python基础的查漏补缺(重难点)笔记_"d[\"age\"]=9"-程序员宅基地
辞职在家,根据自己的学习和理解,回顾整理了一些python基础知识,我想对于任何学python编程的人和以后的自己,读来都是大有裨益。希望自己不忘初心,脚踏实地。
python基础
Python中if name == ‘main’:的作用和原理
与Java、C、C++等几种语言不同的是,Python是一种解释型脚本语言,在执行之前不需要将所有代码先编译成中间代码,Python程序运行时是从模块顶行开始,逐行进行翻译执行,所以,最顶层(没有被缩进)的代码都会被执行,所以Python中并不需要一个统一的main()作为程序的入口 则if name = 'main’就是函数入口。
python模块被引入时会自动执行原模块的代码。
作用:防止模块被引入时执行不该执行的代码。
if __name=='main’的文章
动态语言和静态语言的区别
动态语言在运行期进行类型检查,声明变量时可以不指定数据类型
静态语言在编译期进行类型检查,声明变量时需提前指定数据类型
各类型语言的区别
format函数的用法 字符串拼接
可通过列表下标,字典key值,key值,类属性,魔法参数来填充字符串,填充数据不限定为字符串。
format学习笔记
列表生成式
for 语句前面的内容就是传统语句中append函数内的内容
- 生成一个列表,列表元素分别为 [1x1,2x2,3x3……n*n],假设n = 10,且不存在偶数项。
list1 = [i*i for i in range(1,11) if i %2!=0]
原始方法:
list1 =[]
for i in range(1,11):
if i %2 == 0
list1.append(i*i)
列表的删除
#删除某个下标的列表值
del(list[0])
#删除最右侧的值且返回删除的值
a=list.pop()
#删处值为n下标的值并返回删除的值
a=list.pop(n)
字典的增删改查
增
d={
}
d["key"]=180
删
d = {
"name":"zhangsan","age":12}
# 删除指定键值对
del d["age"]
# 删除指定键值对 并把删除的值 赋给变量
age=d.pop("age")
print(age)
# 结果:12
print(d)
# 结果 d ={"name":"zhansan"}
popitem()方法的使用
删除最右边的键值对,并以元组的形式返回该键值对
字典如为空 则报错
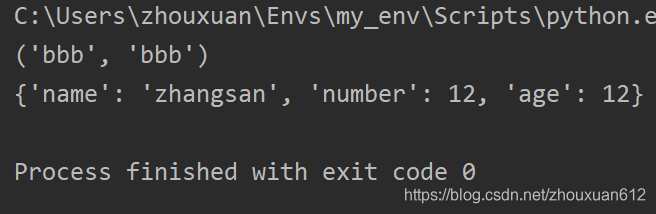
d = {
"name": "zhangsan", "number": 12, "age": 12, "bbb": "bbb"}
c = d.popitem()
print(c)
print(d)
改
因为key为不可改变类型
则 只能修改key对应的value
单一修改
d={
"name":"zhansgan","age":12}
d["name"]="lisi"
print(d)
d={
"name":"lisi","age":12}
批量修改
oldDict.update(newDict)
根据新的字典 批量更新旧字典中的键值对
如果旧字典中没有对应的key,则新增键值对
d={
"name":"zhansgan","age":12}
d.update({
"age":666,"address":"上海"})
print(d)
# {"name":"zhansgan","age":666,"address","上海"}
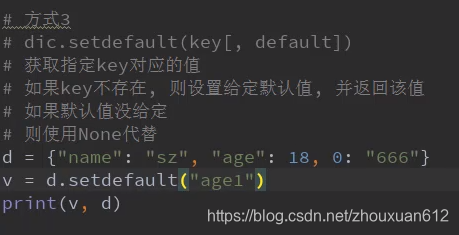
查
d={
"name":"zhansgan","age":12}
print(d["name"]

d={
"name":"zhansgan","age":12}
v= d.get("age")
print(v)
# 结果
12
如果没有对应键值 则原字典增加键值对

查 所有键 值 键值对
d = {
"name": "zhangsan", "number": 12, "age": 12, "bbb": "bbb"}
print(d.keys())
print(type(d.keys()))
print(d.values())
print(d.items())
结果:

python3.6版本
修改字典键值对后 相应的取值发生改变
d = {
"name": "zhangsan", "number": 12, "age": 12, "bbb": "bbb"}
print(d.keys())
print(type(d.keys()))
print(d.values())
print(d.items())
d["name"] = "lisi"
print(d.keys())
print(type(d.keys()))
print(d.values())
print(d.items())
结果:

可以使用list 把键 值 转为列表类型


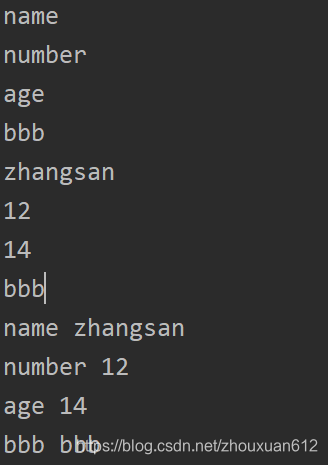
遍历查询
d = {
"name": "zhangsan", "number": 12, "age": 14, "bbb": "bbb"}
for key in d:
print(key)
for value in d.values():
print(value)
for k, v in d.items():
print(k,v)
结果:
判定
判断字典中的key是否存在x
d = {
"name": "zhangsan", "number": 12, "age": 14, "bbb": "bbb"}
print("name" in d)

元组 字符串 列表 都是有序的,因为可以通过索引值获取里面的元素
例如
a = ("zhangsan", 1, 4, 5)
print(a[2])
结果 4
字典,集合是无序的
且集合是不可随机获取的 因为没有键值对 集合不可重复
参数的装包与拆包
:

装包
操作:
def test_put(*args):
print(args)
print(type(args))
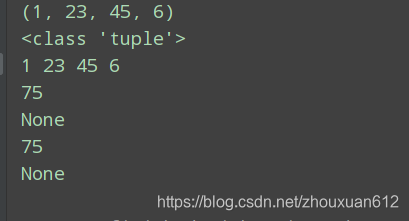
test_put(1,23,45,6)
结果

def sum(a, b, c, d):
print(a + b + c + d)
def test_put(*args):
print(args)
print(type(args))
# 拆包
print(*args)
print(sum(*args))
# 等同于
print(sum(args[0], args[1], args[2], args[3]))
test_put(1, 23, 45, 6)
结果
字典拆包
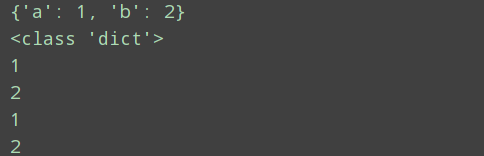
def test(**kwargs):
print(kwargs)
print(type(kwargs))
mysum(**kwargs)
mysum(a=1,b=2)
def mysum(a,b):
print(a)
print(b)
test(a=1,b=2,)
# def sum(a, b, c, d):
# print(a + b + c + d)
#
#
# def test_put(*args):
# print(args)
# print(type(args))
#
# # 拆包
# print(*args)
# print(sum(*args))
# # 等同于
# print(sum(args[0], args[1], args[2], args[3]))
#
#
# test_put(1, 23, 45, 6)
结果:
相当于拆包成a=1,b=2
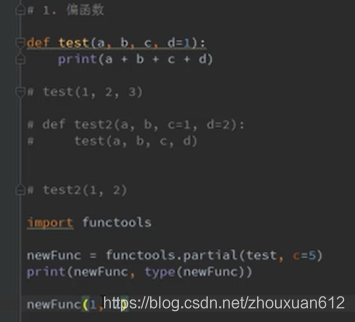
偏函数
概念 了解
自己理解 偏爱某个给定值的参数的函数

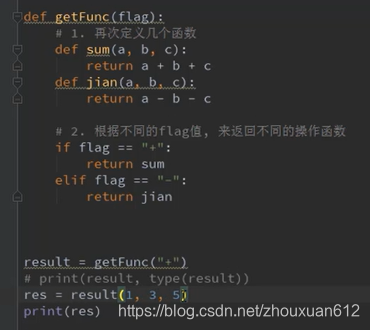
高阶函数
函数中参数是别的函数

函数也可以赋值给一个变量
此时这个变量就拥有的函数的功能

此处sorted就是高阶函数

返回函数
函数内部返回另一个函数

结果:

**
匿名函数
无需定义函数名
返回值是表达式的结果
作用是简单逻辑处理,简洁语法
例子:

函数的闭包

闭包注意事项

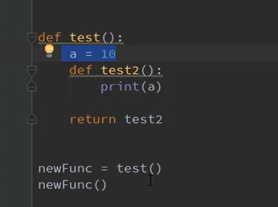
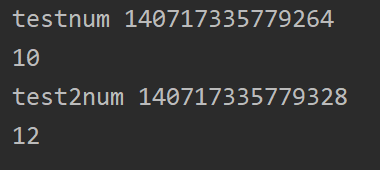
def test():
num = 10
print("testnum", id(num))
def test2():
num = 12
print("test2num", id(num))
print(num)
print(num)
return test2
result = test()
result()
结果:
子函数是定义了一个新变量
如果内部函数想修改外部函数的值 需要加nonlocal声明
装饰器
本质 闭包
给函数增加功能 函数名字 内部代码不能改变
下面两个写法完全相同
本来写法
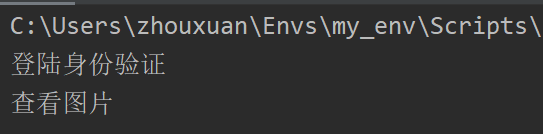
def checklogin(function):
def inner():
print("登陆身份验证")
function()
return inner
def picture():
print("查看图片")
# 在这一步已经执行了
a = checklogin(picture)
a()
注意 装饰器立即执行 语法糖@checklogin既然等于a = checklogin(picture)则也是安装上语法糖 装饰器立即执行
语法糖写法
def checklogin(function):
def inner():
print("登陆身份验证")
function()
return inner
@checklogin
def picture():
print("查看图片")
picture()
结果相同
装饰器的叠加


