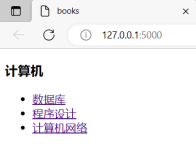
爬虫利器BeautifulSoup爬取一个页面的所有URL,可以简单分为三个步骤: 使用requests获取页面内容 使用BeautifulSoup进行页面内容解析 提取并整理所需要的URL 代码实例 # 导入BeautifulSoup和...
”爬取链接“ 的搜索结果
利用爬虫爬取网页连接
标签: 爬虫
1 问题如何利用爬虫技术定向爬取网页连接?2 方法利用爬虫技术,通过实验、实践等证明提出的方法是有效的,是能够解决开头提出的问题。代码清单 1import requestsimport reheaders = {'User-Agent':'Mozilla/5.0 ...
文学网站排行榜链接-方便爬取书名
标签: 爬取链接
每个大网站的各个排行榜的链接

from lxml import html import requests from pyquery import PyQuery as pq from urllib.parse import urljoin import time from threading import Thread # 获取全部页的网址 def all_url(url): page = 1 ...
主要介绍了python实现的爬取电影下载链接功能,涉及Python基于BeautifulSoup模块的网页信息爬取相关操作技巧,需要的朋友可以参考下
今天给大家分享一个Python基本代码爬取超链接文字及超链接,及一一对应存放到本地文件夹TXT文件中,这里因为我是一个Python初学者,所以所写的代码非常简单,对大家而言也是非常容易理解的。这里我以我的博客为例写...
以下代码是在python3.6环境下测试通过 #!/usr/bin/python # -*- coding:utf-8 -*- ... from scrapy.spiders import Spider ...from scrapy.selector import Selector ...from storage.items import W3S...
作为一个安全测试人员,面对一个大型网站的时候,手工测试很有可能测试不全,这时候就非常需要一个通用型的网站扫描器。当然能直接扫出漏洞的...当我们把整站url都爬取出来之后,可以对url进行分析分类,然后有针...
如何获取一个页面内所有URL链接?在Python中可以使用urllib对网页进行爬取,然后利用Beautiful Soup对爬取的页面进行解析,提取出所有的URL。 什么是Beautiful Soup? Beautiful Soup提供一些简单的、python式的函数...
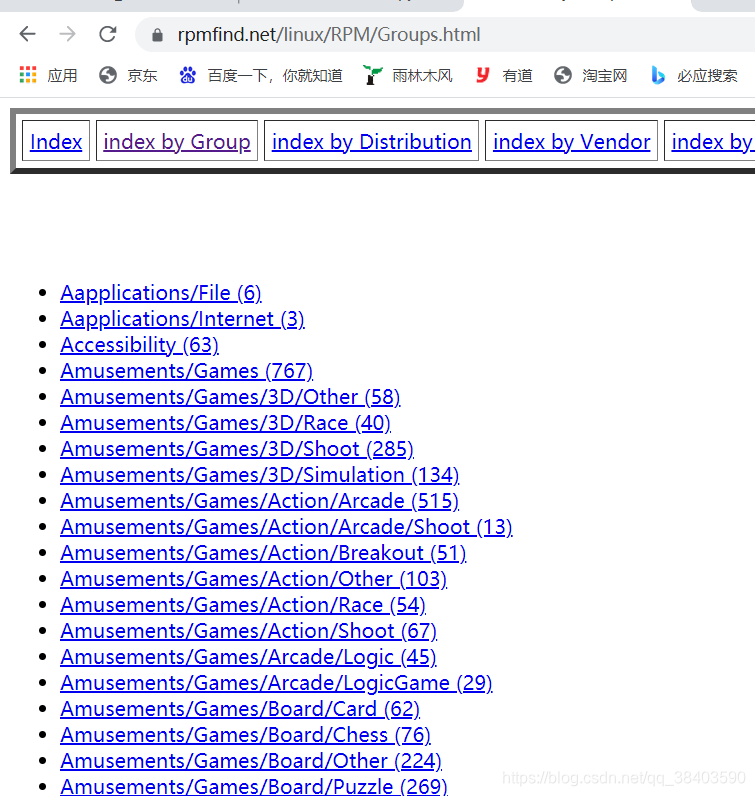
翻页爬取网页所有链接以及对应内容(爬取静态网页未使用框架) 爬取步骤 1.对每一页发送请求 2.获取每一页中的链接地址 3.对链接的内容设置提取规则并爬取 4.储存所有数据为CSV文件 前置步骤 #coding=utf-8 import ...
from urllib.request import urlopen from bs4 import BeautifulSoup import re pages = set() def getLinks(pageUrl): global pages html = urlopen("...+pageUrl) bsObj = BeautifulSoup...
御剑自带了字典,主要是分析字典中的网址是否存在,但是可能会漏掉一些关键的网址,于是前几天用python写了一个爬取网站全部链接的爬虫。实现方法主要的实现方法是循环,具体步骤看下图:贴上代码:# author: saucer...
爬取url链接标题小工具
标签: 音视频
爬取url链接标题小工具
主要实现的是批量下载安卓APP。显然用手点是不科学的。于是尝试用Python写了一个半...所谓半自动化,就是把下载链接批量抓取下来,然后一起贴到迅雷里进行下载,这样可以快速批量下载。有需要的朋友们可以一起看看吧。
python使用request包爬取网页数据、使用BeautifulSoup解析爬取的数据获取文字和链接地址列表
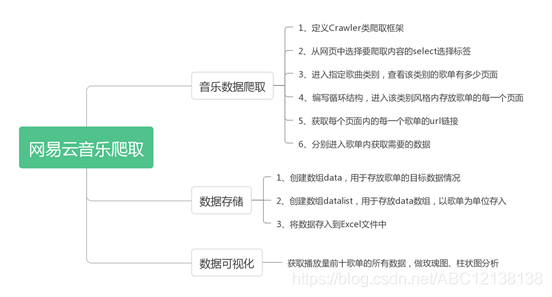
循环爬取网页链接 基本原理: 爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。 基本过程图: 重点:从访问的...
爬取网站实训图片的链接利用一个起始网址进行链接搜索,抓取链接中所有的图片,按照预先设置的图片类型进行下载到本地存储,附带界面,简单是c++代码,编译无特殊需求
本文环境是python3,采用的是urllib,BeautifulSoup搭建。 说下思路,这个项目分为管理器,url...各司其职,在管理器进行调度。...当然也可以保存在文件。最后效果如图。 ...代码如下。... self.urls = url_manager.UrlManager() ...
检查网页无效链接 前言 自动化技术可以帮助我们做自动化测试,同样也可以帮助我们完成别的事情,比如今天我们要做的检查网站404无效链接。 原理 实现这样的功能,大致分为以下步骤: 1.打开官网首页,获取页面上...
爬虫文件,此Java文件可以爬取网页中所有的链接网址。
在上一篇文章中,我们对PPT网站的模板进行了爬取,该网站中,每个模板的详情网页直接包含目标资源的链接,因此只需遍历列表中的模板,依次提取链接即可,是一种十分简单的爬虫程序。对于某些稍微复杂些的网页,他们...
爬取网站实训图片的链接利用一个起始网址进行链接搜索,抓取链接中所有的图片,按照预先设置的图片类型进行下载到本地存储,附带界面,简单是c++代码,编译无特殊需求.zip
java1234网站中爬取的公开可达的网盘链接(有提取码)java1234网站中爬取的公开可达的网盘链接(有提取码)java1234网站中爬取的公开可达的网盘链接(有提取码)java1234网站中爬取的公开可达的网盘链接(有提取码)...
https://blog.csdn.net/One_Ok_Clock/article/details/89189151?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.add_param_isCf
推荐文章
- com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known serve-程序员宅基地
- PAT乙级练习题1010 一元多项式求导_pat 乙级 1010-程序员宅基地
- You can also run `php --ini` inside terminal to see which files are used by PH P in CLI mode_you can also run `php --ini` in a terminal to see -程序员宅基地
- 对UDP校验和的理解_udp 数据包 校验和 checksum=0-程序员宅基地
- 递归遍历文件夹,以c:/windows为例-程序员宅基地
- git 本地与远程的链接_git如何本地和网页链接-程序员宅基地
- ArrayList与HashMap遍历删除元素,HashMap与ArrayList的clone体修改之间影响_在arraylist和hashmap遍历的同时删除元素,可能会导致一些问题发生-程序员宅基地
- Chapter2-软件构造过程和生命周期_iterative and agile systems development lifecycle -程序员宅基地
- 4.6 浮动定位方式float_c语言中float的左右浮动属性示例-程序员宅基地
- OSS上传【下载乱码问题】_阿里云oss文件名乱码-程序员宅基地