全文检索 -- Elasticsearch -- 为 Elasticsearch 安装并测试 IK 中文分词器(用指定分词器创建 index 索引库,并通过命令和postman工具测试分词器)
”中文分词器“ 的搜索结果
word分词器java源码
Solr7.5.0配置中文分词器IKAnalyzer-附件资源
中文分词器按照中文进行分词,中文应用最广泛的是ik分词器。


solr5的ik中文分词器源码,解压后需要自己打包成jar包
solr中文分词器技术
标签: solr
中文分词技术(中文分词原理)词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的...
1. 安装插件 1.1 安装插件 拼音分词器:...中文分词器:https://github.com/medcl/elasticsearch-analysis-ik 找到自己对应的自己的Elasticsearch版本的插件进行安装 Elasticsearch 7.5.1 elastic...
es中文分词器安装包
标签: es_IK
在搜索引擎领域,比较成熟和流行的,就是ik分词器,其实我们用来进行搜索的,绝大多数,都是中文应用,很少做英文的 standard:没有办法对中文进行合理分词的,只是将每个中文字符一个一个的切割开来,其实搜索的...
通过对基于最大匹配算法的中文分词器的设计与改进,并引入文本解析器与构建同义词词库引擎,使得Lucene对中文的检索更加个性化。通过检索结果的对比表明,改进后的中文分词器对检索功能的扩展有了极大的提高。并最终...
针对Lucene自带中文分词器分词效果差的缺点,在分析现有分词词典机制的基础上,设计了基于全哈希整词二分算法的分词器,并集成到Lucene中,算法通过对整词进行哈希,减少词条匹配次数,提高分词效率。该分词器词典...
es中文分词器ikes中文分词器ikes中文分词器ikes中文分词器ikes中文分词器ik
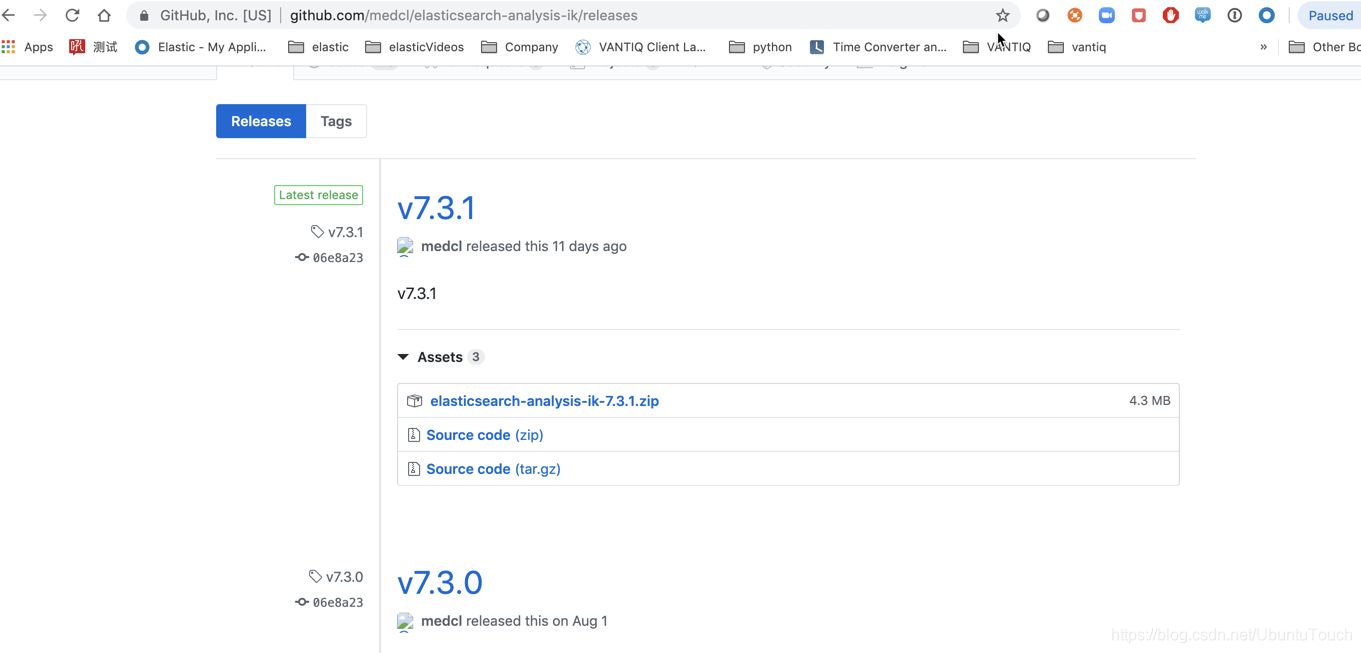
ES安装中文分词器(版本6.2.2) 首先下载zip格式的压缩包 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.2/elasticsearch-analysis-ik-6.2.2.zip 将下载完成的zip文件放入es文件目录...
java单独整合ikanalyzer中文分词器提取关键字及动态拓展词库并兼容lucene高版本
ansj中文分词器源码
标签: ansj_seg
分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上目前实现了.中文分词. 中文姓名识别 . 用户自定义词典,关键字提取,自动摘要,关键字标记等功能
非常好的中文分词器,基于lucene,很好用!

IKAnalyzer 2012FF_hf1 中文分词器 IKAnalyzer 2012FF_hf1 中文分词器
Ikik-analyzer-solr-6.3.0 中文分词器6.3.0版本和相关配置文件
{ "name" : "1vFT9YZ", "cluster_name" : "elasticsearch_gwz", "cluster_uuid" : "lxBMLC2DRpKOYoGBHDCpwQ", "version" : { "number" : "6.8.1", "build_flavor" : "oss", "build_type" : "ta...
elasticsearch作为一个分布式弹性存储与检索系统,默认是不支持中文分词的,但是呢,这个工作有人做,估计都是中国人做的吧。 什么是中文分词呢,简单来说,就是将我们的中文句子或者短语拆分成一个一个的可以被...


副本技能-ES安装中文分词器
标签: es
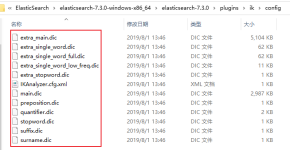
注意:分词器版本和ES版本要保持一致 1.下载分词器放到ES目录下 ...# 中文分词器,IK分词器 GET /_analyze { "text":"中华人民共和国国徽", "analyzer":"ik_smart" } 下图结果标识IK分词器成功 4.配置自定
ik中文分词器,solr5版本的分词器,使用教程百度有,这个是源码版
适应传统中文分词器对微博文本进行分词:基于规则和基于统计的方法相结合
https://github.com/medcl/elasticsearch-analysis-ik elasticsearch 中文分词器
推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地