装饰器装饰带参数的函数
装饰器内部函数形参数量要和要装饰函数一致
不一致可以使用*args **kwargs
def checklogin(function):
def inner(*args, **kwargs):
print("登陆身份验证")
# args的元素自动生成元组,kwargs的自动生成字典格式
print(args, kwargs)
function(*args, **kwargs)
return inner
@checklogin
def dic(num1, num2, num3):
print(num1, num2, num3)
dic(1, 2, num3="zhangsan")

通过不同的参数得到不同的装饰器
装饰器套一个得到装饰器的函数(作用就是给装饰器传参) 再返回装饰器
# 建立一个获取装饰器的函数
# 先得到一个装饰器,在拿装饰器装饰函数
def getzsq(x):
def zsq(function):
def inner(a, b, c):
print(x * 30)
function(a, b, c)
return inner
return zsq
@getzsq("&")
def test(a, b, c):
print(a + b + c)
return a + b + c
test(1, 23, 4)
装饰器装饰带有返回值的函数
保持装饰器内部函数inner格式和要装饰的函数格式一致
def star(function):
def inner(*args):
print("-" * 30)
fun = function(*args)
return fun
return inner
@star
def test(a, b, c):
return a + b + c
res=test(1,2,3)
print(res)

装饰器的执行顺序
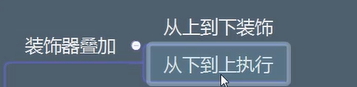
装饰器 从上到下装饰意思是装饰器的功能实现是从上到下按顺序的,每个装饰器声明的下方的部分都可看做是装饰的一个函数。
def hengxian(function):
def inner():
print('*' * 30)
function()
return inner
def star(function):
def inner():
print("-" * 30)
function()
return inner
@hengxian
@star
def test():
print("装饰器的使用")
test()
迭代器
任何实现了__iter__()和__next()__方法的都是迭代器,其中__iter()__实用来返回迭代器本身;__next()__是用来返回迭代对象中的下一个值 迭代器是访问集合元素的一种方式。
迭代器是一个可以记住遍历的位置的对象。
注意事项如下:
1.迭代器有具体的迭代器类型,可用type查看,一般有list_iterator,set_iterator等类型
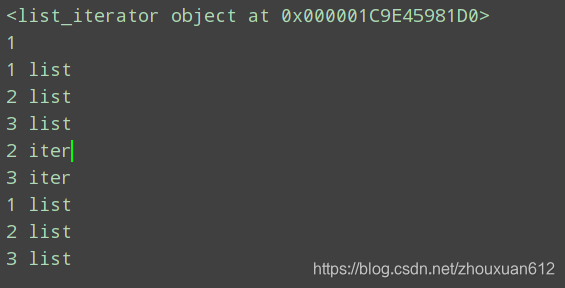
2.迭代器是有状态的,可以被next()调用,并且不断返回迭代对象的下一个值,如果到了迭代器的最后一个元素,继续调用next(),则会抛出stopIteration异常
list = [1, 2, 3,]
it = iter(list) # 创建迭代器对象
print(it)
print(next(it)) # 输出迭代器的下一个元素
for i in list:
print(i, "list")
for i in it:
print(i, "iter")
for i in list:
print(i, 'list')
for i in it:
print(i, "iter")
结果:
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
list = [1, 2, 3, 4, 5, 6, 7]
it = iter(list) # 创建迭代器对象
print(it)
print(next(it)) # 输出迭代器的下一个元素
string = "agsdkjdhakj"
ite = iter(string)
print(next(ite))
生成器
生成器 是特殊的迭代器,不需要手动的编写__iter()__和__next()__方法,因为yeild关键字已经实现了这两种方法。一般用于大数据,大文件逐个生成的时候,可以大大减少内存的开销。
迭代器特性:
1惰性计算数据(操作一个,就处理这一个数据,剩下的先不管) 节省内存
2能够记录状态,并通过next()函数,访问下一个状态
3具备可迭代性
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
调用一个生成器函数,返回的是一个迭代器对象。
生成器的创建方式
1生成器表达式 列表推导式[ ]变为()
a = [i for i in range(1, 10)]
print(type(a))
a = (i for i in range(1, 10))
print(type(a))
2生成器函数
函数中包含yield语句
函数的执行结果就是生成器
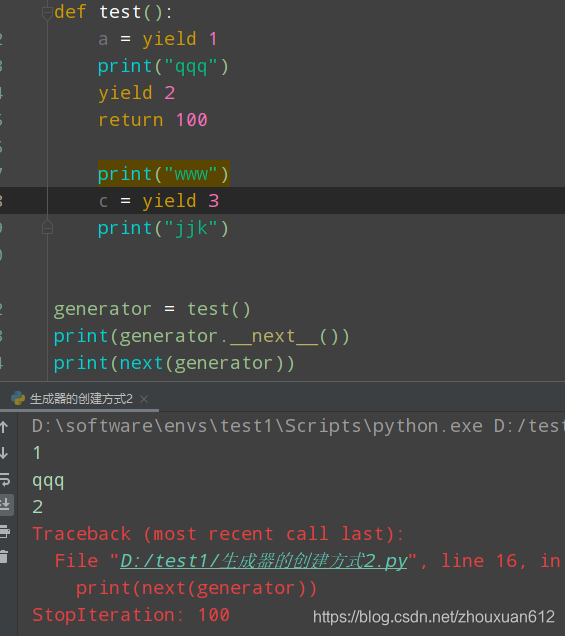
def test():
print("begin")
yield 1
print("first")
yield 2
print("second")
yield 3
print("third")
generator = test()
print(next(generator))
print(generator.__next__())


def test():
for i in range(1,10):
yield i
generator = test()
print(next(generator))
print(generator.__next__())

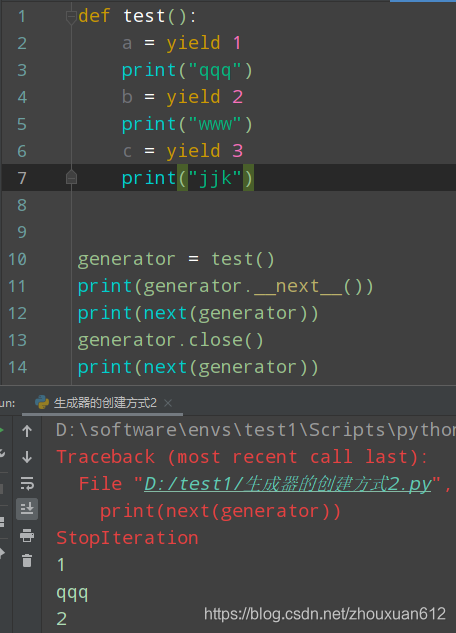
send方法的使用

def test():
a = yield 1
print(a)
b = yield 2
print(b)
generator = test()
print(generator.send(None))
print(generator.send("老八"))
关闭生成器
close方法直接执行到生成器最后一个yield值,然后再执行next方法就会抛出StopIter异常

如果生成器函数 执行过程中碰到return 语句 立马终止 并打印return的值
迭代器 生成器 可迭代对象的区别
迭代器与可迭代对象:
迭代器都是一个可迭代对象,且所有的Iterable(迭代对象)都可以通过内置函数iter()转变为Iterator(迭代器)
生成器与迭代器:
联系:所有的生成器都是迭代器,有yield的是生成器,因为yield可以是生成器表达式也可以是生成器函数
区别:迭代器用于从集合中取出元素
生成器用于凭空生成元素
Python可迭代对象,迭代器,生成器的区别
面向对象部分知识
函数与方法的区别
本质上, 函数和方法的区别是: 函数是属于 FunctionObject, 而 方法是属 PyMethodObject
即 类外的是函数,在类内与类绑定的是方法。
对象属性的添加
class Table:
pass
table = Table()
tablexxx = Table()
table.length = 1
tablexxx.height = 2
print(table.length)
print(tablexxx.height)
结果 1,2
每个对象添加的属性只属于此对象
类属性的添加
方式1 类名.类属性=xxx
class Table:
pass
Table.length = 111
print(Table.length)
table = Table
print(table.length)

方式二
类中直接定义 属性值
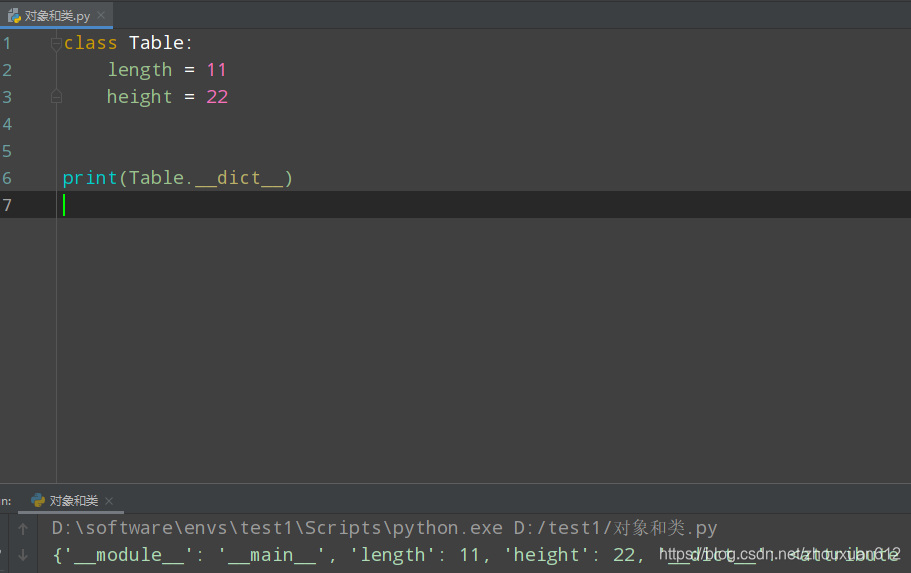
python对象的属性查找机制

可变类型与不可变类型
以前不清楚 记住可变是字典 列表 剩下的都不可变
不可变对象如果改变,则开辟新内存空间存储,即变量指向新地址,新对象
可变对象与不可变对象笔记
类属性删除
类名.类属性.del语句
属性的内存存储

