0 52
1 1
2 1
3 1
4 1
Name: week, dtype: UInt32
# 获取星期几的名称 day_name = timestamps.dt.day_name() day_name
0 Sunday
1 Monday
2 Tuesday
3 Wednesday
4 Thursday
dtype: object
# 获取该日期是一年中的第几天 day_of_year = timestamps.dt.dayofyear day_of_year
0 1
1 2
2 3
3 4
4 5
dtype: int64
# 获取该日期是一周中的第几天(星期一为1,星期日为7) day_of_week = timestamps.dt.dayofweek + 1 day_of_week
0 7
1 1
2 2
3 3
4 4
dtype: int64
# 获取该日期是一个月中的第几天 day_of_month = timestamps.dt.day day_of_month
0 1
1 2
2 3
3 4
4 5
dtype: int64
# 获取该日期所在月份的最后一天 end_of_month = timestamps.dt.daysinmonth end_of_month
0 31
1 31
2 31
3 31
4 31
dtype: int64
时长转化
import pandas as pd # 创建时间戳序列 ts = pd.Series(pd.to_timedelta(np.arange(10),unit='m')) ts
0 0 days 00:00:00
1 0 days 00:01:00
2 0 days 00:02:00
3 0 days 00:03:00
4 0 days 00:04:00
5 0 days 00:05:00
6 0 days 00:06:00
7 0 days 00:07:00
8 0 days 00:08:00
9 0 days 00:09:00
dtype: timedelta64[ns]
# 提取时间戳中的秒数 seconds = ts.dt.seconds seconds
0 0
1 60
2 120
3 180
4 240
5 300
6 360
7 420
8 480
9 540
dtype: int64
seconds = ts.dt.to_pytimedelta() seconds
array([datetime.timedelta(0), datetime.timedelta(seconds=60),
datetime.timedelta(seconds=120), datetime.timedelta(seconds=180),
datetime.timedelta(seconds=240), datetime.timedelta(seconds=300),
datetime.timedelta(seconds=360), datetime.timedelta(seconds=420),
datetime.timedelta(seconds=480), datetime.timedelta(seconds=540)],
dtype=object)
以上是Pandas针对时间序列的一些常用操作和示例代码
第3节 11 Pandas 窗口数据
Pandas提供了窗口函数(Window Functions)用于在数据上执行滑动窗口操作,可以对数据进行滚动计算、滑动统计等操作。下面是一些常用的窗口函数:
滚动计算函数:移动平均值(Moving Average):
import pandas as pd data = {'column': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]} df = pd.DataFrame(data) df
|
| column |
| — | — |
| 0 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
| 6 | 7 |
| 7 | 8 |
| 8 | 9 |
| 9 | 10 |
df['MA'] = df['column'].rolling(window=3).mean() df
|
| column | MA |
| — | — | — |
| 0 | 1 | NaN |
| 1 | 2 | NaN |
| 2 | 3 | 2.0 |
| 3 | 4 | 3.0 |
| 4 | 5 | 4.0 |
| 5 | 6 | 5.0 |
| 6 | 7 | 6.0 |
| 7 | 8 | 7.0 |
| 8 | 9 | 8.0 |
| 9 | 10 | 9.0 |
其中,window=3表示窗口大小为3,即计算每3个数据的平均值。
滚动求和(Rolling Sum):
import pandas as pd df['Sum'] = df['column'].rolling(window=5).sum() df
|
| column | MA | Sum |
| — | — | — | — |
| 0 | 1 | NaN | NaN |
| 1 | 2 | NaN | NaN |
| 2 | 3 | 2.0 | NaN |
| 3 | 4 | 3.0 | NaN |
| 4 | 5 | 4.0 | 15.0 |
| 5 | 6 | 5.0 | 20.0 |
| 6 | 7 | 6.0 | 25.0 |
| 7 | 8 | 7.0 | 30.0 |
| 8 | 9 | 8.0 | 35.0 |
| 9 | 10 | 9.0 | 40.0 |
其中,window=5表示窗口大小为5,即计算每5个数据的和。
滑动统计函数:滑动最大值(Rolling Maximum):
import pandas as pd df['Max'] = df['column'].rolling(window=7).max() df
|
| column | MA | Sum | Max |
| — | — | — | — | — |
| 0 | 1 | NaN | NaN | NaN |
| 1 | 2 | NaN | NaN | NaN |
| 2 | 3 | 2.0 | NaN | NaN |
| 3 | 4 | 3.0 | NaN | NaN |
| 4 | 5 | 4.0 | 15.0 | NaN |
| 5 | 6 | 5.0 | 20.0 | NaN |
