集成电路和晶体管的瞬态电压保护,4008315889 ESD和I/O保护 EFT和突发保护 便携式设备保护,如手机、PDA 优势说明: 出色的ESD箝位和较小的插入损耗 高瞬态电流能力,zui快的响应时间 电容设计为超低值,可有效适用...
”RL“ 的搜索结果
产品型号:1N4007RL最大平均正向电流(A):1峰值反向电压VRRM(V):1000最大全周期正向压降VFM(V):1.100最大非重复浪涌电流IFSM(A):30最大反向电流IR(mA):0.010封装/温度(℃):DO41/-65~175价格/1片(套):¥.25
RL_内存 为RL代理配备内存
竞争性RL环境 在此仓库中,我们提供了两个有趣的竞争性RL环境: 竞争性乒乓球(cPong):这种环境将经典的Atari Game Pong扩展到竞争性环境中,双方都可以成为可训练的代理商。 竞争性赛车(cCarRacing):该环境...
SparkFun USB 转 FIFO-FT245RL 突破 FTDI 流行的 USB 到 FIFO IC 的基本分线板。 存储库内容 /Hardware - 所有 Eagle 设计文件(.brd、.sch、.STL) 许可证信息 该硬件是在下发布的。 按原样分发; 不提供任何保证...
RLCard是一款卡牌游戏强化学习 (Reinforcement Learning, RL) 的工具包。 它支持多种卡牌游戏环境,具有易于使用的接口,以用于实现各种强化学习和搜索算法。 RLCard的目标是架起强化学习和非完全信息游戏之间的桥梁...
rl-games
RL 瓷砖很棒,但我还想要一些东西: 透明背景 来自 NetHack 套装和 Dungeon Crawl 套装的所有 2D 图块 (name → index) JSON 格式的元数据 重复数据删除 地图中的体面排序(所有怪物、所有物品、所有地牢功能) ...
内容欢迎! 该存储库包含用于Medipixel的研究活动的强化学习算法。 源代码将经常更新。 我们热烈欢迎外部贡献者! :) LunarLanderContinuous-v2上的BC代理PongNoFrameskip-v4上的RainbowIQN代理Reacher-v2上的SAC...
图RL 先决条件 numpy,matplotlib,gensim,pygsp 代码结构 GraphRL / lspi 此文件夹中的代码基于此LSPI python软件包构建。 最小二乘策略迭代(LSPI)实现。 实现本文描述的算法 “最小二乘策略迭代。” ...
IQOption_Trading_with_RL:IQOption交易与强化学习
RL导航优化 使用RL解决导航拥塞问题
该方案支持使用瑞萨 RL78/G1H MCU 在充电板与主控制板之间进行 sub-GHz 通信;使用 ZAMC4100 电机控制器驱动 BLDC;使用 ISL85413 降压稳压器、ISL85403 升压降压转换器及 ISL80510 LDO 高效管理电源。 主要特性高度...
人脸识别功能使用源码需要注意的是图片格式必须是RGB_565
该库实现了强化学习代理的核心组件。 目标是拥有可灵活组合在一起的可... from rl . policy . EpsilonGreedy import EpsilonGreedy from rl . estimation_updater . MonteCarlo import MonteCarlo mc = MonteCarlo ()
RL飞扬的鸟 概述 该项目是强化学习的基本应用。 它集成了以使用DQN来训练代理。 预训练模型在单个GPU上以3M步进行训练。 您可以找到解释培训过程的,或。 构建项目并运行 该项目支持使用Maven进行构建,您可以使用...
Self RAM list of Flash Self-Programming Library for RL78 Family
使用强化学习完成股票预测。强化学习是机器学习的另一个分支,在决策的时候采取合适的行动 (Action) 使最后的奖励最大化。与监督学习预测未来的数值不同,强化学习根据输入的状态(如当日开盘价、收盘价等),输出...
试试RL-ROBOT: import exp import rlrobot exp.ENVIRONMENT_TYPE = "MODEL" # "VREP" for V-REP simulation exp.TASK_ID = "wander_1k" exp.FILE_MODEL = exp.TASK_ID + "_model" exp.ALGORITHM = "TOSL" exp....
只要有足够的Deep RL从业人员来实施,难以设计的行为就可以轻松解决。 以下笔记本(文件以.ipynb结尾)详细介绍了如何使用简单的Policy Gradient技术在Keras中训练玩Pong游戏的模型: 文件概述 # Main notebooks ...