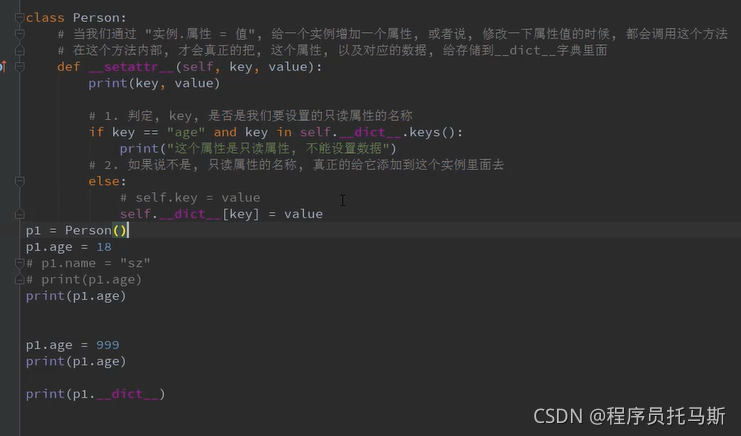
类限制对象属性的添加
slots限制赋值列表里面的属性才能添加
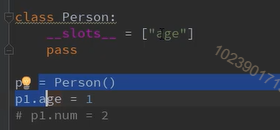
方法的划分

各种方法的区分
类方法:类对象和类的实例都能调用 (类实例调用的时候,传的参数是类实例的类)
实例方法:只能类的实例对象 才能调用(实例方法参数名称,可以不是self,自动接收实例对象)
静态方法:不接受调用的对象参数,实例对象和类对象都能调用
class Table:
length = 11
height = 22
@staticmethod
def static():
print("1123")
def slifangfa(self):
print("实例方法", self)
@classmethod
def leifangfa(cls):
print("类方法", cls)
table = Table()
table.static()
Table.static()
table.leifangfa()
Table.leifangfa()
table.slifangfa()
# Table.slifangfa()

方法的存储位置
这三种方法都存储在类对象当中
class Table
@staticmethod
def static():
print("1123")
def slifangfa(self):
print("实例方法", self)
@classmethod
def leifangfa(cls):
print("类方法", cls)
table = Table()
print(table.__dict__)
print(Table.__dict__)

不同类型的方法访问不同的属性
类方法只能访问类属性
实例方法都可以访问
静态方法可以引入类对象访问类属性,但因拿不到实例 无法访问实例属性
class Table:
length = 11
@staticmethod
def static():
print(Table.length)
def slifangfa(self):
print("实例方法", self)
@classmethod
def leifangfa(cls):
print("类方法", cls)
print(Table.static())
元类
概念:创建类对象的类
无论是自己定义的还是系统创建的类(类对象),都是由元类创建的。
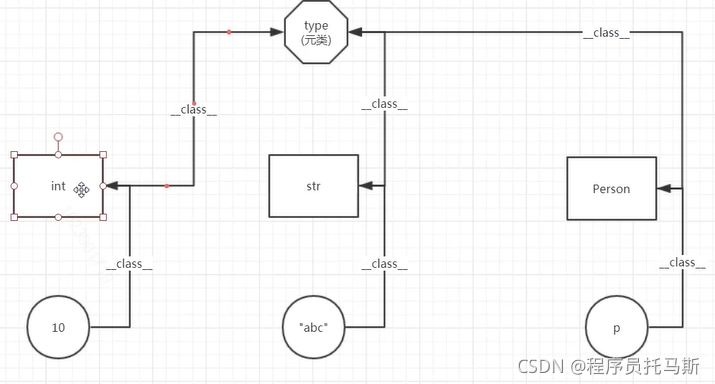
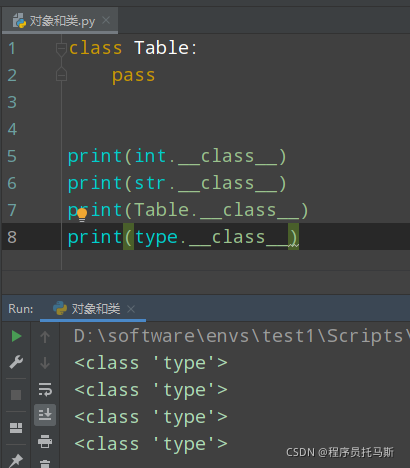
类的创建方式
1 普通创建 class 类名:
2手动创建:type(类名,(父类名),类属性)
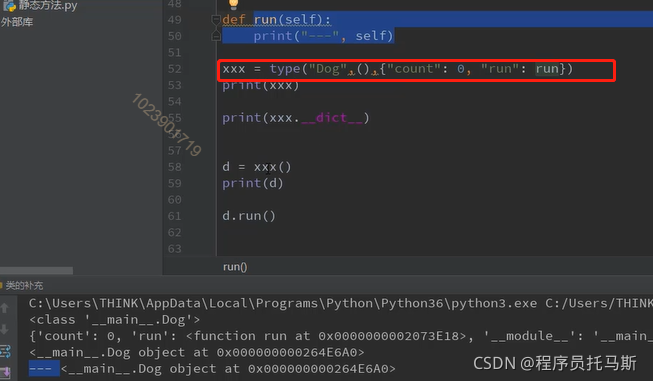
类的创建流程
__meta__class 元类属性

类的描述
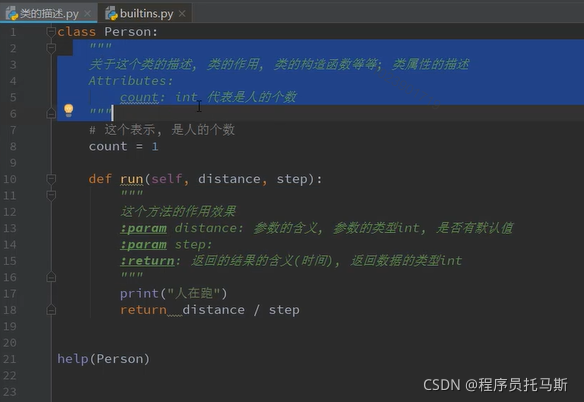

注释文档的生成
先进入项目文件地址:输入命令 生成文档访问ip
注意模块文件名不能为中文

类的私有化属性
python没有真正的私有化支持
(伪私有是指可以通过其他手段来访问,真私有是怎样也访问不了私有属性)

受保护属性 protect _
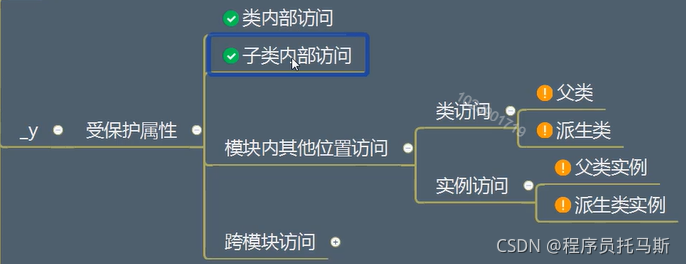
跨模块访问受保护属性
import 模块名
可以访问
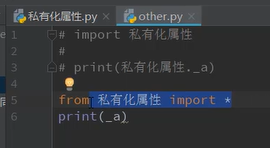
from 模块名 import *
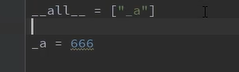
不能访问 除非在原模块中加入
私有属性 private __
私有属性只能在定义私有属性的类内部访问
无论是类,子类,类对象 ,子类对象,都不能访问。
如果是私有变量 跨模块访问和保护变量相同
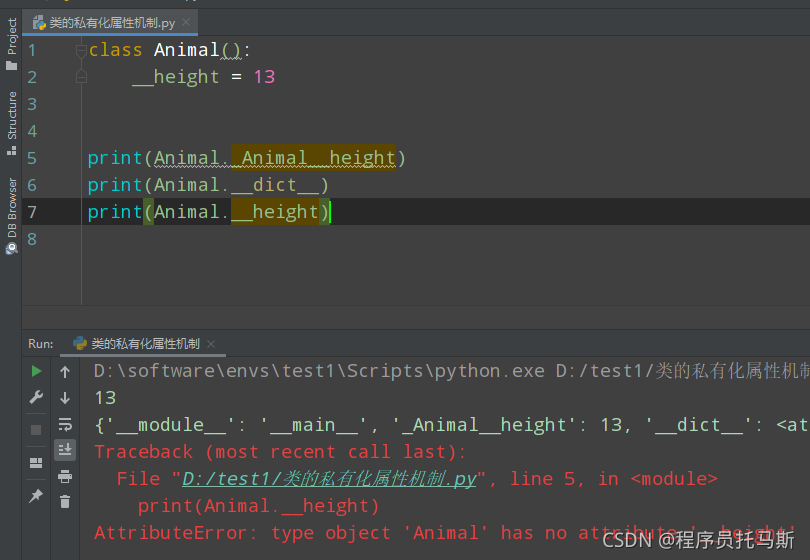
私有属性的机制

私有属性的修改和查询
类内定义方法,来修改私有属性
__init__方法,用来初始化对象
如果定义的属性名和内置的属性冲突 可定义为__xx__格式
只读属性的设置以及property的使用
property的作用:方法属性化
简单地说就是一个类里面的方法一旦被@property装饰,就可以像调用属性一样地去调用这个方法**,它能够简化调用者获取数据的流程**,而且不用担心将属性暴露出来,有人对其进行赋值操作(避免使用者的不合理操作)。
需要注意的两点是:
调用被装饰方法的时候是不用加括号的
方法定义的时候有且只能有self一个参数
class Animal:
def __init__(self):
self.__age = 12
# 可以使用调用属性的方式 来调用方法
@property
def age(self):
return self.__age
animal = Animal()
print(animal.age)