| 6 | 7 | 6.0 | 25.0 | 7.0 |
| 7 | 8 | 7.0 | 30.0 | 8.0 |
| 8 | 9 | 8.0 | 35.0 | 9.0 |
| 9 | 10 | 9.0 | 40.0 | 10.0 |
其中,window=7表示窗口大小为7,即计算每7个数据的最大值。
滑动最小值(Rolling Minimum):
import pandas as pd df['Min'] = df['column'].rolling(window=7).min() df
|
| column | MA | Sum | Max | Min |
| — | — | — | — | — | — |
| 0 | 1 | NaN | NaN | NaN | NaN |
| 1 | 2 | NaN | NaN | NaN | NaN |
| 2 | 3 | 2.0 | NaN | NaN | NaN |
| 3 | 4 | 3.0 | NaN | NaN | NaN |
| 4 | 5 | 4.0 | 15.0 | NaN | NaN |
| 5 | 6 | 5.0 | 20.0 | NaN | NaN |
| 6 | 7 | 6.0 | 25.0 | 7.0 | 1.0 |
| 7 | 8 | 7.0 | 30.0 | 8.0 | 2.0 |
| 8 | 9 | 8.0 | 35.0 | 9.0 | 3.0 |
| 9 | 10 | 9.0 | 40.0 | 10.0 | 4.0 |
其中,window=7表示窗口大小为7,即计算每7个数据的最小值。
滑动标准差(Rolling Standard Deviation):
import pandas as pd df['Std'] = df['column'].rolling(window=5).std() df
|
| column | MA | Sum | Max | Min | Std |
| — | — | — | — | — | — | — |
| 0 | 1 | NaN | NaN | NaN | NaN | NaN |
| 1 | 2 | NaN | NaN | NaN | NaN | NaN |
| 2 | 3 | 2.0 | NaN | NaN | NaN | NaN |
| 3 | 4 | 3.0 | NaN | NaN | NaN | NaN |
| 4 | 5 | 4.0 | 15.0 | NaN | NaN | 1.581139 |
| 5 | 6 | 5.0 | 20.0 | NaN | NaN | 1.581139 |
| 6 | 7 | 6.0 | 25.0 | 7.0 | 1.0 | 1.581139 |
| 7 | 8 | 7.0 | 30.0 | 8.0 | 2.0 | 1.581139 |
| 8 | 9 | 8.0 | 35.0 | 9.0 | 3.0 | 1.581139 |
| 9 | 10 | 9.0 | 40.0 | 10.0 | 4.0 | 1.581139 |
其中,window=5表示窗口大小为5,即计算每5个数据的标准差。
自定义窗口函数:可以使用rolling().apply()方法来应用自定义的窗口函数:
import pandas as pd def custom_function(data): # 自定义的窗口函数逻辑 return max(data) - min(data) df['Result'] =df['column'].rolling(window=3).apply(custom_function) df
|
| column | MA | Sum | Max | Min | Std | Result |
| — | — | — | — | — | — | — | — |
| 0 | 1 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 2 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 3 | 2.0 | NaN | NaN | NaN | NaN | 2.0 |
| 3 | 4 | 3.0 | NaN | NaN | NaN | NaN | 2.0 |
| 4 | 5 | 4.0 | 15.0 | NaN | NaN | 1.581139 | 2.0 |
| 5 | 6 | 5.0 | 20.0 | NaN | NaN | 1.581139 | 2.0 |
| 6 | 7 | 6.0 | 25.0 | 7.0 | 1.0 | 1.581139 | 2.0 |
| 7 | 8 | 7.0 | 30.0 | 8.0 | 2.0 | 1.581139 | 2.0 |
| 8 | 9 | 8.0 | 35.0 | 9.0 | 3.0 | 1.581139 | 2.0 |
| 9 | 10 | 9.0 | 40.0 | 10.0 | 4.0 | 1.581139 | 2.0 |
其中,custom_function是自定义的窗口函数,data是窗口中的数据,result是窗口函数的计算结果。以上是Pandas窗口函数的一些常用操作和示例代码。需要注意的是,在使用窗口函数时,需要根据实际需求选择合适的窗口大小和窗口函数,并确保数据的顺序和窗口大小的一致性。
Pandas 数据读写
Pandas提供了多种读取数据的方法,包括读取CSV、Excel、SQL数据库等。
CSV
写出csv文件
import pandas as pd import numpy as np data = np.random.rand(10, 10) # 生成一个10行10列的随机数矩阵 columns = ['col' + str(i) for i in range(10)] # 列名为col0, col1, ..., col9 df = pd.DataFrame(data, columns=columns) df
|
| col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 |
| — | — | — | — | — | — | — | — | — | — | — |
| 0 | 0.466616 | 0.728356 | 0.611705 | 0.798693 | 0.595354 | 0.985732 | 0.586150 | 0.320381 | 0.335783 | 0.660817 |
