
”西瓜书“ 的搜索结果

如何阅读西瓜书?
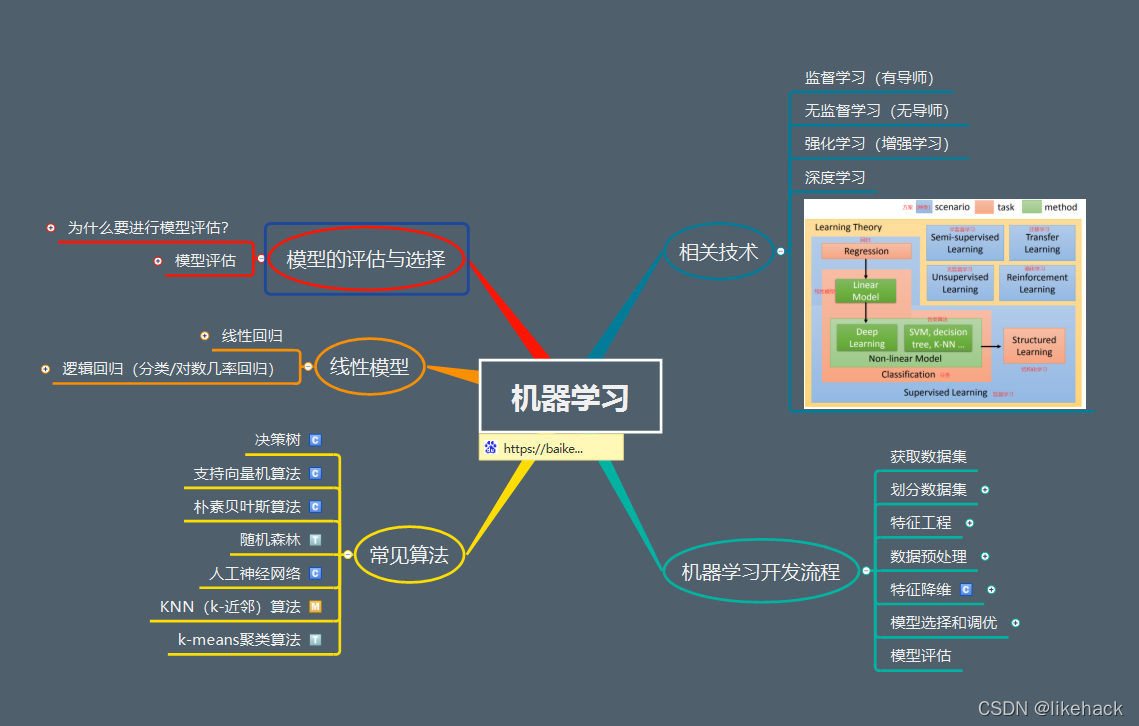
西瓜书第一章知识点总结
标签: 知识图谱
西瓜书第一章知识点总结
# -*- coding: utf-8 -*- # @FileName: DBSCAN ...西瓜书第九章聚类9.9 DBSCAN聚类算法 ''' import random import matplotlib.pyplot as plt import numpy as np import pandas as pd def CalDistance(X1,

西瓜书一二章,自己的总结还是可以的
机器学习西瓜书第二周学习笔记
标签: 机器学习
机器学习西瓜书第二周学习笔记


机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的...
周志华「机器学习」第二章习题解答



众所周知,人工智能是当前最热门的话题之一, 计算机技术与互联网技术的快速发展更是将对人工智能的研究推向一个新的高潮。 人工智能是研究模拟和扩展人类智能的理论与方法及其应用的一门新兴技术科学。...

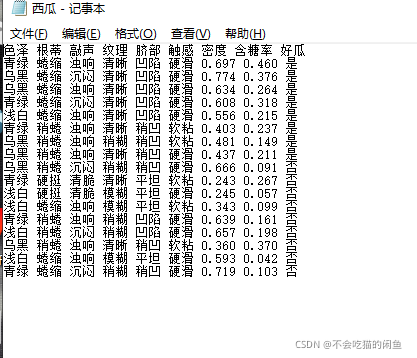
西瓜书,西瓜数据集3.0,西瓜数据集3.0α

10.降维 10.1.k近邻学习(kNN) k近邻(k-Nearest Neighbor,简称kNN)学习是一种常用的监督学习方法 其工作机制非常简单: *给定测试样本,基于某种距离度量找出训练集中与其最靠近的k个训练样本;...
1. 编码: 总共 个类别做 2. 解码: 2. 为空, 或者是 所有样本在所有属性上取值相同, 无法划分. 设定为该结点所含样 1. 调整 2. 代入 3.


采用Python实现各种机器学习算法,基于机器学习实战、西瓜书、统计学习方法等
这一章学起来较为简单,也比较好理解。

西瓜书机器学习第一章至第九章课后练习作业
推荐文章
- 大数据和云计算哪个更简单,易学,前景比较好?_大数据和云计算哪个好-程序员宅基地
- python操作剪贴板错误提示:pywintypes.error: (1418, 'GetClipboardData',线程没有打开的剪贴板)...-程序员宅基地
- IOS知识点大集合_ios /xmlib.framework/headers/xmmanager.h:66:32: ex-程序员宅基地
- Android Studio —— 界面切换_android studio 左右滑动切换页面-程序员宅基地
- 数据结构(3):java使用数组模拟堆栈-程序员宅基地
- Understand_6.5.1175::New Project Wizard_understand 6.5.1176-程序员宅基地
- 从零开始带你成为MySQL实战优化高手学习笔记(二) Innodb中Buffer Pool的相关知识_mysql_global_status_innodb_buffer_pool_reads-程序员宅基地
- 美化上传文件框(上传图片框)_文件上传框很丑-程序员宅基地
- js简单表格操作_"var str = '<table border=\"5px\"><tr><td>序号</td><-程序员宅基地
- Power BI销售数据分析_powerbi汇总销售人员业绩包括无销售记录的人-程序员宅基地