深度学习之目标检测(二)-- Faster R-CNN 理论_faster rcnn regression 非极大抑制-程序员宅基地
技术标签: python 计算机视觉 学习笔记 深度学习 人工智能 Deep Learning
深度学习之目标检测(二)-- Faster R-CNN 理论
深度学习之目标检测(二)Faster R-CNN理论
本章学习 Faster R-CNN理论相关知识,学习视频源于 Bilibili,感谢霹雳吧啦Wz,建议大家去看视频学习哦。
1. R-CNN (Region with CNN feature)
Faster-RCNN 是从 R-CNN 到 Fast R-CNN,再到的 Faster R-CNN。R-CNN 可以说是利用深度学习进行目标检测的开山之作。其原始论文:Rich feature hierarchies for accurate object detection and semantic segmentation。
R-CNN 算法流程分四个步骤:
- 一张图像生成1k~2k个候选区域(使用 Selective Search 方法)
- 对每个候选区域,使用深度网络(图片分类网络)提取特征
- 特征送入每一类SVM分类器,判断是否属于该类
- 使用回归器精细修正候选框位置。(使用 Selective Search 算法得到的候选框并不是框得那么准)

1.1 候选区域的生成
利用 Selective Search 算法通过图像分割的方法得到一些原始区域,然后利用一些合并策略将这些区域合并,得到一些层次化的区域结构,而这些结构就包含着可能需要的物体。这里的 SS 算法可以详见 此处,算法原始论文Selective Search for Object Recognition。(初始区域的获取是引用另一篇论文的:Efficient Graph-Based Image Segmentation)

1.2 对每个候选区域使用深度网络提取特征
将2000个候选区域缩放为 227 × 227 227 \times 227 227×227 pixel,接着将候选区域输入事先训练好的 AlexNet CNN 网络获取 4096 维的特征得到 2000 × 4096 2000 \times 4096 2000×4096 的特征矩阵。(将后面的全连接层去除就得到了特征提取网络)

1.3 特征送入每一类的SVM分类器,判定类别
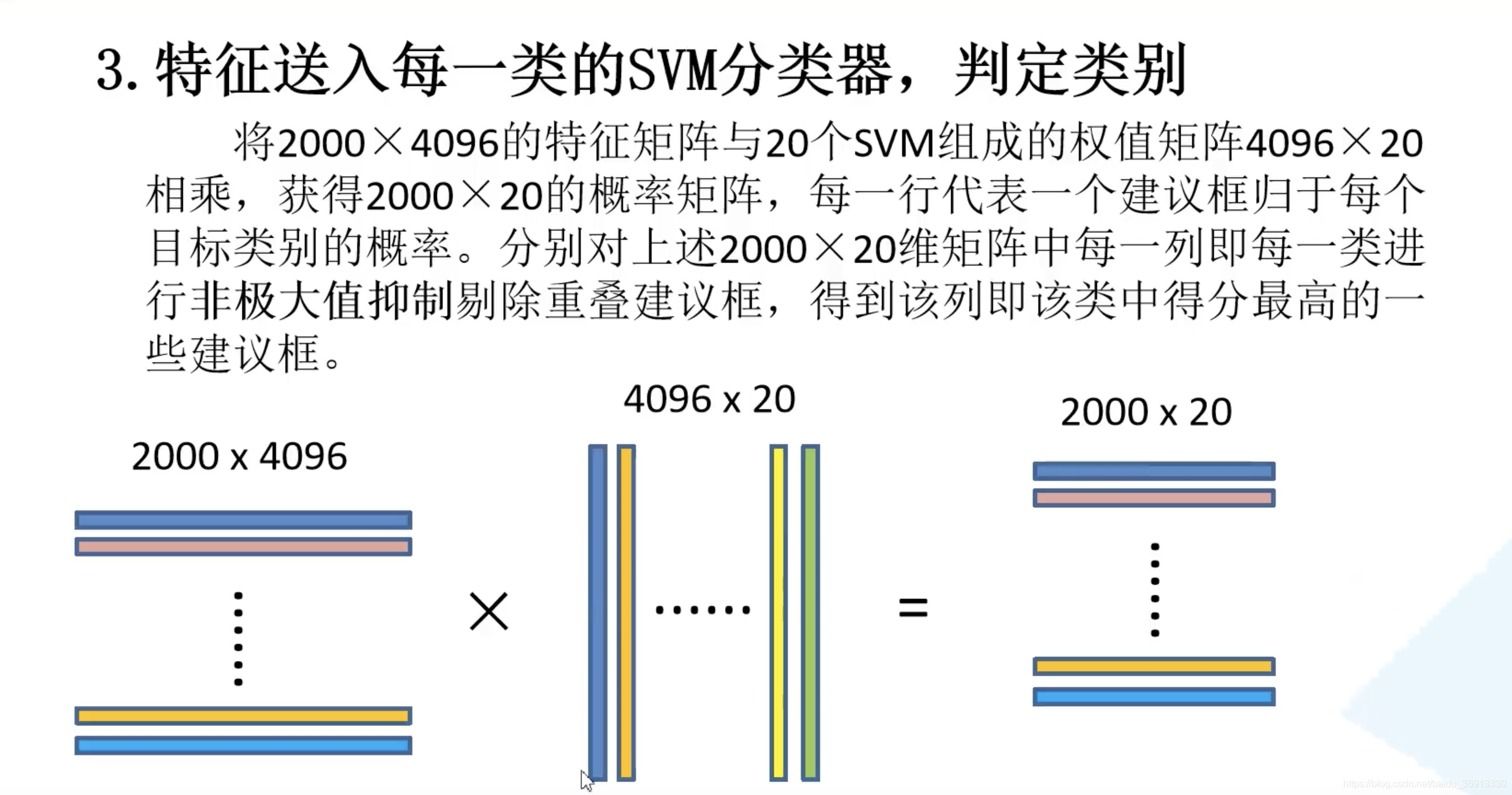
将得到 2000 × 4096 2000 \times 4096 2000×4096 维特征与20个SVM组成的权值矩阵 4096 × 20 4096 \times 20 4096×20 相乘,获得 2000 × 20 2000 \times 20 2000×20 维矩阵表示每个建议框是某个类别的得分。