方法2
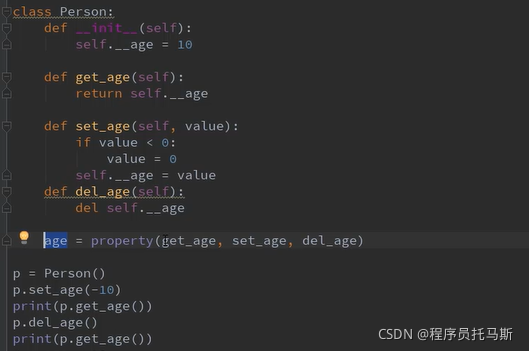
私有属性的 改查删 (property)
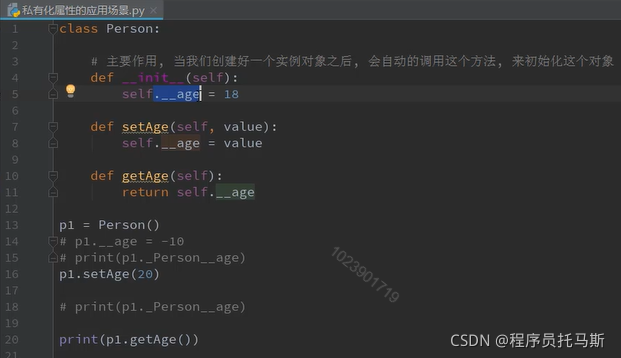
class Person():
def __init__(self):
self.__age = 100
@property
def age(self):
return self.__age
@age.setter
def age(self, value):
self.__age = value
@age.deleter
def age(self):
del self.__age
p = Person()
print(p.age)
p.age =11
print(p.age)
del p.age
print(p.age)
经典类与新式类
property在新式类中的使用方式
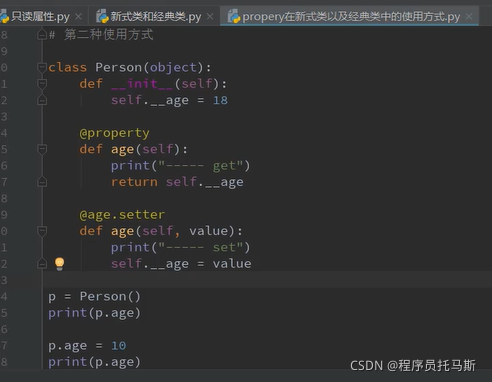
在经典类中只能读取,不能设置值或者删除修改值
私有方法
和私有属性定义方式相同 只能在类的内部调用。
_类名__方法名
内置特殊方法
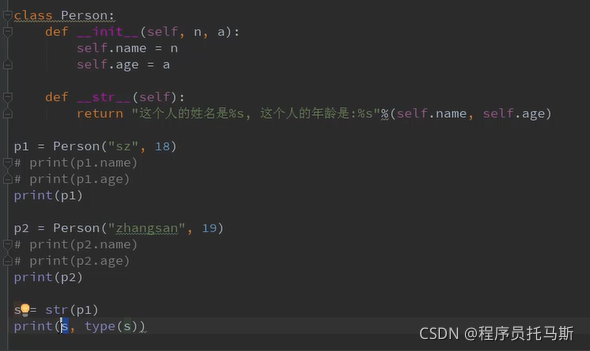
__str__方法是打印对象时输出方法内部定义的字符串
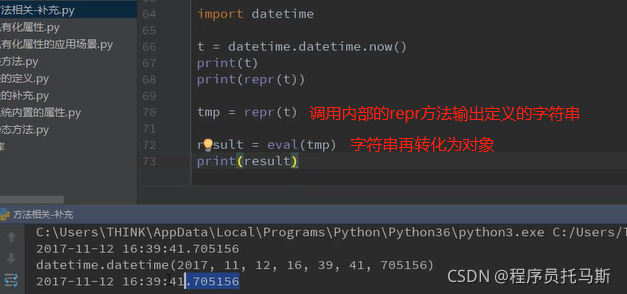
__repr__方法直接输出对象定义的字符串
**eval**再转换成为对象
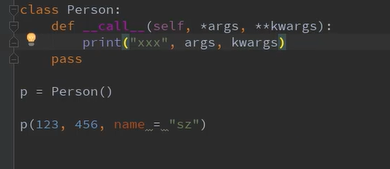
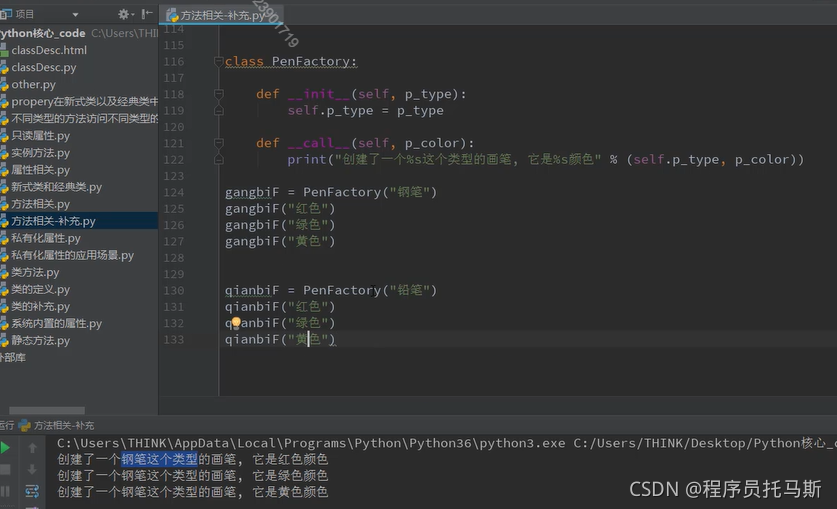
__call__方法
使得实例对象具备当做函数能来调用的能力
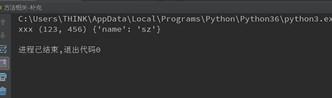
call方法的应用场景之一
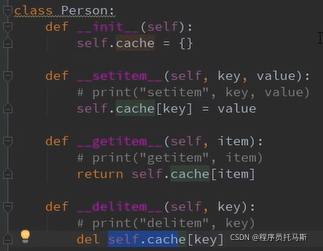
索引操作 内置方法

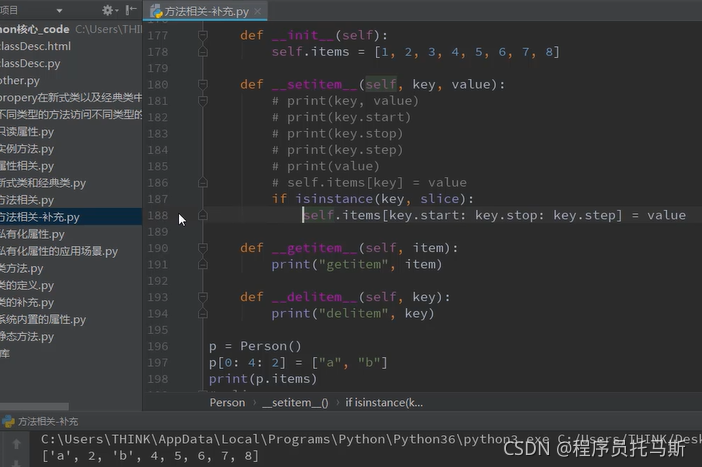
切片操作
比较大小
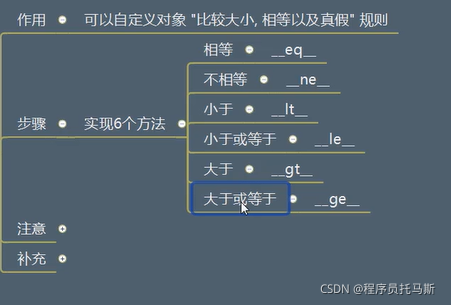
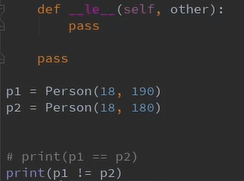
装饰器 自动补齐剩下的比较方法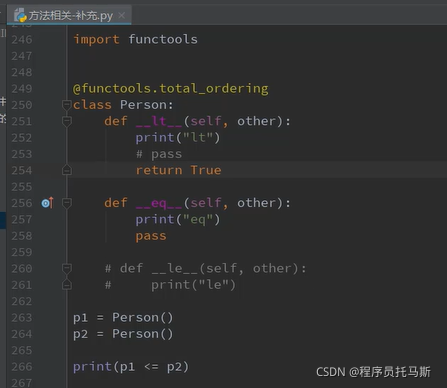
比较操作 上下文布尔值
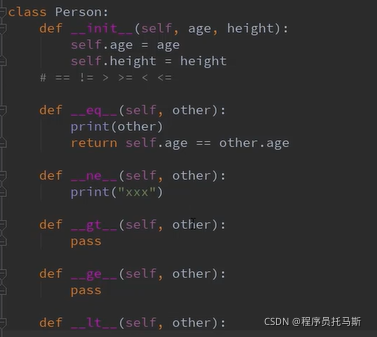
class Person():
def __init__(self, age):
self.age = age
def __bool__(self, ):
return self.age > 20
p = Person(181)
if p:
print("xxx")
遍历操作

现在不是迭代器
需要使用iter把实例对象变为迭代器
class Person:
def __init__(self):
self.result = 1
def __getitem__(self, item):
self.result += 1
if self.result >= 6:
raise StopIteration("停止遍历")
return self.result
p = Person()
p = iter(p)
print(next(p))
print(next(p))
print(next(p))
遍历方式二
iter函数把实例对象变为迭代器,再调用next方法
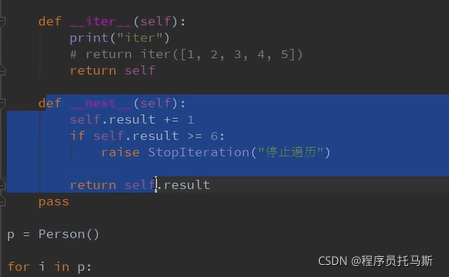
迭代器能通过next函数进行访问 但是能通过next函数访问的不一定是迭代器
因为迭代器要同时实现iter和next方法
迭代器是可迭代对象 可迭代对象不一定是迭代器
因为可迭代对象只需实现iter方法
描述器
概念和作用:描述器是一个对象,可以描述一个属性的操作;其作用是对属性的操作做验证和过滤,如对一个人的年龄赋值时,不能赋值为负数,这是需要验证和过滤,但由于属性数量多,不能在赋值前进行验证,所以用到描述器,每次验证时就会进入描述器中进行相关操作
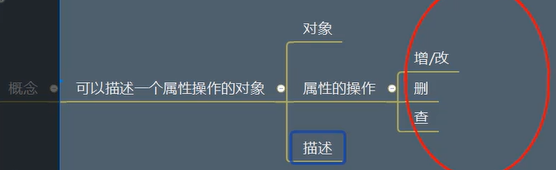
描述器的定义方式一:使用property将操作方法与属性进行关联,即可在操作属性时自动进行相关方法执行
描述器 定义方式2
描述器的定义方式二:对方式一进行优化,即多个属性时,由于操作内容不同,在主类中代码会过于繁琐,为简化代码,将属性的操作方法封装到类中,在主类中对方法类的实例对象进行操作即可。
# 方法类
class Age():
def __get__(self, instance, owner):
print("get")
# return 10
return instance.v
def __set__(self, instance, value):
print(self, instance, value)
instance.v = value
def __delete__(self, instance):
del instance.v
print("delete")
# 主类
class Person():
age = Age()
def __init__(self):
self.age = 10
p = Person()
print(p.age)
# p.age = 11
# print(p.age
先执行set方法 再执行get方法。