| 1 | 0.712571 | 0.335545 | 0.523658 | 0.528449 | 0.666035 | 0.021001 | 0.947240 | 0.399122 | 0.281759 | 0.110816 |
| 2 | 0.175048 | 0.513420 | 0.067066 | 0.666860 | 0.377052 | 0.213377 | 0.175968 | 0.877383 | 0.587943 | 0.531723 |
| 3 | 0.034618 | 0.910112 | 0.131991 | 0.482421 | 0.579907 | 0.569939 | 0.641757 | 0.459544 | 0.546252 | 0.438100 |
| 4 | 0.112847 | 0.117470 | 0.360243 | 0.598008 | 0.210927 | 0.262409 | 0.540579 | 0.397511 | 0.142911 | 0.360057 |
| 5 | 0.228802 | 0.065476 | 0.327229 | 0.377131 | 0.021064 | 0.429451 | 0.366117 | 0.420715 | 0.977730 | 0.812894 |
| 6 | 0.134770 | 0.725406 | 0.159081 | 0.696428 | 0.525755 | 0.240271 | 0.959835 | 0.836452 | 0.189946 | 0.998590 |
| 7 | 0.176187 | 0.216828 | 0.444304 | 0.726939 | 0.334520 | 0.922983 | 0.668025 | 0.207854 | 0.870736 | 0.822457 |
| 8 | 0.506092 | 0.697873 | 0.296946 | 0.443291 | 0.671899 | 0.344138 | 0.502330 | 0.562803 | 0.304063 | 0.118550 |
| 9 | 0.991827 | 0.631362 | 0.552241 | 0.640401 | 0.156152 | 0.548396 | 0.831292 | 0.563461 | 0.221882 | 0.891689 |
df.to_csv('./output/foo.csv') # 请注意需要在你的代码文件夹目录下建一个\output 文件夹才能写入
读入刚刚写出的文件
pd.read_csv('./output/foo.csv')
|
| Unnamed: 0 | col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 |
| — | — | — | — | — | — | — | — | — | — | — | — |
| 0 | 0 | 0.466616 | 0.728356 | 0.611705 | 0.798693 | 0.595354 | 0.985732 | 0.586150 | 0.320381 | 0.335783 | 0.660817 |
| 1 | 1 | 0.712571 | 0.335545 | 0.523658 | 0.528449 | 0.666035 | 0.021001 | 0.947240 | 0.399122 | 0.281759 | 0.110816 |
| 2 | 2 | 0.175048 | 0.513420 | 0.067066 | 0.666860 | 0.377052 | 0.213377 | 0.175968 | 0.877383 | 0.587943 | 0.531723 |
| 3 | 3 | 0.034618 | 0.910112 | 0.131991 | 0.482421 | 0.579907 | 0.569939 | 0.641757 | 0.459544 | 0.546252 | 0.438100 |
| 4 | 4 | 0.112847 | 0.117470 | 0.360243 | 0.598008 | 0.210927 | 0.262409 | 0.540579 | 0.397511 | 0.142911 | 0.360057 |
| 5 | 5 | 0.228802 | 0.065476 | 0.327229 | 0.377131 | 0.021064 | 0.429451 | 0.366117 | 0.420715 | 0.977730 | 0.812894 |
| 6 | 6 | 0.134770 | 0.725406 | 0.159081 | 0.696428 | 0.525755 | 0.240271 | 0.959835 | 0.836452 | 0.189946 | 0.998590 |
| 7 | 7 | 0.176187 | 0.216828 | 0.444304 | 0.726939 | 0.334520 | 0.922983 | 0.668025 | 0.207854 | 0.870736 | 0.822457 |
| 8 | 8 | 0.506092 | 0.697873 | 0.296946 | 0.443291 | 0.671899 | 0.344138 | 0.502330 | 0.562803 | 0.304063 | 0.118550 |
| 9 | 9 | 0.991827 | 0.631362 | 0.552241 | 0.640401 | 0.156152 | 0.548396 | 0.831292 | 0.563461 | 0.221882 | 0.891689 |
EXCEL
写出excel文件
df.to_excel('./output/foo.xlsx', sheet_name='Sheet1',index = None)
读取excel文件
pd.read_excel('./output/foo.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
|
| col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 |
| — | — | — | — | — | — | — | — | — | — | — |
