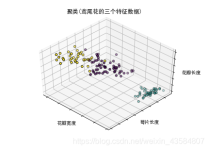
”聚类“ 的搜索结果
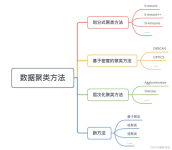
聚类分析一、聚类的关键:距离二、K-means聚类算法三、聚类的注意事项聚类好坏的评估方法1、技术上的方法2、业务上的方法连续型数据标准化分类型数据标准化 一、聚类的关键:距离 二、K-means聚类算法 三、聚类的...
(一)何谓聚类 还是那句“物以类聚、人以群分”,如果预先知道人群的标签(如文艺、普通、2B),那么根据监督学习的分类算法可将一个人明确的划分到某一类;如果预先不知道人群的标签,那就只有根据人的特征(如...
公众号:尤而小屋作者:Peter编辑:Peter本文主要介绍8个常见聚类算法和基本原理:K-Means聚类层次聚类DBSCAN聚类均值漂移聚类谱聚类模糊聚类Fuzzy Clustering密度峰值聚类Density Peaks Clustering结合GMM和EM的...
聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到...
Kmeans聚类可以支持2D和3D数据的处理,可以清晰观测聚类中心的移动过程,可以自选K的大小。

1. 层次聚类 1.1 层次聚类的原理及分类 1)层次法(Hierarchicalmethods):先计算样本之间的距离。每次将距离最近的点合并到同一个类。然后,再计算类与类之间的距离,将距离最近的类合并为一个大类。不停的合并...
MYDBSCAN:基于密度的聚类DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法的底层实现 MYAP:基于划分的聚类AP(Affinity Propagation Clustering Algorithm )算法的底层实现--近邻传播...
代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络的聚类系数算法代码代码 复杂网络...
利用MATLAB做模糊聚类,并且画出系谱图
本文件为常见聚类算法测试数据集 ,UCI上常用的聚类算法数据集
经典层次聚类算法DIANA,MATLAB编程,简单易懂,可以运行
在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。本文提出了一种能够...
python 文本聚类分析案例说明摘要1、结巴分词2、去除停用词3、生成tfidf矩阵4、K-means聚类5、获取主题词 / 主题词团 说明 实验要求:对若干条文本进行聚类分析,最终得到几个主题词团。 实验思路:将数据进行预处理...
聚类分析,基于kmeans聚类分析并输出收敛图,matlab2021a仿真,输出聚类点,聚类收敛图。
聚类分析,kmeans聚类分析,输出聚类坐标点。matlab2021a测试仿真。
基本的层次聚类算法matlab实现 简单明了 是我以前上课时记下的笔记内容 代码在15b上实验证实可用
K-means 对 iris 数据进行聚类并显示聚类中心,聚类结果等,附注释
该程序利用OpenCV中的K均值聚类函数Kmeans2对图像进行颜色聚类,达到分割的目的。 编写此函数的目的是:Kmeans2函数的用法有些难掌握,参考资料少,尤其是对图像进行操作的例子少,我找了很久也找不到, 找到的例子也...
birch,Kmeans,Kmeans++,KNN四种聚类算法对同一个二维坐标数据集进行聚类分析,python代码
ap聚类算法实现三维数据点的分类,demo为案例
邓氏关联度计算matlab代码,可用于数据关联度分析
一次手写作业,手写三种聚类算法,包含数据集和代码
gg聚类算法,标准的matlab实现,加入数据就可以直接用的
演化聚类算法(ECM) 是一种有效的在线聚类算法, 能够根据输入数据实时调整聚类. 但是, 该聚类算法依赖于预先设置的最大距离阈值, 而且对数据输入次序敏感. 针对这些问题, 提出一种基于自适应学习的演化算法(SALECM), ...
资料说明:包括数据+代码+文档+代码讲解。 1.项目背景 2.数据获取 3.数据预处理 4.探索性数据分析 5.特征工程 6.构建聚类模型 7.结论与展望
Python密度聚类 最近在Science上的一篇基于密度的...与基于距离的聚类算法不同的是,基于距离的聚类算法的聚类结果是球状的簇,而基于密度的聚类算法可以发现任意形状的聚类,这对于带有噪音点的数据起着重要的作用。
推荐文章
- Python 可视化库-程序员宅基地
- python自动化测试 | 接口自动化测试脚本如何写好?_测试自动化脚本怎么写-程序员宅基地
- cdh oozie 无法启动问题Could not load service classes, Cannot create PoolableConnectionFactory_e0103: could not load service classes, cannot crea-程序员宅基地
- Federated Machine Learning学习笔记(一):综述:概念与模型-程序员宅基地
- 如何在CentOS上将salt-minion部署到python2虚拟环境_venv-salt-minion-程序员宅基地
- android webview拍照,让 Android 的 WebView 支持 type 为 file 的 input,同时支持拍照-程序员宅基地
- 深度学习技巧应用7-K折交叉验证的实践操作_k折交叉验证应用在训练模型中-程序员宅基地
- 客户端连接WebSocket服务器时连接失败会出现的一些问题及解决方案-程序员宅基地
- 对于一个字符串,请设计一个高效算法,找到第一次重复出现的字符。 给定一个字符串(不一定全为字母)A及它的长度n。请返回第一个重复出现的字符。保证字符串中有重复字符,字符串的长度小于等于500。...-程序员宅基地
- SpringBoot中使用Validation所踩过的坑_javax.validation.constraints 缺点-程序员宅基地