注意1:调用描述器时只能类的实例来调用,直接通过类无法调用set 和delete 方法。
注意2:无论是宿主类还是描述器对应的类全部为新式类才行
因为调用新式类的getattribute方法)。
描述器和实例属性重名时 操作优先级
资料描述器>实例属性>非资料描述器
资料描述器:定义了get与set方法的描述器
非资料描述器:只定义了get方法
描述器的数据存储问题
数据还是存到非描述器类中,因为非描述器类实例化一个实例后,实例属性不互通 改变。即不同实例的同名属性存在不同的实例的内存地址。
class Age():
def __get__(self, instance, owner):
print("get")
# return 10
return instance.v
def __set__(self, instance, value):
print(self, instance, value)
instance.v = value
def __delete__(self, instance):
del instance.v
print("delete")
class Person():
age = Age()
def __init__(self):
self.age = 10
p = Person()
print(p.age)
p.age =11
print(p.age)
del p.age
print(p.age)
@property使方法属性化,描述器是让属性拥有get,set等方法的功能,他俩达到的目的是一样的。
类 - 装饰器
第一种方法 装饰函数 用init
# 函数方式
# def check(func):
# def inner():
# print("登录验证")
# func()
#
# return inner
# 类 装饰器
class check():
# 存储传来被装饰的函数
def __init__(self, func):
self.f = func
# 使实例对象能当做方法调用
def __call__(self, *args, **kwargs):
print("登录验证")
self.f()
@check
def write_article():
print("出版书籍")
# 等同于write_article = check(write_article)
# write_article = check(write_article)
write_article()
**第二种方法 **
# 类 装饰器
class check():
# 存储传来被装饰的函数
def __new__(cls, func):
cls.f = func
return cls.__call__(cls)
# 使实例对象能当做方法调用
def __call__(self, *args, **kwargs):
print("登录验证")
return self.f()
def write_article():
print("出版书籍")
# 直接执行
check(write_article)
实例对象生命周期涉及的三个类的方法
new init方法
创建类时先执行type的__init__方法,
当一个类实例化时(创建一个对象)执行type的__call__方法,__call__方法的返回值就是实例化的对象
__call__内部调用
-类.__new__方法,创建一个对象
-类.__init__方法,初始化对象
实例化对象是谁取决于__new__方法,__new__返回什么就是什么
new() 方法的特性:
new() 方法是在类准备将自身实例化时调用。
new() 方法始终都是类的静态方法,即使没有被加上静态方法装饰器
new方法必须要有返回值
init方法不需要返回值
class check(object):
# new 方法 新建实例对象
# def __new__(cls, *args, **kwargs):
# print("1111")
# init方法 对象初始化
def __init__(self):
print("222")
self.name = "zhangsan"
# del 方法 程序结束后自动调用 删除对象 释放对象占用的内存
def __del__(self):
print("删除")
c = check()
print(c)
此方法可反复琢磨(类属性的使用和%d)
class check(object):
count = 0
# init方法 对象初始化
def __init__(self, value):
self.v = value
check.count += 1
self.name = "zhangsan"
# del 方法 程序结束后自动调用 删除对象 释放对象占用的内存
def __del__(self):
self.__class__.count -= 1
@staticmethod
def log():
print("实例个数为%d个" % check.count)
check.log()
c = check("c")
c1 = check("c1")
check.log()
面向对象实战
# def decorate(func):
# def inner(self,value):
# func(self,value)
# print(self.v)
# # return inner
class Computer():
def __init__(self, value):
self.__v = value
# 输出值
def __create_laba(operation):
def __laba(func, ):
def inner(self, value):
print(str(self.__v) + operation + str(value))
return func(self, value)
return inner
return __laba
# 验证功能
def __decorate(func, ):
def inner(self, value):
if not isinstance(value, int):
raise TypeError("输入数据的类型有问题,应该输整型数据")
return func(self, value)
return inner
# 装饰器执行顺序,先验证,再加减乘除
@__decorate
@__create_laba("+")
def add(self, value):
self.__v += value
# 返回对象本身 为了连续调用加减乘除的方法
return self
@__decorate
@__create_laba("-")
def low(self, value):
self.__v -= value
return self
@__decorate
@__create_laba("*")
def multi(self, value):
self.__v *= value
return self
# 数值清零
def clear(self):
self.__v = 0
return self
@property
def result(self):
return self.__v
c = Computer(2)
c.add(5).low(4).multi(10).clear().add(1)
print(c.result)
python的内存管理机制
内存管理机制=引用计数器机制+垃圾回收机制
对象的存储
整型 浮点型等都是对象
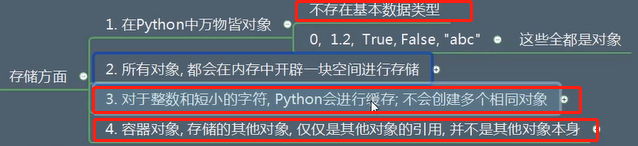
引用计数器

计数器加1减1场景
加1:
对象被创建 p1 = Person()
对象被引用 p2=p1
对象作为参数传到函数
对象作为元素 存储到容器中
减一:
对象的别名被显示销毁 del p1
对象的别名指向别的对象 p1 =3
对象所在的容器被销毁
对象离开所在的作用域 例如 一个函数执行完毕
循环引用问题
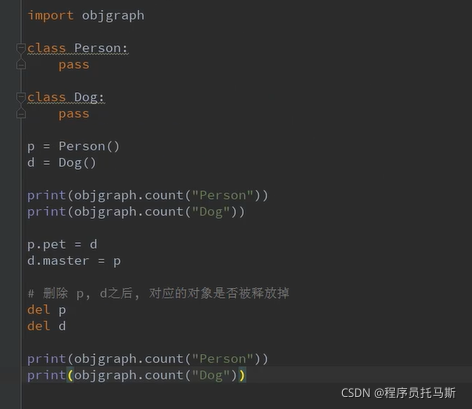
结果:

对象循环引用了就不会被回收
垃圾回收机制
新增的对象个数-消亡的对象个数达到某个阈值时,才会自动触发垃圾检测
了解:

如何加快查找循环引用的性能
分代回收:
对象查找一定次数后,则升代
代越高 垃圾回收的频率越低
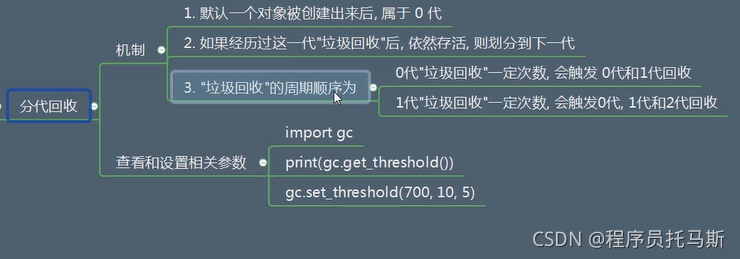
import gc
print(gc.get_threshold())
import gc
import objgraph
# 关闭垃圾回收机制
gc.disable()
class Dog:
def __del__(self):
print("dog被删除")
class Person:
def __del__(self):
print("person被删除")
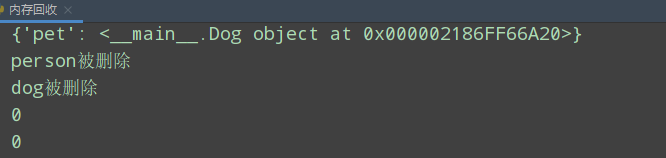
p = Person()
d = Dog()
# 实例对象之间相互引用 造成循环引用
# 实例对象的 pet属性 指向d的地址 pet没有新开辟空间 仍存在p对象之中
p.pet = d
d.master = p
print(p.__dict__)
# 删除可到达引用 p.pet在删除了p后无法引用 成为不可到达引用
del p
del d
# 通过引用计数无法回收的对象 借助垃圾回收机制进行回收
gc.collect()
print(objgraph.count("Person"))
print(objgraph.count("Dog"))
面向对象三大特性
封装
概念:

好处:

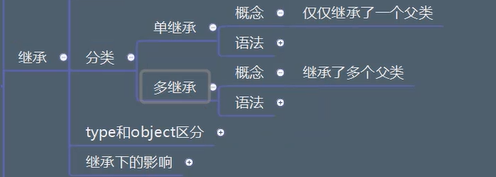
继承
概念:
子类可以使用父类的资源。
type是元类 是实例化类对象的类 也是继承了object类的类


子类修改父类同名属性,实际上是自己新增一个属性,不会修父类的属性值。
class Animal():
a = 0
class Dog(Animal):
pass
print(Dog.a)
Dog.a = 10
print(Dog.a)
print(Animal.a)

继承的顺序
python版本3.0 都成为了新式类后 都采用c3算法
单继承或无重叠的多继承遵循深度优先原则
有重叠的多继承遵循从下到上原则

资源的覆盖

简单来说就是使用优先继承的资源
self的变化
class A():
a = 0
def test(self):
print(self)
@classmethod
def test2(cls):
print(cls)
class B(A):
pass
b = B()
print(B.test2())
print(b.test())
谁调用方法 self对象和类就是谁

