
”scrapy“ 的搜索结果
Python,使用Scrapy爬取Boss直聘数据。 资源讲解地址:https://www.cnblogs.com/swarmbees/p/10011898.html
本资源提供了一套基于Python的Scrapy爬虫框架与Scrapy-Redis分布式爬虫的设计源码,包含61个文件,其中包括51个Python源代码文件,7个配置文件,以及1个Git忽略文件。此外,还包括1个文本文件和1个Markdown文档。...
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架。这篇文章主要介绍了Python安装scrapy的正确姿势,非常不错,具有一定的参考借鉴价值,需要的朋友可以参考下
scrapy startproject Stocks创建工程 cd Stocks/ scrapy genspider stocks qq.com创建爬虫 东方财富网 + 腾讯证券 stocks.py # -*- coding: utf-8 -*- import scrapy import re class StocksSpider(scrapy.Spider): ...
今天小编就为大家分享一篇利用Anaconda简单安装scrapy框架的方法,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
scrapy startproject dongguang 设置items.py文件 # -*- coding: utf-8 -*- import scrapy class NewdongguanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # pass...
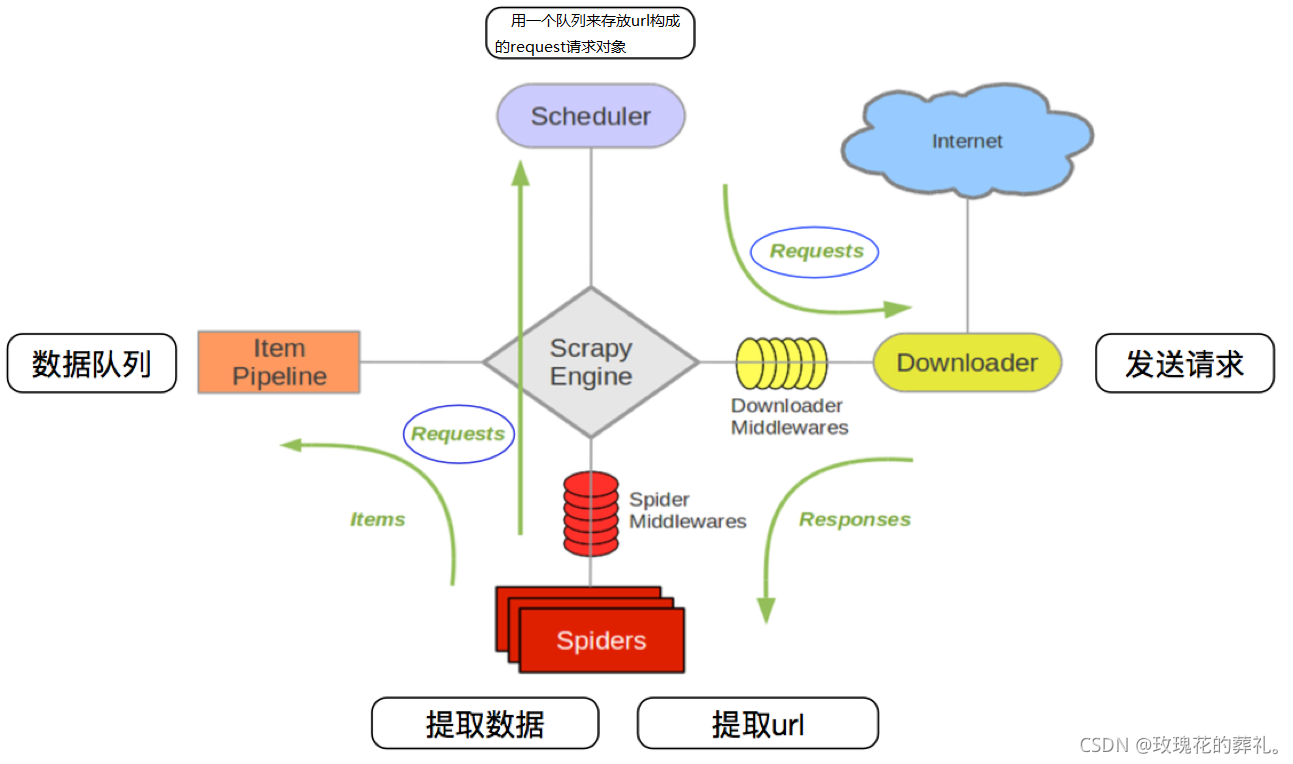
Scrapy 爬虫框架 1. 概述 Scrapy是一个可以爬取网站数据,为了提取结构性数据而编写的开源框架。Scrapy的用途非常广泛,不仅可以应用到网络爬虫中,还可以用于数据挖掘、数据监测以及自动化测试等。Scrapy是基于...
