当emule中开始使用Kademlia网络后,便不再会有中心服务器失效这样的问题了,因为在这个网络中,没有中心服务器,或者说,所有的用户都是服务器,所有的用户也是客户端,从而完完全全得实现了P2P。...
”散列表“ 的搜索结果
(1)初始化散列表; (2)向散列表中插入一个元素; (3)从散列表中删除一个元素; (4)从散列表中查找一个元素。 #include <bits/stdc++.h> #define ElemType int #define HashSize 12 #define p 11 ...
一)散列表(哈希表) 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列...
散列在数据结构算法中占据独特而重要地位。此类方法以最基本的向量作为底层支撑结构,通过适当的散列函,在词条的关键码与向量单元的秩之间建立起映射关系,理论分析和实验统计均表明,只要散列散列函数以及冲突排解...
散列思想:散列表用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。 可以说,如果没有数组,就没有散列表。 散列函数:顾名思义,它是一个函数。我们可以把它定义成...
#include <stdio.h> #include <malloc.h> #include "stdlib.h" #include <math.h> typedef int Status; typedef int KEYTYPE; typedef struct { KEYTYPE key; ......
本博文源于浙江大学《数据结构》。散列(Hashing)是一种重要的查找方法。它的基本思想是:以数据对象的关键字key为自变量,通过一个确定的函数关系h,计算出对应的函数值h(key),把这个值解释为数据对象的存储地址,...

写在前面: 博主是一名大数据的初学者,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新...
散列表线性开型寻址 问题描述 给定散列函数的除数D和操作数m,输出每次操作后的状态。 有以下三种操作: 插入x,若散列表已存在x,输出“Existed”,否则插入x到散列表中,输出所在的下标。 查询x,若散列表...
散列表成功的平均查找长度和查找失败的平均长度: 关于成功的平均查找长度:查找成功的key在于散列表中一定会有关键值,可以直接通过一次散列函数找到的则是一次查找,否则根据线性散列探测去计算 关于失败的平均...


请写出在散列表中插入关键字为k的一个记录的算法,设散列函数为H,H(key)=key%13,解决冲突的方法为链地址法。 输入 多组数据,每组三行,第一行为待输入的关键字的个数n,第二行为对应的n个关键字,第三行为需要...
若开始通过哈希函数定位到下标为2的位置,将30与k比较,不相等(比较一次)说明这个位置查找失败,继续下一个紧邻的下标为3的位置......直到比较到下标为8的位置为空,至此查找失败,这种情况一共比较了7次.........
主要介绍了Ruby中的数组和散列表的使用详解,是Ruby入门学习中的基础知识,需要的朋友可以参考下
散列表(线性探测法&二次探测法)
标签: 数据结构
将关键字序列(7、8、30、11、18、9、14)散列存储到散列表中 (7) Key 7 8 30 11 18 9 14 H(Key) 0 3 6 5 5 5 6 冲突处理:(位置被占有继续往下找) 地址 0 1 2 3 4 5 6 7 8 9 关键字 7 14 8 ...
设计散列表实现电话号码查找系统。 2.基本要求: (1)设每个记录有下列数据项:电话号码、用户名、地址; (2)从键盘输入各记录,分别以电话号码和用户名为关键字建立散列表; (3)采用一定的方法解决冲突; (4)...

文章目录哈希函数哈希函数的构造方法处理散列冲突的方法散列表性能分析散列表C++代码实现 哈希函数 哈希函数就是 关键字Key 到 值Value 的映射: Value = f(Key) Value反映的是关键字Key的存储地址。 哈希函数的...
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度 。这个映射函数叫做散列函数,存放记录的数组...
1、散列表 看过HashMap源码的同学应该知道,HashMap是基于哈希表(散列表)的 Map 接口的非同步实现。 在我们put了一条key-value数据后,如下图,程序会先将key通过hash(key)这个函数转化成整形,这个整形做为数组...
对给定的关键字key,用一个函数H(key)计算出元素地址,由此而得散列表(Hash表,哈希表),其中函数H(key)称为散列函数 此函数值称为散列地址。 然而,在实际应用中,会出现这样的情况: k1≠k2,但H(k1)=H(k2) ...

前面介绍的查找是建立在比较的基础上,查找效率由比较次数决定,不仅与被查数据整体的存储结构有关,还与逻辑上可被查找的数据集合所含的数据个数有关,同时与待查记录在查找表中位置以及查找策略如查找方向有关。...
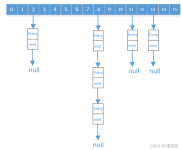
散列表类的C++实现(探测散列表)...
一、散列表 1.基本概念 线性表和树表的查找中,记录在表中的位置与记录的关键字之间不存在确定的关系,因此,在这些表中查找记录时需要一些关键字比较。这类查找建立在“比较”的基础上,查找的效率取决于比较的...
推荐文章
- 航空航天数值分析matlab算法,数值分析 matlab-程序员宅基地
- Zookeeper权限管理与Quota管理_zookeeper ip 和quota ip-程序员宅基地
- ocr数据集:图片数据集_ocr 图片集-程序员宅基地
- python识图自动化_聊聊 Python 自动化截图的一些经验-程序员宅基地
- python语言的关键字是什么_Python语言的关键字有哪些特点?关键字列举-程序员宅基地
- pandas数据处理之groupby的常用用法_pandas怎么处理groupby的结果-程序员宅基地
- 第一次参赛获Java B组国二,给蓝桥杯Beginners的6700字保姆级经验分享。_蓝桥杯java组经验贴-程序员宅基地
- 二叉链表——构建与输出_构建一个用二叉链表存储一个公司组织机构的相关数据的程序,假设该公司的下属-程序员宅基地
- 详解支持向量机(SVM)算法与代码实现_3. 软间隔和核svm分别实现一个识别task。代码-程序员宅基地
- C#使用TreeView控件实现的二叉树泛型节点类 BinaryTreeNode<T>泛型二叉树类BinaryTree<T>及其方法_c# treeview 树状节点-程序员宅基地