| 0 | 0.466616 | 0.728356 | 0.611705 | 0.798693 | 0.595354 | 0.985732 | 0.586150 | 0.320381 | 0.335783 | 0.660817 |
| 1 | 0.712571 | 0.335545 | 0.523658 | 0.528449 | 0.666035 | 0.021001 | 0.947240 | 0.399122 | 0.281759 | 0.110816 |
| 2 | 0.175048 | 0.513420 | 0.067066 | 0.666860 | 0.377052 | 0.213377 | 0.175968 | 0.877383 | 0.587943 | 0.531723 |
| 3 | 0.034618 | 0.910112 | 0.131991 | 0.482421 | 0.579907 | 0.569939 | 0.641757 | 0.459544 | 0.546252 | 0.438100 |
| 4 | 0.112847 | 0.117470 | 0.360243 | 0.598008 | 0.210927 | 0.262409 | 0.540579 | 0.397511 | 0.142911 | 0.360057 |
| 5 | 0.228802 | 0.065476 | 0.327229 | 0.377131 | 0.021064 | 0.429451 | 0.366117 | 0.420715 | 0.977730 | 0.812894 |
| 6 | 0.134770 | 0.725406 | 0.159081 | 0.696428 | 0.525755 | 0.240271 | 0.959835 | 0.836452 | 0.189946 | 0.998590 |
| 7 | 0.176187 | 0.216828 | 0.444304 | 0.726939 | 0.334520 | 0.922983 | 0.668025 | 0.207854 | 0.870736 | 0.822457 |
| 8 | 0.506092 | 0.697873 | 0.296946 | 0.443291 | 0.671899 | 0.344138 | 0.502330 | 0.562803 | 0.304063 | 0.118550 |
| 9 | 0.991827 | 0.631362 | 0.552241 | 0.640401 | 0.156152 | 0.548396 | 0.831292 | 0.563461 | 0.221882 | 0.891689 |
HDF
写出hdf文件
df.to_hdf('./output/foo.h5','df')
读入刚刚写出的文件
pd.read_hdf('./output/foo.h5','df').head()
|
| col0 | col1 | col2 | col3 | col4 | col5 | col6 | col7 | col8 | col9 |
| — | — | — | — | — | — | — | — | — | — | — |
| 0 | 0.466616 | 0.728356 | 0.611705 | 0.798693 | 0.595354 | 0.985732 | 0.586150 | 0.320381 | 0.335783 | 0.660817 |
| 1 | 0.712571 | 0.335545 | 0.523658 | 0.528449 | 0.666035 | 0.021001 | 0.947240 | 0.399122 | 0.281759 | 0.110816 |
| 2 | 0.175048 | 0.513420 | 0.067066 | 0.666860 | 0.377052 | 0.213377 | 0.175968 | 0.877383 | 0.587943 | 0.531723 |
| 3 | 0.034618 | 0.910112 | 0.131991 | 0.482421 | 0.579907 | 0.569939 | 0.641757 | 0.459544 | 0.546252 | 0.438100 |
| 4 | 0.112847 | 0.117470 | 0.360243 | 0.598008 | 0.210927 | 0.262409 | 0.540579 | 0.397511 | 0.142911 | 0.360057 |
MySQL
写出到mysql里
from sqlalchemy import create_engine import pandas as pd
mysql_engine=create_engine("mysql+pymysql://root:password@localhost/test") df.to_sql(pust_table_name,mysql_engine,if_exists='replace',index = False) # 注意 mysql_engine一定要正确配置
读入刚刚写出的文件
df = pd.read_sql(""" select a,b from pust_table_name; """,mysql_engine) # 再次强调,mysql_engine一定要正确配置,实在有问题可以私信 aiu_cda df
第3节 13 Pandas 表格样式
Pandas 表格样式
Pandas 的样式是一个可视化的方法,像Excel一样对特定数据进行加粗、标红、背景标黄等,为了让数据更加清晰醒目,突出数据的逻辑和特征。
假如我们有这样一个DataFrame,我们需要通过表格样式给它做各种标注:
#读取数据 import pandas as pd import numpy as np df = df = pd.DataFrame( {'A': ['孙云', '郑成', '冯敏', '王忠', '郑花', '孙华', '赵白', '王花', '黄成', '钱明', '孙宇'], 'B': [79, 70, 39, 84, 87, 26, 29, 47, 32, 22, 99], 'C': [28, 77, 84, 26, 29, 47, 32, 22, 99, 76, 44], 'D': [18, 53, 78, 4, 36, 88, 79, 47, 54, 25, 14]}) df

