”spark“ 的搜索结果
Hive 是将 SQL 转为 MapReduce。SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行在学习Spark SQL前,需要了解数据分类。



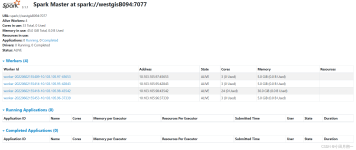
spark任务运行后,会将Driver所在机器绑定到4040端口,提供当前任务的监控页面。 此端口号默认为4040,展示信息如下: 调度器阶段和任务列表 RDD大小和内存使用情况 环境信息 正在运行的executors的信息 ...
一 Spark概述 1 11 什么是Spark 2 Spark特点 3 Spark的用户和用途 二 Spark集群安装 1 集群角色 2 机器准备 3 下载Spark安装包 4 配置SparkStandalone 5 配置Job History ServerStandalone 6 ...
park为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
以Spark core为核心,提供了Spark SQL、Spark Streaming、MLlib几大功能组件 中文文档:https://spark.apachecn.org/#/ github地址:https://github.com/apache/spark Spark Core Spark提供了多种资源调度框架,基于...
1.spark是一门大规模数据处理的同一分析引擎. 2.Spark可以对任意类型的数据进行自定义计算,结构化,半结构化,非结构化的数据都可以进行处理. 3. Hadoop Spark 基础平台, 包含计算, 存储, 调度 纯计算工具...


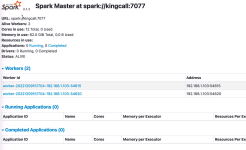
该文章主要是描述单机版Spark的简单安装,版本为 spark-3.1.3-bin-hadoop3.2.tgz 1、Spark 下载、解压、安装 Spark官方网站: Apache Spark™ - Unified Engine for large-scale data analytics Spark下载地址:...

Spark自带example
标签: spark

IDEA 本地运行Spark
标签: spark
Spark系列之Spark启动与基础使用

2.关闭spark 进入以下目录:/usr/local/softwares/spark-2.3.2-bin-hadoop2.7/sbin 执行以下命令,关闭spark: ./stop-all.sh 3.关闭hadoop 进入以下目录:/usr/local/softwares/hadoop-2.7.2/sbin 执行以下...
spark重要参数配置

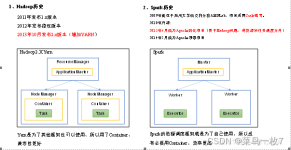
sparkcore sparksql sparkstreaming structedstreming
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache的顶级项目,2014年5月发布spark1.0,2016年7月发布spark...



推荐文章
- 广度优先搜索_广搜再搜一遍行吗-程序员宅基地
- k8s 学习笔记 - LimitRange 限制范围-程序员宅基地
- 基于SpringBoot的计算机学院校友网的设计与实现_基于springboot / ssm的校友录网站设计与实现-程序员宅基地
- 序列图在widget中播放+PaperFlipbook的使用+将多个图片放到数组变量中_ue5niagara播放图片序列-程序员宅基地
- 蓄水池抽样-程序员宅基地
- OSDI, SOSP与美国著名计算机系的调查(2008)_sosp发文统计-程序员宅基地
- android studio 模拟器 简书,Android Studio | 配置模拟器AVD存放路-程序员宅基地
- CWE/SANS Top 25 Most Dangerous Programming Error-程序员宅基地
- hive分区分桶操作及加载数据_hive 分桶表正确加载数据的方法-程序员宅基地
- freeRtOS的基本概念和使用方法,以及入门方法_feerrtos-程序员宅基地