今天小编就为大家分享一篇解决Mac安装scrapy失败的问题,具有很好的参考价值,希望对大家有所帮助。一起跟随小编过来看看吧
基于Python的scrapy爬虫框架实现爬取招聘网站的信息到数据库
主要介绍了Python爬虫框架scrapy实现的文件下载功能,结合实例形式分析了scrapy框架进行文件下载的具体操作步骤与相关实现技巧,需要的朋友可以参考下
我是在win1064位系统,python2和python3共存的情况下安装的Scrapy,内附安装文本说明
主要介绍了pycharm创建scrapy项目教程及遇到的坑解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
主要介绍了python爬虫框架scrapy实现模拟登录操作,结合实例形式分析了scrapy框架实现模拟登陆操作的步骤、相关实现技巧与注意事项,需要的朋友可以参考下
我们通过以上学习,仅编写了2行代码,就完成了爬取数据的工作。
主要介绍了Python爬虫框架Scrapy实例代码,需要的朋友可以参考下
基于Scrapy的爬虫解决方案.docx
scrapy_project.zip
Scrapy的依赖包
/usr/bin/env python# -*- coding: utf-8 -*- from scrapy.contrib.spiders import CrawlSpider, Rulefrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom scrapy.selector import Selector ...
新建项目(命令行:scrapy startproject xxx):新建一个爬虫项目 明确目标(编写items.py):明确你想要抓取的目标 制作爬虫(spiders/xxspider.py):制作爬虫开始爬取网页 存储内容(pipelines.py):设计管道...
为scrapy图片异步下载,通过重写scrapy自带的imagepipeline的方法,并对下载的图片进行分类管理(分文件夹管理) 爬取链接为:汽车之家
主要介绍了使用scrapy发送post请求的坑,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看看吧
用于学习抓取普通数据语言Python 架框Scrapy参考文档,文档为参考,在现实开发中要根据具体情况而定。
scrapy练手实战项目,由简入深,适合入门练习。尤其是刚刚入门scrapy的,了解python基本语法的。项目涉及到许多知识点,一层一层慢慢深入。代码有详细注释。
从零开始学Scrapy网络爬虫配套教学PPT.rar
roll_news_scrapy使用scrapy抓取搜狐滚动新闻,保存到mongodb。##runscrapy crawl sohu_roll3
python爬虫基础学习,从基础学习,涉及到scrapy,Mongo,scrapy_redis等相关的基础知识
基于scrapy框架的爬虫代码,示例包括一些网站二级爬虫。
推荐文章
- c语言链表查找成绩不及格,【查找链表面试题】面试问题:C语言学生成绩… - 看准网...-程序员宅基地
- 计算机网络:20 网络应用需求_应用对网络需求-程序员宅基地
- BEVFusion论文解读-程序员宅基地
- multisim怎么设置晶体管rbe_山东大学 模电实验 实验一:单极放大器 - 图文 --程序员宅基地
- 华为OD机试真题-灰度图恢复-2023年OD统一考试(C卷)-程序员宅基地
- 【机器学习】(周志华--西瓜书) 真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)_真正例率和假正例率,查准率,查全率,概念,区别,联系-程序员宅基地
- Python Django 版本对应表以及Mysql对应版本_django版本和mysql对应关系-程序员宅基地
- Maven的pom.xml文件结构之基本配置packaging和多模块聚合结构_pom <packaging>-程序员宅基地
- Composer 原理(二) -- 小丑_composer repositories-程序员宅基地
- W5500+F4官网TCPClient代码出现IP读取有问题,乱码问题_w5500 ping 网络助手 乱码 send(sock_tcps,tcp_server_buff,-程序员宅基地