周志华西瓜书《机器学习》习题提示——第2章
”西瓜书“ 的搜索结果
西瓜书习题2.5的证明
标签: 机器学习
关于西瓜书中AUC=1−lrankAUC=1-l_{rank}AUC=1−lrank的推导分析 在期末考试暂时告一段落之后,可以将前段时间学习《机器学习》时整理的一部分内容更新了. 在学习第二章...
把学习器实际预测输出与样本的真实输出之间的差异称为误差。学习器在训练集上的误差称为训练误差或经验误差;学习器在新样本上的误差称为泛化误差。
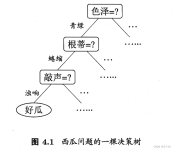
西瓜书 4.3 决策树
标签: 机器学习


机器学习 机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断...




""" 训练样本(Training sample data.txt) -0.017612 14.053064 0 -1.395634 4.662541 1 -0.752157 6.538620 0 -1.322371 7.152853 0 0.423363 11.054677 0 0.406704 7.067335 1 0.667394 12.741452 0 ...
机器学习西瓜书要点归纳——目录


logistic回归简介 logistic回归由Cox在1958年提出[1],它的名字虽然叫回归,但这是一种二分类算法,并且是一种线性模型。由于是线性模型,因此在预测时计算简单,在某些大规模分类问题,如广告点击率预估(CTR)上...

机器学习( 周志华 )书后题自己写的答案Matlab版(以后可能补上Python版),水平渣渣无奇QAQ,恳请大家多多指教!!
西瓜书第一章课后习题

对数几率回归是二分类的问题,我们可以将随机变量yyy假设服从伯努利分布,即yyy的取值只有{0,1}。 这里需要补充一个概念,指数族分布,伯努利分布就属于指数族分布。 (注:ϕ\phiϕ指的是yyy取1是的概率) ...
西瓜书学习心得
西瓜书学习指南

【西瓜书Chapter2】线性回归
标签: 算法


我们直接看西瓜书上的例子,其中{1,2,3,6,7,10,14,15,16,17}为训练集,{4,5,8,9,11,12,13}为验证集。 (1)在未划分前,根据训练集,类别标记为训练样例数最多的类别,由于训练集中的好瓜与坏瓜是相同多的类别,...
西瓜书89页数据集3.0a # -*- coding: utf-8 -*- import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn import model_selection from sklearn.linear_model import Lo...
概念 集成学习(ensemble learning)通过构建多个个体学习器并结合起来完成学习任务。 做一个简单分析,考虑二分类问题 ,假定基本分类器的错误率为,有 由基分类器相互独立,设X为T个基分类器分类正确的次数,因此 ...

推荐文章
- VC获取精确时间的方法_vc 通过线程和 sleep 获取精准时间-程序员宅基地
- wml入门-程序员宅基地
- 计算机考研怎么给老师发邮件,考研复试前,手把手教你怎么给导师发邮件!4点要注意...-程序员宅基地
- 美国计算机生物学大学,美国计算机大学排名-程序员宅基地
- 《动手学深度学习(PyTorch版)》笔记4.4_out = net(x) y = y.reshape(out.shape)-程序员宅基地
- Unity粒子特效系列-龙卷风预制体做好了,unitypackage包直接用!_unity螺旋风特效-程序员宅基地
- 计算机科学与技术的难度大小,计算机科学与技术专业各科难度排行-程序员宅基地
- 原生小程序 微信小程序 使用ucharts_微信小程序引入ucharts-程序员宅基地
- 1095:数1的个数 题解 信息学奥赛 NOIP_y1095 数1的个数-程序员宅基地
- 学习布局(15) 段落类的样式_段落元素设置样式-程序员宅基地