前言 此前尝试爬取蚂蜂窝帖子的图片:...经过研究,这个问题得到了解决,重新写一篇博客记录一下。 声明:游记为随机选择,爬取图片仅为个人练习,侵删。 蚂蜂...
”XHR如何爬虫“ 的搜索结果
zhuanlan.zhihu.com直接介绍一下具体的步骤以及注意点:instagram 爬虫注意点instagram 的首页数据是 服务端渲染的,所以首页出现的 11 或 12 条数据是以 html 中的一个 json 结构存在的(additionalData), 之后...

在爬虫实践当中,如果我们爬取的页面的编写没有做好板块的区分,或者我们选取的标签不合适,最终我们获得的结果会多提取到出一些奇怪的东西。 当使用用request获取的网页源代码里没有我们想要的数据时,需要重新...
复习:上一关,我们使用两种方式,爬取了豆瓣新片榜的清单,内含:电影名、URL、电影基本信息和电影评分信息。代码如下:import requests# 引用requests库from bs4 import BeautifulSoup# 引用BeautifulSoup库headers...
在爬取到... 随便点开一个就可以看到我们真正访问的URL地址: 从这里我们就可以清楚的在xhr返回的header里面看到异步请求的url,这里我们直接访问该url(或者在preview里面可以看到返回的数据...
首先感谢Darkeril博主的这篇文章,让我知道异步爬取的原理。下面我们开整!! 二话不说先上代码,客官请看: #coding:utf-8 from bs4 import BeautifulSoup import requests import json ...de
1. 网站分析本文实现的爬虫是抓取京东商城指定苹果手机的评论信息。使用 requests 抓取手机评论 API 信息,然后通过 json 模块的相应 API 将返回的 JSON 格式的字符串转换为 JSON 对象,并提取其中感兴趣的信息。...
刚学完Python和爬虫,想实践一下,于是选定目标为这个学期使用的在线编程网站 网站如图,要爬取的是第二部分,Python语言练习 ** 思路分析: ** 课程看的是MOOC上北京理工大学嵩天老师的课程,这个网站与课程中给出...




