Dynamic file detection tool based on crawler 基于爬虫的动态敏感文件探测工具
”Web爬虫“ 的搜索结果
Here is a collection of my web crawler repositories. 提示: 克隆后请使用以下命令获取子仓库 Hint: Please use the following command to get the sub-repositories after cloning. git submodule update --init
flask_collect包含数个flask项目、精简的webframework、爬虫、数据结构、rpc、chat等等
Heritrix是一个开源,可扩展的web爬虫项目。用户可以使用它来从网上抓取想要的资源。Heritrix设计成严格按照robots.txt文件的排除指示和META robots标签。其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取...

Python基础、Pygame游戏编程、Python算法与面试题、四种常用的Python Web框架、爬虫、数据可视
V2EX爬虫
标签: Python开发-Web爬虫
一个爬虫框架 Scrapy 来一步步实现爬取 V2EX 首页所有的热门文章
爬虫,即网络爬虫,是一种自动获取网页内容的程序。是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索...

在信息化的时代,网络爬虫已经成为我们获取和处理大规模网络数据的重要工具。如果将现有网络上的海量数据使用爬虫工具将数据爬取保存下来,并进行分析,就可以挖掘出一些潜在的价值。而现在市面上也出现了很多爬虫...
基于浏览器爬虫golang开发的web漏洞主动(被动)扫描器.zip
||| |||||介绍平台以流程图的方式定义爬虫,是一个高度灵活可配置的爬虫平台特性支持Xpath / JsonPath / css选择器/正则提取/混搭提取支持JSON / XML /二进制格式支持多数据源,SQL select / selectInt / selectOne ...
Python基础、Pygame游戏编程、Python算法与面试题、四种常用的Python Web框架、爬虫、数据可视化、机器学习。一共七个Python大方向!
最近看到很多同学都在研究爬虫,然后我想到了一款尘封已久的插件,很早之前在我刚接触爬虫的时候用过,不过自从上了python爬虫过后,慢慢就搁置了,今天花时间撸一篇教程,给同学们安利这款插件,如果刚开始学爬虫,...
爬虫,同花顺,用于爬取公司名称和代码,可以再上面扩展,基于selenium的框架写得
它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。 Scrap,是碎片的意思,这个Python的爬虫框架叫Scrapy。 优点: 1.极其灵活的定制化爬取。 2.社区人数比较多、...
在第一个控件先输入一个范围数字i作为学号 然后密码是234 然后登陆 然后登陆 然后保存页面 然后for i加一
您首选的面向deep web的开源爬虫程序。
京东抽奖爬虫LiteVersion
网络爬虫我用于个人项目的网络爬虫存储库
批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。
Go语言实现的教务系统爬虫 web界面实现使用Go语言模拟登录正方教务系统2018.1.5增加一键教学评价功能演示版此项目已停止维护!
基千爬虫技术的web招聘数据挖掘研究.pdf
python-web-scrape 记录北理python爬虫课程的作业,课程地址:
Grab:Web爬虫Python框架
基于Spark的电影推荐系统,包含爬虫项目、web网站、后台管理系统以及spark推荐系统.zip
经推荐,我用上了 Web Scraper 这个插件,发现上手简单,傻瓜式操作,而且最重要的是没有被京东很快地拦截掉,能比较顺利地爬到数据,所以写这篇博客记录一下使用方法,以备后续需要并和大家分享。
无依赖极简网络爬虫组件,能在移动设备上运行的微型爬虫。没有第三方依赖jar包。减少内存使用。提高CPU利用率。加快网络爬取速度。简洁明了的api接口。能在Android设备上稳定运行。小巧灵活可以方便集成的网页抓取...
谈谈你对爬虫和反爬虫的理解?
标签: 爬虫
谈谈对爬虫和反爬的理解 A.爬虫 爬虫的定义: 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。从功能上来讲,...
推荐文章
- 机器学习之超参数优化 - 网格优化方法(随机网格搜索)_网格搜索参数优化-程序员宅基地
- Lumina网络进入SDN市场-程序员宅基地
- python引用传递的区别_php传值引用的区别-程序员宅基地
- 《TCP/IP详解 卷2》 笔记: 简介_tcpip详解卷二有必要看吗-程序员宅基地
- 饺子播放器Jzvd使用过程中遇到的问题汇总-程序员宅基地
- python- flask current_app详解,与 current_app._get_current_object()的区别以及异步发送邮件实例-程序员宅基地
- 堪比ps的mac修图软件 Pixelmator Pro 2.0.6中文版 支持Silicon M1_pixelmator堆栈-程序员宅基地
- 「USACO2015」 最大流 - 树上差分_usaco 差分-程序员宅基地
- Leetcode #315: 计算右侧小于当前元素的个数_找元素右边比他小的数字-程序员宅基地
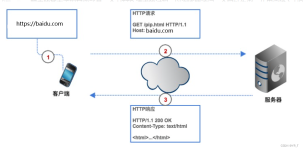
- HTTP图解读书笔记(第六章 HTTP首部)响应首部字段_web响应的首部内容-程序员宅基地