继承 资源的累加 注意事项-实例属性
方法1 子类Init方法中父类调用init方法 了解
class A():
def __init__(self):
self.a = 1
class B(A):
def __init__(self):
A.__init__(self)
self.b = 2
b = B()
print(b.__dict__)
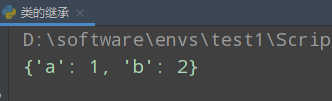
会产生父类方法重复调用的问题(经典类只能这样调用)

方法2 super (只在新式类中有效)
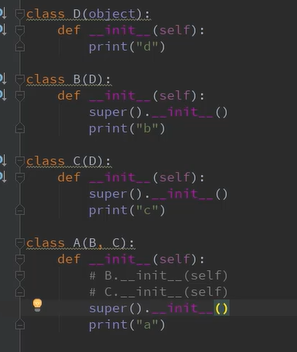
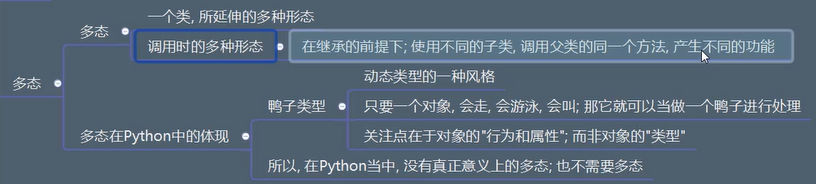
多态
静态语言与动态语言
静态类型语言编译时会进行类型匹配检查,所以不能给变量赋予不同类型的值。为了解决这一问题,静态类型的面向对象语言通常通过向上转型的技术来取得多态的效果。
动态类型语言的变量类型在运行期是可变的,这意味着对象的多态性是与生俱来的。一个对象能否执行某个操作,只取决于有没有对应的方法,而不取决于它是否是某种类型的对象
class Animal():
def jiao(self):
print("jiao")
class Dog(Animal):
def jiao(self):
print("wangwang")
class Cat(Animal):
def jiao(self):
print("miaomiao")
def test(self):
self.jiao()
d = Dog()
c = Cat()
test(d)
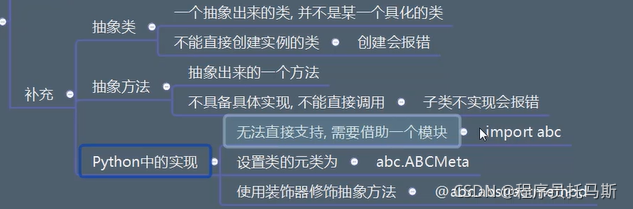
补充
抽象类 只能被继承 不能被实例化
从设计角度去看,如果类是从现实对象抽象而来的,那么抽象类就是基于类抽象而来的。
从实现角度来看,抽象类与普通类的不同之处在于:抽象类中只能有抽象方法(没有实现功能),该类不能被实例化,只能被继承,且子类必须实现抽象方法。
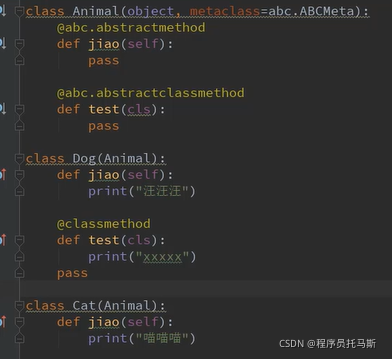
面向对象实战
class Animal():
def __init__(self, name, age):
self.name = name
self.age = age
def eat(self):
print("{}在吃饭".format(self))
def jiao(self):
print("%s在睡觉" % self)
def play(self):
print("%s在玩" % self)
class People(Animal):
def __init__(self, name, pets, age=11):
super(People, self).__init__(name, age)
self.pets = pets
def pet(self):
for pet in self.pets:
pet.eat()
pet.jiao()
def pet_work(self):
for pet in self.pets:
# if pet.__class__ == Dog:
# pet.defend()
# # 判定对象的类
# elif isinstance(pet, Cat):
# pet.bet()
# 避免此后新增多个宠物 则各个宠物工作的方法统一改为work
pet.work()
def __str__(self):
return "名字是{}.年龄{}岁的人".format(self.name, self.age)
class Cat(Animal):
def __str__(self):
return "名字是{}.年龄{}岁的小猫".format(self.name, self.age)
def work(self):
print("{}在捉老鼠".format(self))
class Dog(Animal):
def __str__(self):
return "名字是{}.年龄{}岁的小狗".format(self.name, self.age)
def work(self):
print("%s在看门" % self)
d = Dog("葛光耀", 13)
c = Cat("张三", 13)
pets = [d, c]
p = People("周旋", pets, age=23)
print(p.__dict__)
p.pet()
p.pet_work()
p.eat()
类的设计原则
S 单一职责原则
自己理解:
类该干什么就写什么内容 如果有对结果数据的处理 写到别的类中
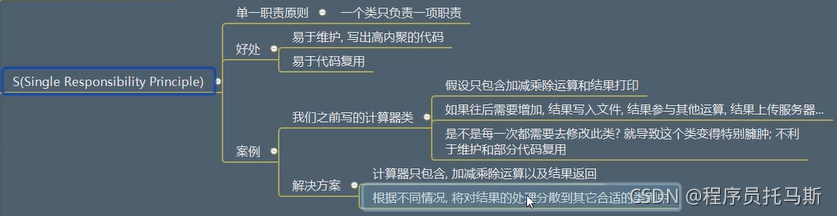
O 开放封闭原则
只扩展 不修改
统一不同的特殊的子类方法名

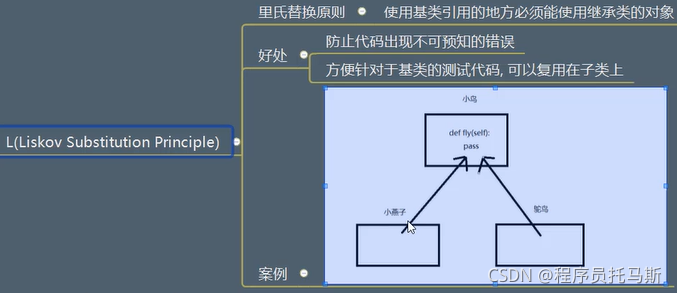
L 里氏替换原则
父类的方法属性 子类全部得有
I 接口(方法)分离

不同子类如果继承的类中个别方法须不同,可增加父类,不同子类继承不同父类。
D 依赖倒置

错误和异常处理
异常概念
异常 逻辑和代码都正常出现的未知错误 可以通过其他代码处理修复

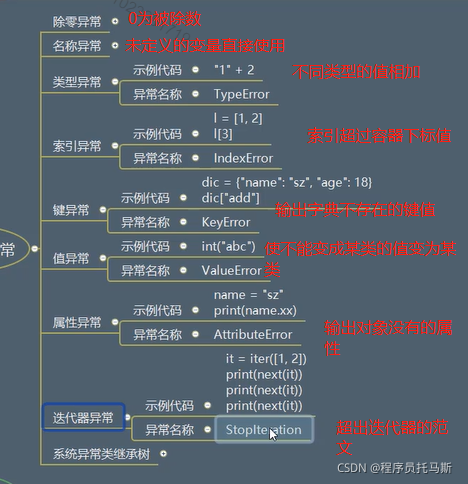
常见异常
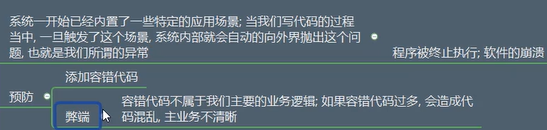
如何解决异常
预防
解决 捕获处理异常
如果捕捉的不是定义的异常类型,则会报错。
方案1 try语句

未知异常类型可以直接使用Exception
try:
print(name)
# 可以把异常报错接收后 处理
except ZeroDivisionError as ze:
print("除零异常", ze)
except Exception as ex:
print("未知异常", ex)
else:
print("没有异常")
finally:
print("加油加油你最棒")
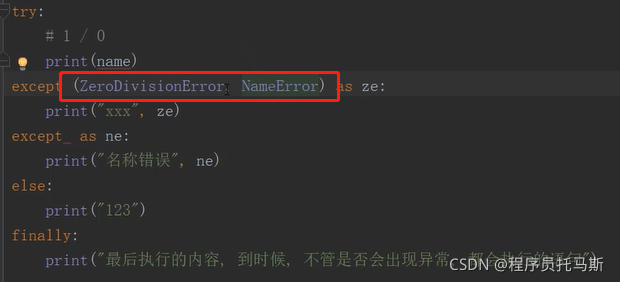
异常合并
把要合并的异常包装成元组。
上下文管理器
上下文管理器(Context Manager):**支持上下文管理协议的对象,这种对象实现了_enter_() 和 exit() 方法。**上下文管理器定义执行 with 语句时要建立的运行时上下文,负责执行 with 语句块上下文中的进入与退出操作。通常使用 with 语句调用上下文管理器,也可以通过直接调用其方法来使用。enter() 方法在语句体执行之前进入运行时上下文,exit() 在语句体执行完后从运行时上下文退出。with 语句支持运行时上下文这一概念。
即使报异常 也会关闭文件

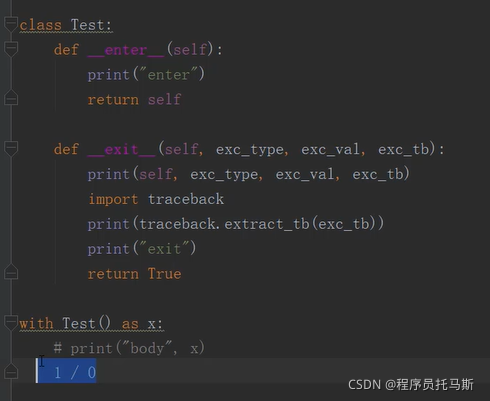
自定义上下文管理器以及with语句的使用
上下文表达式(Context Expression):with 语句中跟在关键字 with 之后的表达式,该表达式要返回一个上下文管理器对象。
语句体(with-body):with 语句包裹起来的代码块,在执行语句体之前会调用上下文管理器的 enter() 方法,执行完语句体之后会执行_exit_() 方法。
exit方法 异常处理
as 后为enter方法的返回值
contextlib模块的使用
可以使生成器变为上下文管理器
把业务逻辑和异常处理代码解耦 增强代码复用性
import contextlib
# 把manager变为上下文管理器
@contextlib.contextmanager
def manager():
try:
yield
except ZeroDivisionError as ze:
print("error",ze)
with manager():
1 / 0
此处 manger函数变为上下文管理器,try后 yield语句前执行manager里面的内容,yield后语句抛出错误
contextlib.closing的用法
把带有close方法的类变为上下文管理器,并默认实现了enter和exit方法,enter方法中返回类实例对象。

import contextlib
class Test():
def t(self):
print("ttt")
def close(self):
print("关闭")
with contextlib.closing(Test()) as obj:
obj.t()
with语句在线程锁的使用 线程锁自己定义了enter和exit方法
with语句实现线程锁
手动抛出异常
抛出自己定义的异常类的异常