字体颜色
首先来看一个对文字标注颜色的例子:eg.我们想把成绩超过80的分数用红色标注出来
我们需要先定义一个函数,根据条件返回不同的颜色
def color_negative_red(val): color = 'red' if val > 80 else 'black' return 'color: %s' % color
应用这个自定义函数后就可以得到:
df.set_index('A').style.applymap(color_negative_red)

背景高亮
接着 eg. 我们假设有学生没有去考试,想看看哪些学生没有考试,把这部分进行背景高亮显示
数据如下:
df1 = df.copy() df1.iloc[1,1] = np.NaN df1.iloc[2,1] = np.NaN df1

换句话说,就是用背景高亮标记出空值,应用.highlight_null() 即可将空值高亮显示,同时用null_color参数可以指定该高亮的颜色。
#把空值设置高亮 df1.style.highlight_null(null_color = 'blue'#修改颜色 )

极值背景高亮
接着我们想看看 eg. 标记出每个科目的最高分数
换句话说,需要查找DataFrame每一列的最大值,通过 highlight_max() 方法用于将最大值高亮显示,并通过color参数修改高亮颜色
#设置极大值高亮 df.set_index('A').style.highlight_max(color = 'red'#修改颜色 )

通过 highlight_min() 方法可以将最小值高亮显示
df.set_index('A').style.highlight_min(color = 'yellow' #修改颜色 )

同时显示极大值和极小值,并使用指定颜色:通过 highlight_min() 方法和 highlight_max() 方法再指定一下颜色即可
df.set_index('A').style.highlight_min(color = 'green').highlight_max(color = 'red')

横向对比
再来看看横向对比的例子 eg. 需要标记出每个学生的单科最高分数: 通过参数 axis ,横向对比大小,并把最大值进行高亮显示即可
df.set_index('A').style.highlight_max(axis = 1)

