
”PPO算法“ 的搜索结果
李宏毅强化学习ppo算法ppt
标签: ppo
李宏毅强化学习ppo算法ppt
强化学习PPO算法.zip
标签: PPO DL
强化学习PPO算法论文
PPO算法是一种强化学习中的策略梯度方法,它的全称是Proximal Policy Optimization,即近端策略优化1。PPO算法的目标是在与环境交互采样数据后,使用随机梯度上升优化一个“替代”目标函数,从而改进策略。PPO算法的...
基于李宏毅课程总结
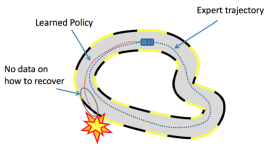
1. 背景介绍 强化学习作为人工智能领域的重要分支,近年来取得了显著的进展。...PPO(Proximal Policy Optimization)算法作为策略梯度方法的一种,因其简单易用、稳定性强等优点,成为了强化学习领域的主流算法之一。
1. 背景介绍 1.1 强化学习与策略梯度方法 强化学习 (Reinforcement Learning, RL) 是机器学习的一个重要分支,它研究智能体 (agent) 如何在一个环境 (environment) 中通过与环境进行交互学习到最优策略 (policy),...

PPO算法之所以被提出,根本原因在于在处理连续动作空间时取值抉择困难。取值过小,就会导致深度强化学习收敛性较差,陷入完不成训练的局面,取值过大则导致新旧策略迭代时数据不一致,造成学习波动较大或局部震荡。...
(1)在中国A股市场15只股票上的应用 (2)构建投资组合 (3)每日调仓 (4)绘制收益率曲线 (5)PPO算法
PPO(Proximal Policy Optimization) 最好先看一下策略梯度优化,再看这篇文章,不然公式推不明白 PPO是Openai默认的强化学习策略 On-policy:学习的agent和与环境交互的agent是同一个 ∇Rˉθ=Eτ∼pθ(τ)[R(τ...
1. 背景介绍 1.1 强化学习与策略梯度方法 强化学习 (Reinforcement Learning, RL) 作为机器学习的一个重要分支,专注于...策略梯度方法是强化学习中的一类重要算法,它通过直接优化策略来最大化期望回报。PPO (Proxim
PPO算法基本原理及流程图(KL penalty和Clip两种方法)
接着上面的讲,PG方法一个很大的缺点就是参数更新慢,因为我们每更新一次参数都需要进行重新的采样,这其实是中on-policy的策略,即我们想要训练的agent和与环境进行交互的agent是同一个agent;...
_python_代码_下载 ...在mujoco环境下实现PPO算法,如Ant-v2、Humanoid-v2、Hopper-v2、Halfcheeth-v2。 用法 $ python main.py --env_name Hopper-v2 更多详情、使用方法,请下载后阅读README.md文件
1. 背景介绍 1.1 强化学习与策略梯度方法 强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,...策略梯度方法作为强化学习算法的一种,通过直接优化策略参数来最大化期望回报,在解决复杂决策问题上取
探索PPO算法实现细节: 一个深度强化学习的高效工具 项目地址:https://gitcode.com/vwxyzjn/ppo-implementation-details 在这个快速发展的AI时代,深度强化学习 (DRL) 已经成为了许多复杂问题的解决方案,比如游戏、...
现在已经有包括DQN,DDPG,TRPO,A2C,ACER,PPO在内的近十种经典算法实现,同时它也在不断扩充中。它为对RL算法的复现验证和修改实验提供了很大的便利。本文主要走读其中的PPO(Proximal Policy Optimization)算法的...
其中理论部分会介绍PPO算法的推导流程,代码部分会给出PPO算法的各部分的代码以及简略介绍,实践部分则会通过debug代码调试的方式从头到尾的带大家看清楚应用PPO算法在cartpole环境上进行训练的整体流程,进而帮助...
这意味着动作的选择是通过一组实数或向量来表示的,而不是通过离散的标识符。例如,一个机器人在连续的动作空间中选择它的速度和方向,这两个参数可以是实数,表示机器人在每个时刻的线速度和角速度。...
PPO算法及其改进方法 1. 背景介绍 强化学习是机器学习的一个重要分支,近年来在游戏、机器人控制、自然语言处理等领域取得了广泛的应用。其中,基于策略梯度的方法如REINFORCE、Actor-Critic等是强化学习的一个重要...
在线学习和离线学习 在线学习:和环境互动的Agent以及和要学习的Agent是同一个, 同一个Agent,一边和环境做互动,一边在学习。 离线学习:和环境互动及的Agent以和要学习的Agent不是同一个,学习的Agent通过看别人...
探索PPO算法:面向初学者的实现与应用指南 项目地址:https://gitcode.com/ericyangyu/PPO-for-Beginners 该项目,由ericyangyu在GitCode上分享,是一个为初学者设计的Proximal Policy Optimization (PPO)算法实现。...
强化学习中的PPO算法微观拆解。在强化学习中,Rollout是指在给定的策略下模拟环境的过程。在PPO中,Rollout的过程对应于根据当前的语言模型(策略)生成文本(轨迹)。这个过程依赖于在prompt库中抽取的一个batch的...
强化学习PPO
Actor 网络输出在给定状态stπθat∣st)].PPO 迭代地更新这个 policy,以改进策略并提高性能。
强化学习之 PPO 算法
标签: 深度学习
PPO 算法是一种基于策略的、使用两个神经网络的强化学习算法。通过将“智体”当前 的“状态”输入神经网络,最终会得到相应的“动作”和“奖励”,再根据“动作”来更新 “智体”的状态,根据包含有“奖励”和...

推荐文章
- c语言课程图书信息管理系统,c语言课程设图书信息管理系统.doc-程序员宅基地
- webpack4脚手架搭建1——打包并编译es6_webpack编译es6语法打包-程序员宅基地
- 信息通信服务、电子商务及物流服务的创新与发展_信息通信,电子商务-程序员宅基地
- websocket.js的封装,包含保活机制,通用_websocket保活-程序员宅基地
- Ubuntu安装conda-程序员宅基地
- LoadRunner性能测试关注指标及结果分析_loadrunner性能指标分析-程序员宅基地
- java怎么做图形界面_java怎么做图形界面?实例分享-程序员宅基地
- eMMC常识性介绍N_emmc温升系数-程序员宅基地
- MATLAB算法实战应用案例精讲-【人工智能】机器视觉(概念篇)(最终篇)-程序员宅基地
- Mac电脑如何串流游戏 Mac上的CrossOver是串流游戏吗 串流游戏是什么意思 串流游戏怎么玩 Mac电脑怎么玩Steam游戏_macos steam和crossover steam区别-程序员宅基地