分情况 如果异常比较重要则抛出警示 反之容错处理


# 自定义异常类
class LessError(Exception):
def __init__(self, num):
self.message = "输入的值<0或者>140"
self.num = num
def __str__(self):
return self.message + " " + "错误码为" + str(self.num)
def set_age(num):
if num < 0 or num > 140:
raise LessError(404)
# print(111)
else:
print("小王的年龄设置为%s" % num)
try:
set_age(-1)
except LessError as e:
print(e)
线程、进程、协程总结
线程
线程是进程中执行代码的一个分支,每个线程要想工作需要cpu进行调度,也就是说线程说cpu调度的基本单位,每个进程至少都有一个线程,而这个线程就是我们常说的主线程。
线程的注意点
1线程之间执行是无序的
2主线程会等待所有的子线程结束再结束 如想设置为主线程结束后,子线程便结束,则可设置守护主进程(child_thread.setDaemon(True))
3线程之间共享全局变量
4但线程共享全局变量会出现错误问题
线程的GIL锁
GIL是一个互斥锁(mutex)。它阻止了 多个线程同时执行Python字节码,毫无疑问,这降低了执行效率。理解GIL的必要性,需要了解CPython对于线程安全的内存管理机制
首先,我们来看看单核CPU下,多线程任务是如何调度的。
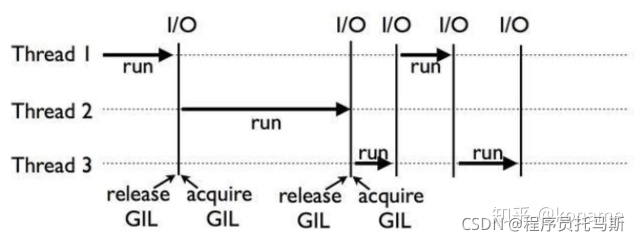
由图可知,由于GIL的机制,单核CPU在同一时刻只有一个线程在运行。当线程遇到IO操作或Timer Tick到期,释放GIL锁。其他的两个线程去竞争这把锁,得到锁之后,才开始运行。
线程释放GIL锁有两种情况,一是遇到IO操作,二是Time Tick到期。IO操作很好理解,比如发出一个http请求,等待响应。那么Time Tick到期是什么呢?Time Tick规定了线程的最长执行时间,超过时间后自动释放GIL锁。
虽然都是释放GIL锁,但这两种情况是不一样的。比如,Thread1遇到IO操作释放GIL,由Thread2和Thread3来竞争这个GIL锁,Thread1不再参与这次竞争。如果是Thread1因为Time Tick到期释放GIL,那么三个线程可以同时竞争这把GIL锁,可能出现Thread1在竞争中胜出,再次执行的情况。单核CPU下,这种情况不算特别糟糕。因为只有1个CPU,所以CPU的利用率是很高的。
在多核CPU下,由于GIL锁的全局特性,无法发挥多核的特性,GIL锁会使得多线程任务的效率大大降低。
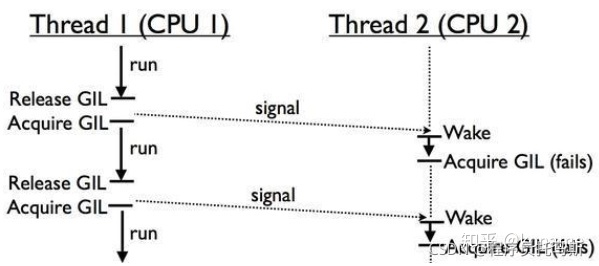
Thread1在CPU1上运行,Thread2在CPU2上运行。GIL是全局的,CPU2上的Thread2需要等待CPU1上的Thread1让出GIL锁,才有可能执行。如果在多次竞争中,Thread1都胜出,Thread2没有得到GIL锁,意味着CPU2一直是闲置的,无法发挥多核的优势。
为了避免同一线程霸占CPU,在python3.x中,线程会自动的调整自己的优先级,使得多线程任务执行效率更高。
既然GIL降低了多核的效率,那保留它的目的是什么呢? 这就和线程执行的安全有关。
准确的说,GIL的线程安全是粗粒度的。也就是说,GIL保证了一定程度的但非100%安全。比如下面这个例子:
begin_time = time.time()
def add():
global n
for i in range(1000000):
n = n + 1
def sub():
global n
for i in range(1000000):
n = n - 1
n = 0
a = threading.Thread(target=add, )
b = threading.Thread(target=sub, )
a.start()
b.start()
# join 用于阻塞主线程,避免过早打印n
a.join()
b.join()
print(n)
print(time.time() - begin_time)
结果:
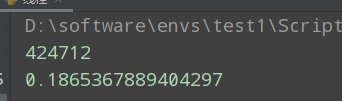
上面的程序对n做了同样数量的加法和减法,那么n理论上是0。但运行程序,打印n,发现它不是0。问题出在哪里呢,问题在于python的每行代码不是原子化的操作。比如n = n+1这步,不是一次性执行的。如果去查看python编译后的字节码执行过程,可以看到如下结果。
19 LOAD_GLOBAL 1 (n)
22 LOAD_CONST 3 (1)
25 BINARY_ADD
26 STORE_GLOBAL 1 (n)
从过程可以看出,n = n +1 操作分成了四步完成。因此,n = n+1不是一个原子化操作。
1.加载全局变量n,2.加载常数1,3.进行二进制加法运算,4.将运算结果存入变量n。
根据前面的线程释放GIL锁原则,线程a执行这四步的过程中,有可能会让出GIL。如果这样,n=n+1的运算过程就被打乱了。最后的结果中,得到一个非零的n也就不足为奇。
这就是为什么我们说GIL是粗粒度的,它只保证了一定程度的安全。如果要做到线程的绝对安全,是不是所有的非IO操作,我们都需要自己再加一把锁呢?答案也是否定的。在python中,有些操作是是原子级的,它本身就是一个字节码,GIL无法在执行过程中释放。对于这种原子级的方法操作,我们无需担心它的安全。比如sort方法,[1,4,2].sort(),翻译成字节码就是CALL METHOD 0。只有一行,无法再分,所以它是线程安全的。
总结
对于IO密集型应用,多线程的应用和多进程应用区别不大。即便有GIL存在,由于IO操作会导致GIL释放,其他线程能够获得执行权限**。由于多线程的通讯成本低于多进程,因此偏向使用多线程。**
对于计算密集型应用,多线程处于绝对劣势,可以采用多进程或协程。
解决线程资源竞争(线程同步,互斥锁)
无论是哪种方法使用了会大大延长程序执行的速度,所以线程根本不要用来执行大量计算任务,IO倒是可以,因为消耗的资源少,且一般不会对共享数据进行大量操作。
线程同步
join()方法使得主线程等待第一个线程执行完后,再执行第二个线程
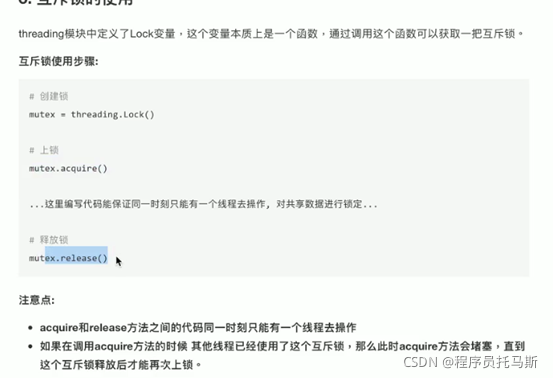
互斥锁
互斥锁:对共享数据进行锁定,保证同一时刻只能有一个线程去操作
注意:互斥锁是多个线程一起去抢,抢到的锁先执行,没有抢到的,需等待其余线程释放后,其他等待的线程再去抢这个锁。
2 互斥锁
随机执行其中一个线程,让剩下的线程等待
注意线程都要上锁 否则其余线程仍然可以使用全局变量
Rlock用法和Lock一致,区别说Rlock允许多次锁资源
线程锁的设置方式1
# import threading
import time
import threading
import multiprocessing
begin_time = time.time()
n = 0
lock = threading.RLock()
def add():
lock.acquire()
global n
for i in range(10000000):
n = n + 1
lock.release()
print("begin", n)
def sub():
lock.acquire()
global n
for i in range(10000000):
n = n - 1
lock.release()
print("end", n)
a = threading.Thread(target=add)
b = threading.Thread(target=sub)
if __name__ == "__main__":
a.start()
b.start()
a.join()
b.join()
print("time", time.time() - begin_time)
互斥锁的设置方式2 with语句 自动开关锁
# import threading
import time
import threading
import multiprocessing
begin_time = time.time()
n = 0
lock = threading.RLock()
def add():
# with 语句 自动开关
with lock:
global n
for i in range(10000000):
n = n + 1
print("begin", n)
def sub():
with lock:
global n
for i in range(10000000):
n = n - 1
print("end", n)
a = threading.Thread(target=add)
b = threading.Thread(target=sub)
if __name__ == "__main__":
a.start()
b.start()
a.join()
b.join()
print("time", time.time() - begin_time)
死锁
一直等待对方释放锁的情景就是死锁
线程间的通信
1 共享变量(不推荐)
因为线程全局GIL锁的原因,可能导致数据出错
2queue
在python中,多个线程之间的数据是共享的,多个线程进行数据交换的时候,不能够保证数据的安全性和一致性,所以当多个线程需要进行数据交换的时候,队列就出现了,队列可以完美解决线程间的数据交换,保证线程间数据的安全性和一致性(简单的来说就是多线程需要加锁,很可能会造成死锁,而queue自带锁。所以多线程结合queue会好的很多)
实际上就是生产者消费者模式,queue就是中间人,生产者把数据放进队列中,再由消费者消费。
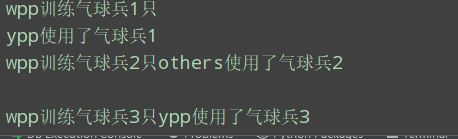
例子:
import time, threading
q = Queue(maxsize=0)
def product(name):
count = 1
while True:
q.put('气球兵{}'.format(count))
print('{}训练气球兵{}只'.format(name, count))
count += 1
time.sleep(0.5)
def consume(name):
while True:
print('{}使用了{}'.format(name, q.get()))
time.sleep(1)
q.task_done()
t1 = threading.Thread(target=product, args=('wpp',))
t2 = threading.Thread(target=consume, args=('ypp',))
t3 = threading.Thread(target=consume, args=('others',))
t1.start()
t2.start()
t3.start()
线程池的概念
参考学习笔记
系统启动一个新线程的成本是比较高的,因为它涉及与操作系统的交互。使用线程池可以很好地提升性能,尤其是当程序中需要创建大量生存期很短暂的线程时。
线程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量。
线程池的使用

