”Flume“ 的搜索结果
Apache Flume是一个分布式,可靠且可用的系统,用于有效地收集,聚合大量日志数据并将其从许多不同的源移动到集中式数据存储中https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.5.1/
大数据技术之 Flume
欢迎使用Apache Flume! Apache Flume是一种分布式,可靠且可用的服务,用于有效地收集,聚合和移动大量日志数据。 它具有基于流数据流的简单灵活的体系结构。 它具有可调整的可靠性机制以及许多故障转移和恢复机制...
转载自天地风雷水火山泽。
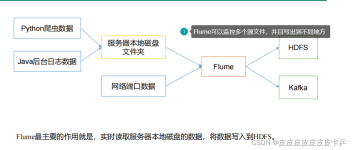
Flume1监控文件内容变动,将监控到的内容分别给到flume2和flume3,flume2将内容写到HDFS, Flume3将数据写到本地文件系统。 -f 表示flume启动读取的配置文件。监控端口,将数据打印至控制台。
Flume详解与安装实例
标签: Flume

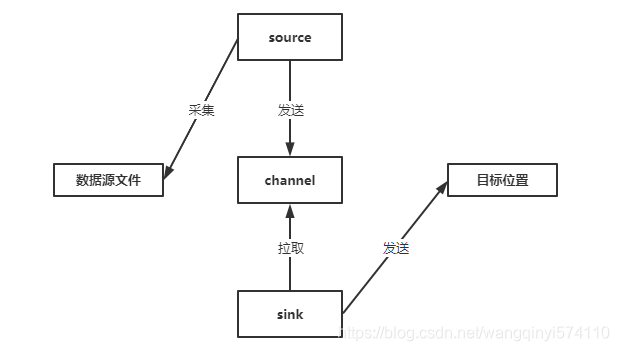
Flume 是一个分布式、可靠且高可用的日志收集和聚合系统。它是 Apache 基金会下的一个开源项目,旨在帮助用户轻松地从多个源收集、聚合和移动大量的日志数据。Flume 的架构包括三个核心组件:Source、Channel 和 ...
Flume包含三部分 Source:从哪收集,一般使用:avro(序列化),exec(命令行),spooling(目录),taildir(目录和文件,包含offset,不会数据丢失),kafka Channel:数据存哪里:(memory,kafka,file) Sink:数据输出到...
Flume二次开发,支持抽取MYSQL Oracle数据库数据 以JSON格式推送至Kafka。 demo: sql_json.sources.sql_source.type = com.hbn.rdb.source.SQLSource sql_json.sources.sql_source.connectionurl = jdbc:oracle:...
Flume基础架构、安装部署、入门案例、断点续传源码修改
使用Maven做成Jar包,在flume的目录下mkdir jar,上传此jar到jar目录中。#生成的文件类型,默认是 Sequencefile,可用 DataStream,则为普通文本。* @return event 根据业务处理后的event。* @param event 接收过滤...
实时数据流采集工具Flume
标签: flume

#FlumeConfig###A 可视化 Flume 编辑器## 版本:0.1.0 Flume 配置完全用 Javascript 编写并且是自包含的。 它允许您直观地布置 Flume 拓扑,输入源、通道和接收器的属性,并为您创建水槽配置文件。 它可以处理多个...
Flume部署和使用 官方文档: http://flume.apache.org/ example: WebServer –> Agent[Source–>Channel–>Sink] –> HDFS 一.简介 Flume是一个分布式,可靠的的框架,它能从许多不同的数据源高效地收集、聚合和移动...
Flume本身是由Cloudera公司开发的后来贡献给了Apache的一套针对日志进行收集(collecting)、汇聚(aggregating)和传输(moving)的分布式机制。图-1 Flume图标Flume本身提供了较为简易的流式结构,使得开发者能够较为...
这里的目的是根据头文件的不同,发往不同的channel,然后发往不同的sink需要自己写一个jar包,这里相当于是自己给netcat的信息增加的头文件,如果信息中含有"lmx’,则在头信息中加入 type:lmx,反之加入type:other@...
flume-ng-sql-source 该项目用于与sql数据库进行通信 当前支持SQL数据库引擎 在最后一次更新之后,该代码已与hibernate集成在一起,因此该技术支持的所有数据库均应正常工作。 编译与包装 $ mvn package 部署方式 ...
文章目录Flume优化一、内存参数优化(减少GC)1)-xmx和-xms设置相同值,避免在 GC 后调整堆大小带来的压力。2)JVM heap(堆内存)设置4G或更高二、channel优化Flume如何保证数据安全(高可用)事务机制Flume解决...
尚硅谷大数据技术之Flume
flume_exporter 普罗米修斯水槽出口商。 要运行它: make build ./flume_exporter [flags] 标志帮助: ./flume_exporter --help 配置:config.yml agents: - name: "flume-agents" enabled: true # ...
绑定数据来源为r1#绑定source与sink之间的通道channel#绑定数据流向的最终目的地#配置Source#这里的source是netcat,通过NC发出TCP请求获取数据#端口所在的地址,表示从本地获取数据#绑定端口号,配置监听的端口#...
项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 项目开发 系统设计 Spark 机器学习 大数据 算法 源码 ...
大数据笔记,包含Hadoop、Spark、Flink、Hive、Kafka、Flume、ZK...... 大数据笔记,包含Hadoop、Spark、Flink、Hive、Kafka、Flume、ZK...... 大数据笔记,包含Hadoop、Spark、Flink、Hive、Kafka、Flume、ZK.......
这是已经编译好的flume包,可以直接用于集成在Ambari上
flume+kafka+flink+mysql实现nginx数据统计与分析
由于flume官方并未提供ftp,source的支持; 因此想使用ftp文件服务器的资源作为数据的来源就需要自定义ftpsource,根据github:https://github.com/keedio/flume-ftp-source,提示下载相关jar,再此作为记录。
推荐文章
- Zotero参考文献引用(适用国内)_zotero如何引用知网文献-程序员宅基地
- 智慧医院整体解决方案(医院信息化建设)PPT-程序员宅基地
- 利用定时器中断方式控制led灯的闪烁速度_项目四 定时器和中断概念的基本认识...-程序员宅基地
- 基于WVP的轻量化智能监控平台-程序员宅基地
- Scratch3.0 页面初始化的时候加载sb3文件_js 实现scrach sb3 播放器-程序员宅基地
- R语言实现Logistic回归的五折交叉验证_r 5折logistic回归的数据要求-程序员宅基地
- 基于SpringBoot+Vue的电商个性化推荐系统(源码+文档+部署+讲解)_电商推荐系统代码-程序员宅基地
- 在python中、函数可以分为哪4类_python里常用的函数类型-程序员宅基地
- Ubuntu无法检测到外接显示器,无法打开nvidia-settings或者打开nvidia-settings时有报错,ubuntu-drivers devices命令后无显示-程序员宅基地
- 解读吴恩达新书《Machine Learning Yearning》系列(二)-程序员宅基地