Scrapy爬取新浪微博用户信息、用户微博及其微博评论转发
”scrapy“ 的搜索结果
WSGI和Scrapy 关于Scrapy Stackoverflow的一个常见问题是“如何在Flask,Django或任何其他Python Web框架中使用Scrapy?” 大多数工具都习惯于使用Scrapy生成的项目和cli选项,这使抓取工作变得轻而易举,但在尝试将...
1. Scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也...
这是一个用python3中的scrapy框架实现爬取京东手机商品信息(手机名称,手机价格,手机图片),存入mysql数据库的案例。
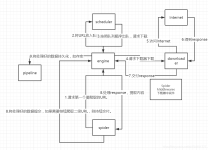
精通Python爬虫框架Scrapy.pdf
主要给大家介绍了利用python爬虫框架scrapy爬取京东商城的相关资料,文中给出了详细的代码介绍供大家参考学习,并在文末给出了完整的代码,需要的朋友们可以参考学习,下面来一起看看吧。
This book covers the long awaited Scrapy v 1.0 that empowers you to extract useful data from virtually any source with very little effort. It starts off by explaining the fundamentals of Scrapy ...
系统是采用的Django+Scrapy+Mysql三层架构进行开发的,主要思路是我们通过scrapy框架进行微博热点的爬取,经过一系列的处理最终成为我们想要的item,然后存入mysql数据库,最后Django从数据库中读取数据在网页上输出...
通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首 通过 scrapy 爬虫架构爬取中国古诗网的 唐诗三百首
解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫
主要介绍了Python利用Scrapy框架爬取豆瓣电影,结合实例形式分析了Python使用Scrapy框架爬取豆瓣电影信息的具体操作步骤、实现技巧与相关注意事项,需要的朋友可以参考下
主要介绍了Python Scrapy多页数据爬取实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
Scrapy MongoDB队列基于MongoDB的scrapy组件,允许分布式爬网可用的Scrapy组件排程器复制过滤器安装来自pypi $ pip install git+https://github.com/jbinfo/scrapy-mongodb-queue 来自github $ git clone ...
学习Python的爬虫框架Scrapy,框架函数讲解,非常详细,零基础入门
粗糙分布Scrapy-Distributed是一系列组件,可让您轻松地基于Scrapy开发分布式爬虫。 现在! Scrapy-Distributed支持RabbitMQ Scheduler , Kafka Scheduler和RedisBloom DupeFilter 。 您可以非常轻松地在Scrapy的...
主要介绍了Centos7 Python3下安装scrapy的详细步骤,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
在python爬虫中:requests + selenium 可以解决目前90%的爬虫需求,难道scrapy 是解决剩下的10%的吗?显然不是。scrapy框架是为了让我们的爬虫更强大、更高效。接下来我们一起学习一下它吧。
安装Scrapy需要的库
标签: Scrapy
将site-packages解压,并将文件夹里面的所有34个字子文件放在Python或pandas的..Lib\site-packages文件夹里,如:\ProgramData\Python37\Lib\site-packages 即可正常安装Scrapy
Scrapy是什么? Scrapy是一个功能强大并且非常快速的网络爬虫框架,是非常优秀的python第三方库,也是基于python实现网络爬虫的重要的技术路线。 Scrapy的安装: 直接在命令提示符窗口执行pip install scrapy貌似...
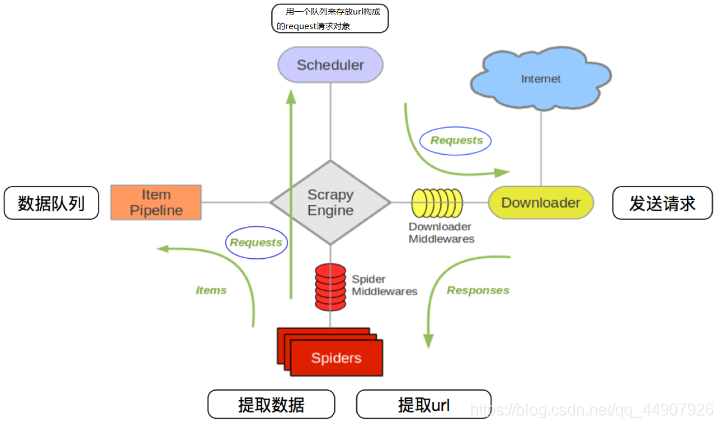
关于 这是Scrapy下载器中间件,用于将响应HTML存储到磁盘。用法打开下载器,例如在settings.py中指定它: DOWNLOADER_MIDDLEWARES = { 'scrapy_html_storage.HtmlStorageMiddleware': 10,}默认情况下,任何响应都...
大家可以在Github上clone...在开始爬取之前,必须创建一个新的Scrapy项目。 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMeiziTu 该命令将会创建包含下列内容的 tutorial 目录: CrawlMeiziTu/
scrapy 爬取酷狗T500音乐,并把音乐下载到本地,其中下载的音乐信息保存到mongoDB
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了网络抓取所设计的, 也可以应用在获取API所返回的数据或者通用...
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一、Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,...
Scrapy:一个快速高级的网站截图和网页采集框架 Scrapy 概述 Scrapy 是一个快速的高级网页抓取和网页抓取框架,用于抓取网站并从其页面中提取结构化数据。 它可用于广泛的用途,从数据挖掘到监控和自动化测试。 ...
主要介绍了Python爬虫实例——scrapy框架爬取拉勾网招聘信息的相关资料,文中讲解非常细致,代码帮助大家更好的理解和学习,感兴趣的朋友可以了解下
分别使用scrapy和request进行异步数据爬取
Scrapy爬虫框架 笔趣阁小说抓取 知识点:Scrapy爬虫框架使用 Scrapy爬虫框架使用 scrapy爬虫开发的基本步骤 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目 明确目标 (编写items.py):明确你想要抓取...
推荐文章
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地
- Python 攻克移动开发失败!_beeware-程序员宅基地
- Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
- 元素三大等待-程序员宅基地
- Java软件工程师职位分析_java岗位分析-程序员宅基地
- Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
- 标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地