import time
from asyncio import FIRST_COMPLETED
from concurrent.futures import ThreadPoolExecutor, as_completed, wait
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
# 指定线程池中最大线程数量
executor = ThreadPoolExecutor(max_workers=2)
# # 通过submit函数提交函数到线程中 会立即返回,不会堵塞
# task1 = executor.submit(get_html, (3))
# task2 = executor.submit(get_html, (2))
#
# # 取消还未进入线程池的线程
# print(task2.cancel())
# # done方法用于判定某个任务是否完成
# print(task1.done())
# time.sleep(4)
# print(task1.done())
# # result 方法 阻塞此线程 线程执行完毕后 返回一个指定的值
# print(task1.result())
# 获取已经成功的task的返回
urls = [5, 3, 4]
all_task = [executor.submit(get_html, (url)) for url in urls]
# 指定某个或某些线程阻塞,使其执行完成 return_when指定线程 默认全部
wait(all_task, return_when=FIRST_COMPLETED)
print("main", )
# as_completed就是一个生成器
# for future in as_completed(all_task):
# data = future.result()
# print("get {} page success".format(data))
# 通过executor的map获取已经完成的task的值 值的顺序和列表中相同
# for data in executor.map(get_html,urls):
# print("get {} page".format(data))
进程池的使用
import multiprocessing
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
if __name__ == '__main__':
# progress = multiprocessing.Process(target=get_html, args=(2,))
# 开启进程池,最大进程数为cpu的核数
pool = multiprocessing.Pool(multiprocessing.cpu_count())
# # 异步添加进程的任务
result = pool.apply_async(get_html, args=(3,))
# 等待所有任务完成
pool.close()
# 在使用join方法之前一定先使用close方法 降进程池关闭,不再接收新任务
pool.join()
# 执行任务 并返回任务的返回值
print(result.get())
# # imap方法 获取已经完成的task的值 值按列表顺序输出
# for result in pool.imap(get_html, [1, 5, 3]):
# print("{} sleep success".format(result))
# imap_unordered 哪个任务先完成就输出哪个任务的值
# for result in pool.imap_unordered(get_html, [1, 5, 3]):
# print("{} sleep success".format(result))
进程间的通信
1 使用 queue (multiprocessing中的queue不能用于pool进程池)
import time
from multiprocessing import Process, Queue
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Queue(10)
my_producer = Process(target=producer, args=(queue,))
my_consumer = Process(target=consumer, args=(queue,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
2 pool中的进程间通信需要使用manager中的queue
import time
from multiprocessing import Process, Queue, Pool,Manager
def producer(queue):
queue.put("a")
time.sleep(2)
def consumer(queue):
time.sleep(2)
data = queue.get()
print(data)
if __name__ == "__main__":
queue = Manager().Queue(10)
pool = Pool(2)
pool.apply_async(producer, args=(queue,))
pool.apply_async(consumer, args=(queue,))
pool.close()
pool.join()
3 pipe
pipe只能适用于两个进程,并且用于两个进程间通信时,效率较高,
因为queue中加了很多锁,降低了效率
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def producer(pipe):
pipe.send("b")
time.sleep(2)
def consumer(pipe):
print(pipe.recv())
if __name__ == "__main__":
receive_pipe, send_pipe = Pipe()
my_producer = Process(target=producer, args=(send_pipe,))
my_consumer = Process(target=consumer, args=(receive_pipe,))
my_producer.start()
my_consumer.start()
my_producer.join()
my_consumer.join()
4 Manger.Dict()
import time
from multiprocessing import Process, Queue, Pool, Manager, Pipe
def add_data(p_dict, key, value):
p_dict[key] = value
if __name__ == "__main__":
process_dict = Manager().dict()
first_process = Process(target=add_data, args=(process_dict, "bobby1", 1))
second_process = Process(target=add_data, args=(process_dict, "bobby2", 2))
first_process.start()
second_process.start()
first_process.join()
second_process.join()
print(process_dict)
进程线程的区别



进程只是占内存,线程才使用cpu
进程不共享全局变量,线程共享全局变量(因为开辟子进程是要对主进程进行拷贝)
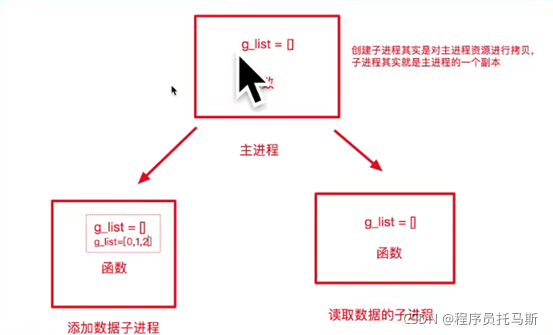
进程主要用于计算密集型,线程主要用于io密集型
进程线程上下文切换会用掉你多少CPU
协程
协程是轻量级的线程,它是实现多任务的另一种方式,只不过是比线程更小的执行单元。因为它自带CPU的上下文,这样只要在合适的时机,我们可以把一个协程切换到另一个协程。
协程的详细介绍
协程与线程的差异:
在实现多任务时, 线程切换__从系统层面__远不止保存和恢复CPU上下文这么简单。操作系统为了程序运行的高效性,每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作,所以线程的切换非常耗性能。但是__协程的切换只是单纯地操作CPU的上下文__,所以一秒钟切换个上百万次系统都抗的住。
协程究竟能比线程少多少开销
IO多路复用进制 (nginx主要使用)
通过Reactor的方式,可以将用户线程轮询IO操作状态的工作统一交给handle_events事件循环进行处理。用户线程注册事件处理器之后可以继续执行做其他的工作(异步),而Reactor线程负责调用内核的select函数检查socket状态。当有socket被激活时,则通知相应的用户线程(或执行用户线程的回调函数),执行handle_event进行数据读取、处理的工作。由于select函数是阻塞的,因此多路IO复用模型也被称为异步阻塞IO模型。注意,这里的所说的阻塞是指select函数执行时线程被阻塞,而不是指socket。一般在使用IO多路复用模型时,socket都是设置为NONBLOCK的,不过这并不会产生影响,因为用户发起IO请求时,数据已经到达了,用户线程一定不会被阻塞。
IO多路复用参考
面试常用
复制、深拷贝和浅拷贝的区别
学习链接
在python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,python并没有拷贝这个对象,而只是拷贝了这个对象的引用
一般有三种方法,
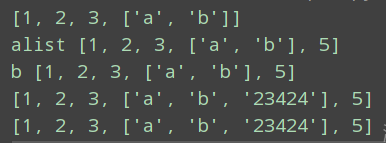
alist=[1,2,3,[“a”,“b”]]
1直接赋值,默认浅拷贝传递对象的引用而已,原始列表一改变,被赋值的b也会变。
alist = [1, 2, 3, ["a", "b"]]
b = alist
print(b)
alist.append(5)
print("alist", alist)
print("b", b)
alist[3].append("23424")
print(alist)
print(b)
end:
2 浅拷贝 ,拷贝最外层对象,但不拷贝子对象,所以原始数据改变,子对象会改变。
import copy
alist = [1, 2, 3, ["a", "b"]]
c = copy.copy(alist)
print(c)
print(alist)
alist.append(5)
# 最外层内存已被拷贝至新内存,所以最外层数据改变 原来的变量不变
# 但容器内部的可变对象没有拷贝内存,仍为引用 所以改变
print("alist", alist)
print("c", c)
print("alist,id", id(alist))
print("c,id", id(c))
print("alist[3]", alist[3])
alist[3].append("1111111")
print("alist", alist)
print("c", c)
print("alist[3],id", id(alist[3]))
print("c[3],id", id(c[3]))
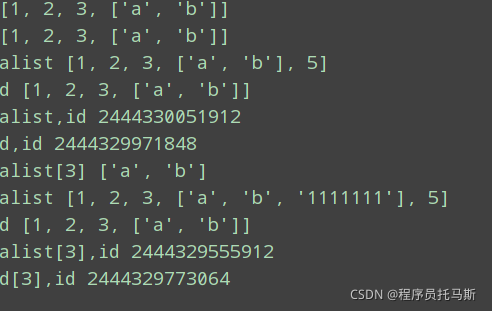
3深拷贝,对象里面的可变对象也拷贝到另外内存,所以原始对象的改变不会造成深拷贝里任何子对象的改变。
import copy
alist = [1, 2, 3, ["a", "b"]]
d = copy.deepcopy(alist)
print(d)
print(alist)
alist.append(5)
# 全部内存已被拷贝至新内存,所以数据改变 原来的对像不变
print("alist", alist)
print("d", d)
print("alist,id", id(alist))
print("d,id", id(d))
print("alist[3]", alist[3])
alist[3].append("1111111")
print("alist", alist)
print("d", d)
print("alist[3],id", id(alist[3]))
print("d[3],id", id(d[3]))
长连接和短连接
TCP/IP的三次握手和四次挥手
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan