”hive“ 的搜索结果
文章目录Hive安装配置一、Hive安装地址二、Hive安装部署1. 把 `apache-hive-3.1.2-bin.tar.gz`上传到Linux的/export/software目录下2. 解压`apache-hive-3.1.2-bin.tar.gz`到/export/servers/目录下面3. 修改`apache...

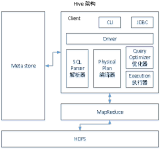
Hive基本概念 是一个基于hadoop的数据仓库工具,可以将结构化数据映射成一张数据表,并提供类SQL的查询功能。 Hive的意义是什么 背景:hadoop是个好东西,但是学习难度大,成本高,坡度陡。 意义(目的)...
Hive分区应用实战
Hive和Spark
标签: hive
1. Hive简介 hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析...
Hive数据类型支持的类型原始数据类型注意DATE类型整数类型小数、Boolean、二进制文本类型时间类型类型转换隐式转换显示转换(CAST函数)复杂数据类型详解ARRAY和MAPSTRUCTUNION实例 支持的类型 hive支持两种数据...
idea连接Hive
标签: hive
Hive 的Hive_x.x.x_bin.tar.gz 高版本在windows 环境中缺少 Hive的执行文件和运行程序。配置文件目录(%HIVE_HOME%\conf)有4个默认的配置文件模板拷贝成新的文件名。可以发现,自动连接MySQL去创建schema hive,并...
hive


jdbc连接Hive
标签: hive
jdbc连接Hive 1.使用sqoop将stu表导入到hive中 数据库表位于hadoop102上的test数据库 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/test \ --username root \ --password 000000 \ --table stu ...
hive入门以及dbeaver连接hive

hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为...

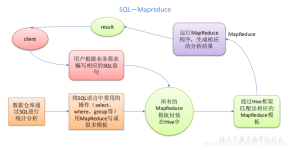
hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户书写的SQL语句翻译成MapReduce代码,然后发布...
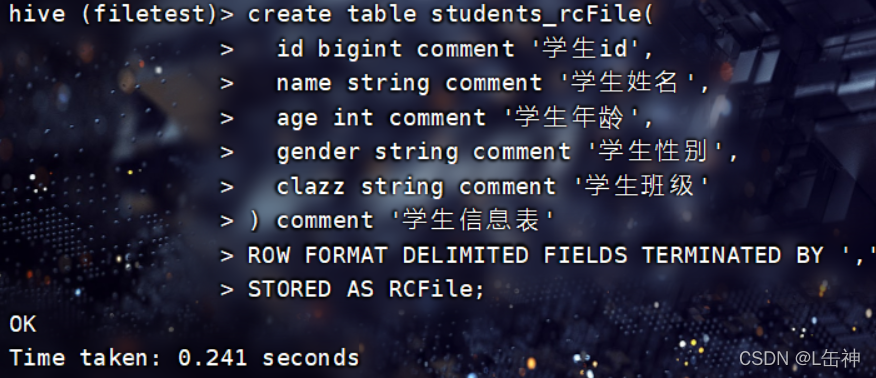
Hive建表语句
很多人会认为Hive命令行只是一个执行HQL语句的控制台,其实它没你想的那么简单,还有很多实用的用法,这里就简单介绍一下。 查看Hive的帮助文档 [hdfs@cdh01 ~]$ hive -H usage: hive -d,--define <key=value>...
启动hive
Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database tpch_textfile is not empty. One or ...
Hive 远程连接配置
标签: hive
Hive 远程连接配置 1、配置 hive-site.xml 中的内容 打开 hive-site.xml 搜索 hive.server2.thrift.bind.host 如果存在则修改 value 值为 本机 域名或 ip <property> <name>hive.server2.thrift.bind....
Hive动态分区一)hive中支持两种类型的分区:二)实战演示如何在hive中使用动态分区 一)hive中支持两种类型的分区: 静态分区SP(static partition) 动态分区DP(dynamic partition) 静态分区与动态分区的主要...
Hive on Spark配置
标签: hive

Hive Metastore服务
标签: hive
1、Hive 元数据存储 将元数据存储在关系数据库中(MySql、Derby),元数据包括表的属性、表的名称、表的列、分区及其属性以及表数据所在的目录等。 2、Metastore服务作用 客户端连接metastore服务,metastore再去...
Hive特点 1.针对海量数据的高性能查询和分析系统 由于 Hive 的查询是通过 MapReduce 框架实现的,而 MapReduce 本身就是为实现针对海量数据的高性能处理而设计的。所以 Hive 天然就能高效的处理海量数据。 与此同时...
Hive与Hadoop的关系3. Hive中的命令3.1 创建数据库并指定hdfs存储位置3.2 修改数据库3.3 查看数据库信息3.4 创建表并指定字段之间的分隔符4. Hive中的四种表结构4.1 内部表4.2 外部表4.3 分区表4.4 分桶表 1. 概念 ...
推荐文章
- 服务器无法与DeviceNetBT_Tcpip_{670E1543-79C1-485C-9B4B-835CE3BA37B3}传输相绑定-程序员宅基地
- NYOJ 118 修路方案(次小生成树)-程序员宅基地
- 【期末复习】微机原理与接口技术_己知 8254 的端口地址为 3000h、3004h3008h 和 30bh外接时钟频率为 2mh2-程序员宅基地
- 2D转换,动画,转化-程序员宅基地
- 旋转拖动验证码解决方案_load_model("keras2.hdf5", custom_objects={'angle_e-程序员宅基地
- Windows下后台静默运行jar包_windows下启jar包关闭窗口不听-程序员宅基地
- windows7的aero的介绍-程序员宅基地
- libevent与libev简介_libevent libev-程序员宅基地
- zookeeper启动Error: JAVA_HOME is incorrectly set问题解决_error: java_home is incorrectly set: e:\java\jdk1.-程序员宅基地
- 操作系统概述_多道批处理系统算不算操作系统-程序员宅基地