同样的,也可以通过参数 subset ,选定一列对最大值进行高亮显示
#指定列进行比较 df.set_index('A').style.highlight_max(subset = ['B'])

背景渐变
eg. 用不同的颜色来标注成绩,背景颜色越深,成绩越高
通过调用 background_gradient() 方法,从而创建一个渐变的背景效果。
df.style.background_gradient()

同样地,针对单个列,指定颜色系列如下:
df.style.background_gradient(subset = ['B'],cmap = 'BuGn')

刚才我们是默认颜色渐变的范围了,接着我们来看如何指定颜色渐变的范围,来展现成绩的高低
通过调用 background_gradient() 方法,用了两个参数 low=0.5 和 high=0 表示渐变的起始值和结束值
#低百分比和高百分比范围,更换颜色时避免使用所有色域 df.style.background_gradient(low = 0.5,high = 0)

接着我们看看如何对特定范围内的值就行标注
eg. 假如需要把60分以上的分数用颜色标注出来
通过参数 vmin 和参数 vmax 设置渐变的最小值和最大值,就可以展现出来。
df.style.background_gradient(vmin = 60,vmax = 100)

eg. 用此次考试成绩表,添加标题
通过.set_caption() 方法为DataFrame 即可设置标题。
#添加标题 df.style.set_caption("三年级二班学生成绩表")

通过以上内容的学习,我们快速学习Pandas样式的基本操作,接下来,再用两个案例详细说明一下
案例一:将科目分数小于60的值,用红色进行高亮显示
#将学生没有及格的科目标记为红色 df.style.applymap(lambda x: 'background-color:red' if x<60 else '', subset = pd.IndexSlice[:,['B','C','D']])

案例二:标记总分低于120分的分数
将每个学生的分数,进行加总和计算平均数,并保留两位小数,把分数低于120的学生,用红色进行标记即可
#通过使用.assign() 来计算学生三门课程的总分和平均值 (df.set_index('A').assign(sum_s = df.set_index('A').sum(axis = 1)) .style.applymap(lambda x: 'background-color:red' if x<120 else '',subset = pd.IndexSlice[:,['sum_s']]) .format({'avg':"{:.2f}"}))

第3节 14 Pandas 可视化
一图胜千言 A picture is worth a thousand words.
常见的可视化图有如下几种:
-
line:折线图
-
pie:饼图
-
bar:柱状图
-
hist:直方图
-
box:箱型图
-
area:面积图
-
scatter:散点图
#用于处理解决中文乱码问题和负号问题。 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] #显示中文问题 plt.rcParams['axes.unicode_minus'] = False #显示负号
line:折线图
折线图一般用于描述数据的趋势:
import pandas as pd import numpy as np import random df = pd.DataFrame({'A': ['a', 'b', 'c', 'd','e', 'f','g','h','i'], 'B': ['L', 'L', 'M', 'L','M', 'M','M','L','L'], 'C': [107, 177, 139, 38, 52, 38,87,38,56], 'D': [22, 59, 38, 59, 59, 82,89,48,88]}).set_index('A') df
|
| B | C | D |
| — | — | — | — |
| A |
|
|
|
| — | — | — | — |
| a | L | 107 | 22 |
| b | L | 177 | 59 |
| c | M | 139 | 38 |
| d | L | 38 | 59 |
| e | M | 52 | 59 |
| f | M | 38 | 82 |
| g | M | 87 | 89 |
| h | L | 38 | 48 |
| i | L | 56 | 88 |
一组数据的折线图如下:
df['C'].plot.line( )
<AxesSubplot:xlabel='A'>

再来看一下两组数据的折线图
df[['C','D']].plot.line()
<AxesSubplot:xlabel='A'>

pie:饼图
饼图一般用于展示数据的占比关系
np.random.seed(123) df1 = pd.Series(3*np.random.rand(4),index = ['a','b','c','d'],name = '占比') df1
a 0.683925
b 0.707985
c 1.646343
d 1.803777
Name: 占比, dtype: float64
看看以上四个数据的占比情况
df1.plot.pie()
<AxesSubplot:ylabel='占比'>

bar:柱状图
柱状图一般用于各种类型数据的对比。
一组数据的柱状图
df['C'].plot.bar()
<AxesSubplot:xlabel='A'>

两组数据的柱状图
df[['C','D']].plot.bar()
<AxesSubplot:xlabel='A'>

横向柱状图
df.plot.barh()
<AxesSubplot:ylabel='A'>

其他几种柱状图
df.assign(a = df.C- 70).plot.bar()
<AxesSubplot:xlabel='A'>

df.plot.bar(stacked = True)
<AxesSubplot:xlabel='A'>

df.plot.barh(stacked = True)
<AxesSubplot:ylabel='A'>

df.head(5).plot.barh(stacked = True,colormap='cool')
<AxesSubplot:ylabel='A'>

hist:直方图
直方图用于展示数据的分布情况
np.random.seed(123) df2 = pd.DataFrame({'a':np.random.randn(1000)+1, 'b':np.random.randn(1000), 'c':np.random.randn(1000)-1}, columns = ['a','b','c']) df2
|
| a | b | c |
| — | — | — | — |
| 0 | -0.085631 | -0.748827 | -2.774224 |
| 1 | 1.997345 | 0.567595 | -2.201377 |
| 2 | 1.282978 | 0.718151 | 0.096257 |
| 3 | -0.506295 | -0.999381 | -0.138963 |
| 4 | 0.421400 | 0.474898 | -2.520367 |
| … | … | … | … |
| 995 | 1.634763 | 0.845701 | -1.075335 |
| 996 | 2.069919 | -1.119923 | -1.946199 |
| 997 | 0.090673 | -0.359297 | 1.040432 |
| 998 | 1.470264 | -1.609695 | 0.015917 |
| 999 | -0.111430 | 0.013570 | -2.633788 |
1000 rows × 3 columns
先来看下一组数据的直方图
df2['a'].plot.hist()
<AxesSubplot:ylabel='Frequency'>

多组数据的直方图
df2.plot.hist()
<AxesSubplot:ylabel='Frequency'>

指定分箱数量的直方图
#堆叠,指定分箱数量 df2.plot.hist(stacked = True,bins = 30)
<AxesSubplot:ylabel='Frequency'>

box:箱型图
箱型图用于展示数据的分布、识别异常值以及比较不同组之间的差异。
一组数据的箱型图
df.boxplot('C')
<AxesSubplot:>

再来看看用两列数据来画两个箱型图
import pandas as pd import numpy as np import random df = pd.DataFrame({'A': ['a', 'b', 'c', 'd','e', 'f','g','h','i'], 'B': ['L', 'L', 'M', 'L','M', 'M','M','L','L'], 'C': [107, 177, 139, 38, 52, 38,87,38,56], 'D': [22, 59, 38, 59, 59, 82,89,48,88]}).set_index('A') df
|
| B | C | D |
| — | — | — | — |
| A |
|
|
|
| — | — | — | — |
| a | L | 107 | 22 |
| b | L | 177 | 59 |
| c | M | 139 | 38 |
| d | L | 38 | 59 |
| e | M | 52 | 59 |
| f | M | 38 | 82 |
| g | M | 87 | 89 |
| h | L | 38 | 48 |
| i | L | 56 | 88 |
df.boxplot(['C','D'])
<AxesSubplot:>

横向箱线图
df.boxplot(['C','D'],vert = False)
<AxesSubplot:>

area:面积图
面积图是一种常见且有效的数据可视化工具,用于展示数据的趋势、比较不同组之间的差异以及理解数据的部分与整体关系。广泛应用于统计学、经济学、市场调研、环境科学等领域,并为数据分析和决策提供了重要的支持。
np.random.seed(123) df4 = pd.DataFrame(np.random.rand(10,4),columns = ['a','b','c','d']) df4
|
| a | b | c | d |
| — | — | — | — | — |
| 0 | 0.283271 | 0.175992 | 0.058558 | 0.667383 |
| 1 | 0.765492 | 0.707079 | 0.894216 | 0.984987 |
| 2 | 0.244719 | 0.447263 | 0.150672 | 0.093241 |
| 3 | 0.814119 | 0.034705 | 0.740344 | 0.944930 |
| 4 | 0.017390 | 0.058722 | 0.015387 | 0.174923 |
| 5 | 0.305805 | 0.053481 | 0.509208 | 0.897541 |
| 6 | 0.530119 | 0.324150 | 0.789586 | 0.569459 |
| 7 | 0.365288 | 0.148475 | 0.503314 | 0.829087 |
| 8 | 0.033251 | 0.045697 | 0.851344 | 0.054292 |
| 9 | 0.470415 | 0.480322 | 0.959995 | 0.960315 |
一组数据的面积图
df4['a'].plot.area()
<AxesSubplot:>