瑞萨RL78系列数据手册,汽车电子行业常用芯片类型
DQ-RL
sumo-rl-master.zip
此函数生成分数阶的根轨迹 (RL) 图传递函数(对于 LTI 系统)。 第一个图是 RL 上的s 平面,第二个图是 s 平面第 1 个黎曼表上的 RL 输入是分子和分母多项式系数, 和基本阶 lambda(即的最小公分母) 分子和分母的...
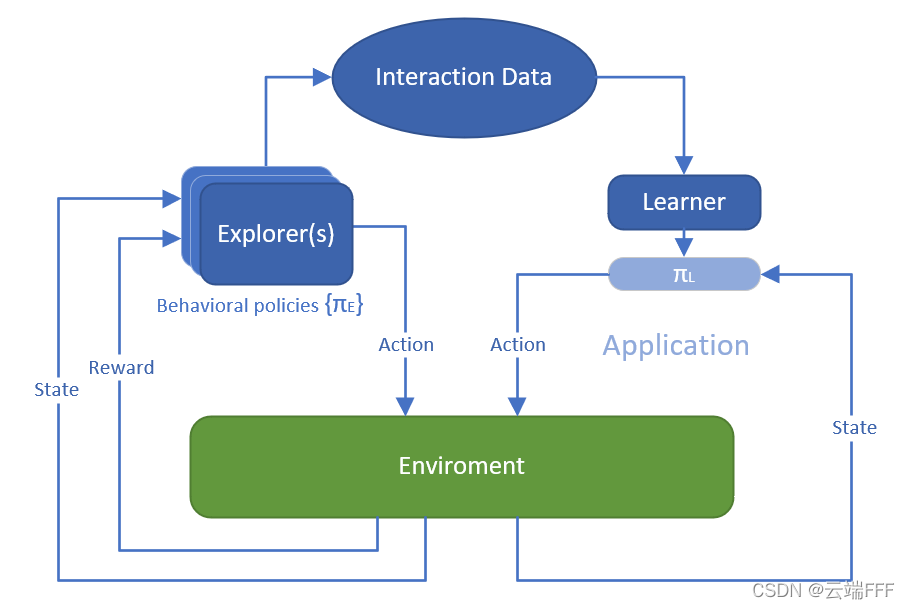
避免rl冲突 这是本文的Pytorch实施,旨在 要求 python2.7 如何训练 您可以从在Stage1中进行培训开始,经过良好的培训后,您可以根据Stage1的策略模型转移到Stage2,这正是课程学习的意义。 从头开始训练Stage2可能会...
该计算器绘制了串联 RC/RL 电路中电容器/电感器的电压、电流、功率和存储能量与时间的关系图。 可以调整几个参数,例如电压源的电动势 (E)、电阻 (R)、电容 (C)/电感 (L)、瞬态阶段的开始 (T) 或初始电压电容 (V0)/...
使用 DDPG、PPO 和 TRPO 实现 CORE-RL 算法的代码。 我们已经包含了三种环境的代码:Car-Following、CartPole 和 TORCS Racecar Simulator。 每个文件夹都包含一个 README 文件,其中包含有关运行算法的更多信息。 ...
但是,由于错误,框架差异和超参数敏感性,RL论文可能很难复制。关于本文培训了代理商以选择良好的加密货币组合。 据报道,它可以在50天之内获得4倍的回报,而且该论文似乎做得很好,所以我想看看我是否能达到相同...
9This project is for implementation of Q-Learning algorithm for world grid navigation
推荐文章
- 第九十四篇 Spark+HDFS centos7环境搭建_spark写入hdfs需要用户名密码吗-程序员宅基地
- Node.js_node可以使用什么命令 ,它会自动找到该文件下的start指令,执行入口文件。-程序员宅基地
- linux图片相似度检测软件下载,移动端图像相似度算法选型-程序员宅基地
- java isprime函数_判断质数(isPrime)的方法——Java代码实现-程序员宅基地
- 2.小白学uvm验证 - uvm_objection 和 uvm_component_uvm_object accessor 参数的意义-程序员宅基地
- Url 访问大小写敏感问题解决-程序员宅基地
- gin 渲染不同目录下的模板(支持多层目录)_gin 加载多层模板-程序员宅基地
- java file数组 初始化_Java数组的定义,声明,初始化和遍历-程序员宅基地
- 十四章上机1_北大青鸟java第十四章上机练习4-程序员宅基地
- React路由 报错 ‘Switch‘ is not exported from ‘react-router‘.-程序员宅基地