python爬虫如何POST request payload形式的请求1. 背景最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数据格式(Form data)。而使用Form data数据的提交方式时...
右键选择查看网页源码,我们可以发现在...通过检查网页,查看network下的XHR,我们可以找到对应的信息。说明我们想要爬取的这部分内容是通过Ajax从后台拿到的json数据。copy link address得到访问的url:https://mov...
xhr类型即通过方法发送的请求,也就是我们说的Ajax请求,显示的应该是js代码发起的异步请求;xhr这个标签出现在Chrome浏览器的开发者工具network选项卡中;用于筛选多有的xhr类型的请求,达到只看xhr类型请求的目的...
# !/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2018-07-06 12:30:04 # Project: test1 from pyspider.libs.base_handler import * class Handler(BaseHandler): crawl_config = { ...
爬虫就是自动获取网页内容的程序,例如搜索引擎,Google,Baidu 等,每天都运行着庞大的爬虫系统,从全世界的网站中爬虫数据,供用户检索时使用。爬虫流程其实把网络爬虫抽象开来看,它无外乎包含如下几个步骤模拟...
AI的发展日新月异,及时掌握一些AI的消息和妹子聊天时也不至于词穷(不建议和妹子聊技术)...这就是我使用爬虫爬取AI新闻的过程,使用了两个爬虫中比较常见的典型案例。像这种类别信息的采集,还有更优的程序设计架构。
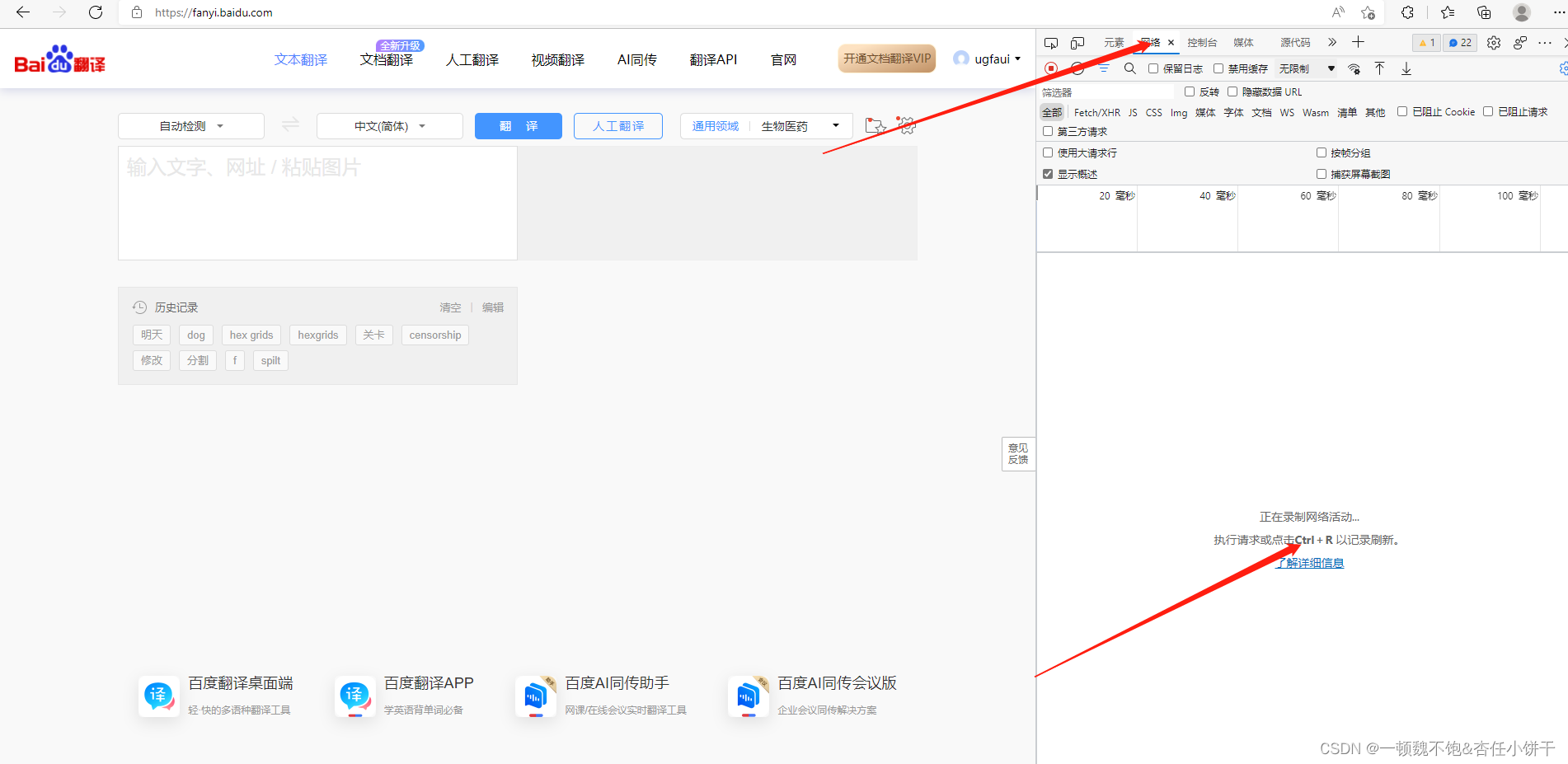
仅查看XHR,一种不借助刷新即可传输数据的对象 Doc Document,第0个请求一般在这里。(第0个请求:浏览器的框架) Img 仅查看图片 Media 仅查看媒体文件 JS和CSS 前端代码,负责发起请求和页面实现 Front ...
下面的就是请求网页的xhr,preview并没有任何数据 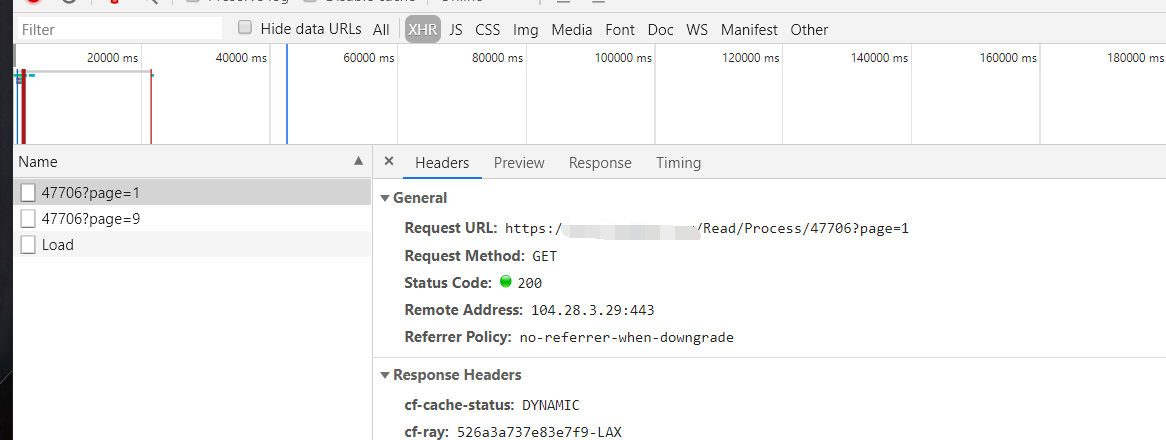 这个就是load的xhr所有数据 ![图片说明]...

XHR是前端异步请求数据的一种技术,Python爬虫在获取网页数据时通常需要解析XHR数据,以便从中提取有用的信息。 首先,在Python中可以使用第三方库requests来获取XHR数据。通过先分析网页的XHR请求URL、请求参数和...
需要获取机场航班数据 ...其航班数据是动态加载进来的,通过F12并刷新后得到 ...!... 现在的问题是我有数千个机场的url地址,手动F12找到每个机场的航班地址是无法想象的,所以有没有方法自动获得每个机场请求航班数据的那个...
需求是这样的,我需要写一个爬虫把 http://www.bjbus.com/home/fun_news_list.php?uNewsType=1&uStyle=1 上的所有list和其中的链接爬下来并每天定时查看有没有新的公告。进行简单的 response = urllib2.urlopen('...
首先感谢Darkeril博主的这篇文章,让我知道异步爬取的原理。下面我们开整!!二话不说先上代码,客官请看:#coding:utf-8from bs4 import BeautifulSoupimport requestsimport jsonimport pymongourl = '...
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地