多组数据的面积图
df4[['a','b','c','d']].plot.area()
<AxesSubplot:>

scatter:散点图
散点图用于发现变量之间的关系、探索异常情况、进行聚类分析以及支持预测和模型建立
np.random.seed(123) df = pd.DataFrame(np.random.randn(10,2),columns = ['B','C']).cumsum() df
|
| B | C |
| — | — | — |
| 0 | -1.085631 | 0.997345 |
| 1 | -0.802652 | -0.508949 |
| 2 | -1.381252 | 1.142487 |
| 3 | -3.807932 | 0.713575 |
| 4 | -2.541995 | -0.153166 |
| 5 | -3.220881 | -0.247875 |
| 6 | -1.729492 | -0.886777 |
| 7 | -2.173474 | -1.321128 |
| 8 | 0.032456 | 0.865658 |
| 9 | 1.036510 | 1.251844 |
看一下这两列数据的散点图
df.assign(avg = df.mean(1)).plot.scatter(x='C',y = 'B')
<AxesSubplot:xlabel='C', ylabel='B'>

至此,Python基础部分pandas常用的内容就告一段落了。
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
Python实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
Python书籍和视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
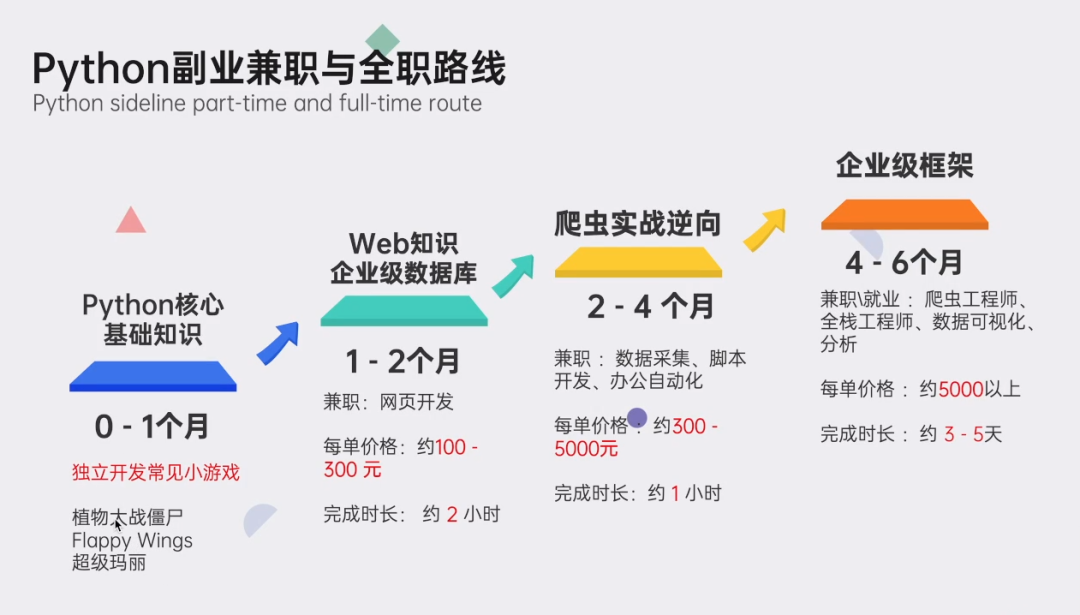
Python副业创收路线
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。
智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范