对上述 2000 × 20 2000 \times 20 2000×20 维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
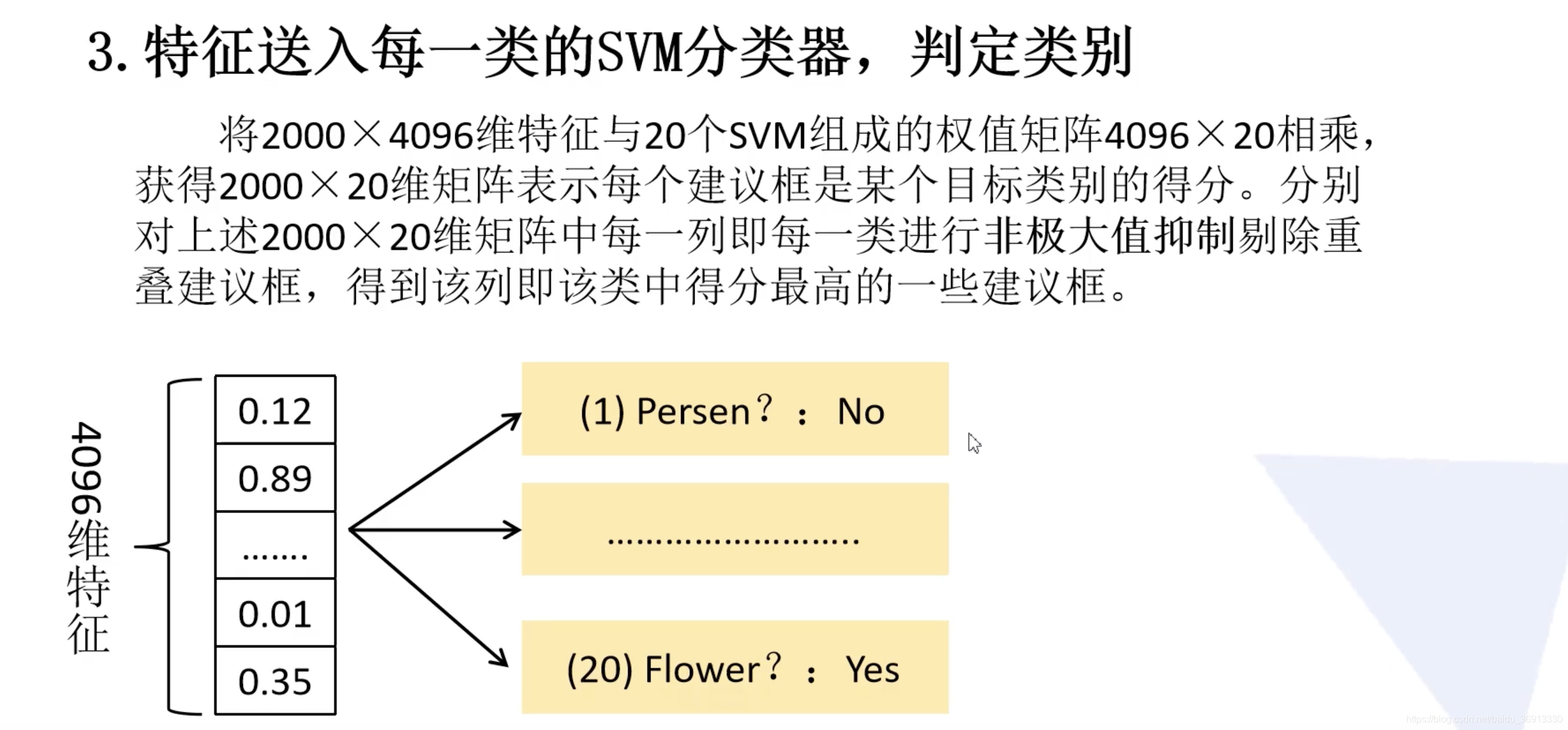
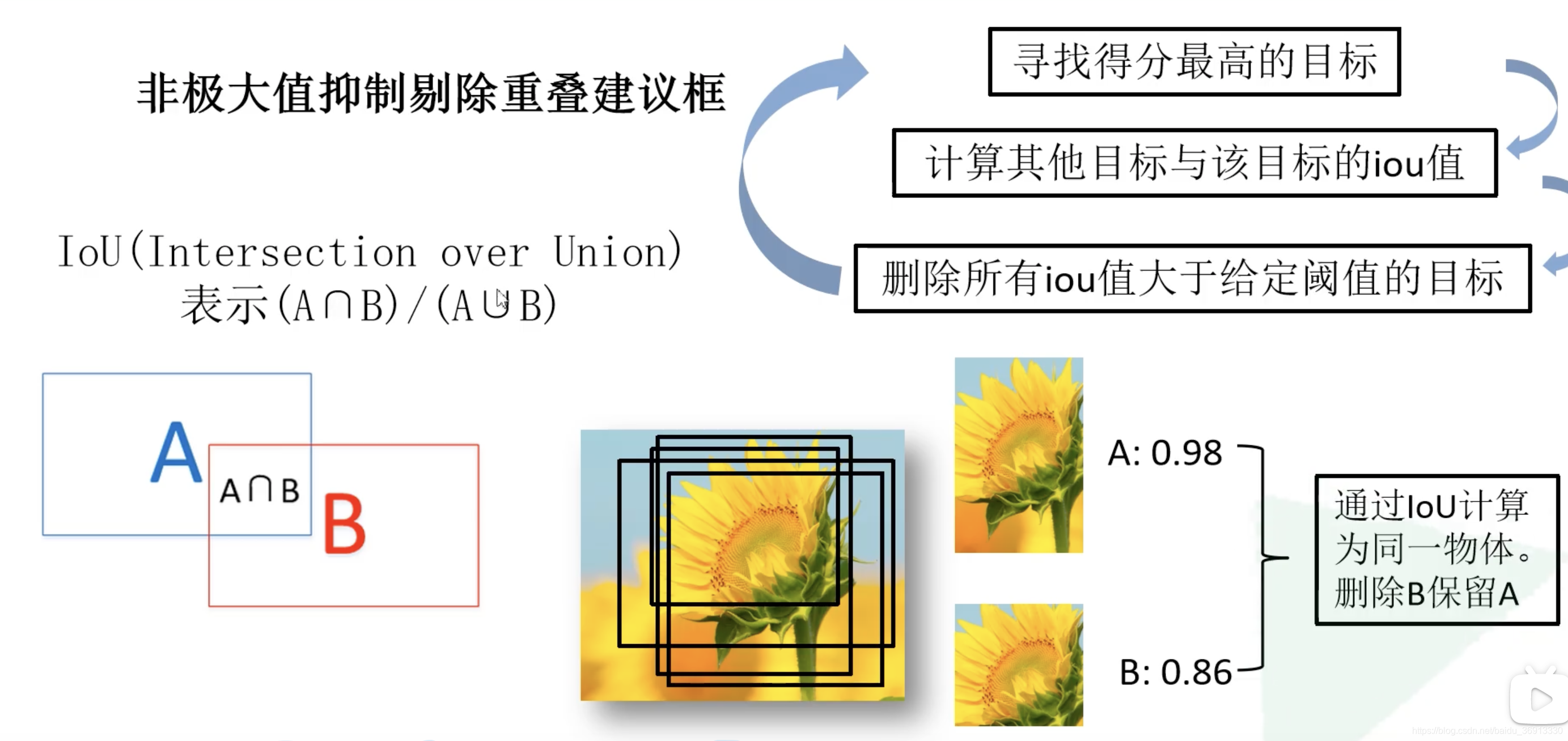
非极大值抑制的实现可见下图,首先找到得分最高的候选框,然后计算其他同类候选框与之的iou,删除所有iou大于阈值的候选框,然后下一个目标等等(极大值对应着重叠区域):
对 2000 × 20 2000 \times 20 2000×20 维矩阵中每一列即每一类进行非极大值抑制,则可以剔除重叠建议框,保留高质量的建议框!
1.4 使用回归器精细修正候选框位置
对 NMS(非极大值抑制)处理后剩余的建议框进行进一步筛选。接着分别用 20 个回归器对上述 20 个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的 bounding box。回归器得到四个值:x和y方向的偏移量,高度和宽度的缩放值。 回归器的具体训练方法在这里就没讲了,在讲Faster-RCNN的时候会进行讲解。我想应该是有预测框,有ground-truth然后训练得到的。

1.5 小结
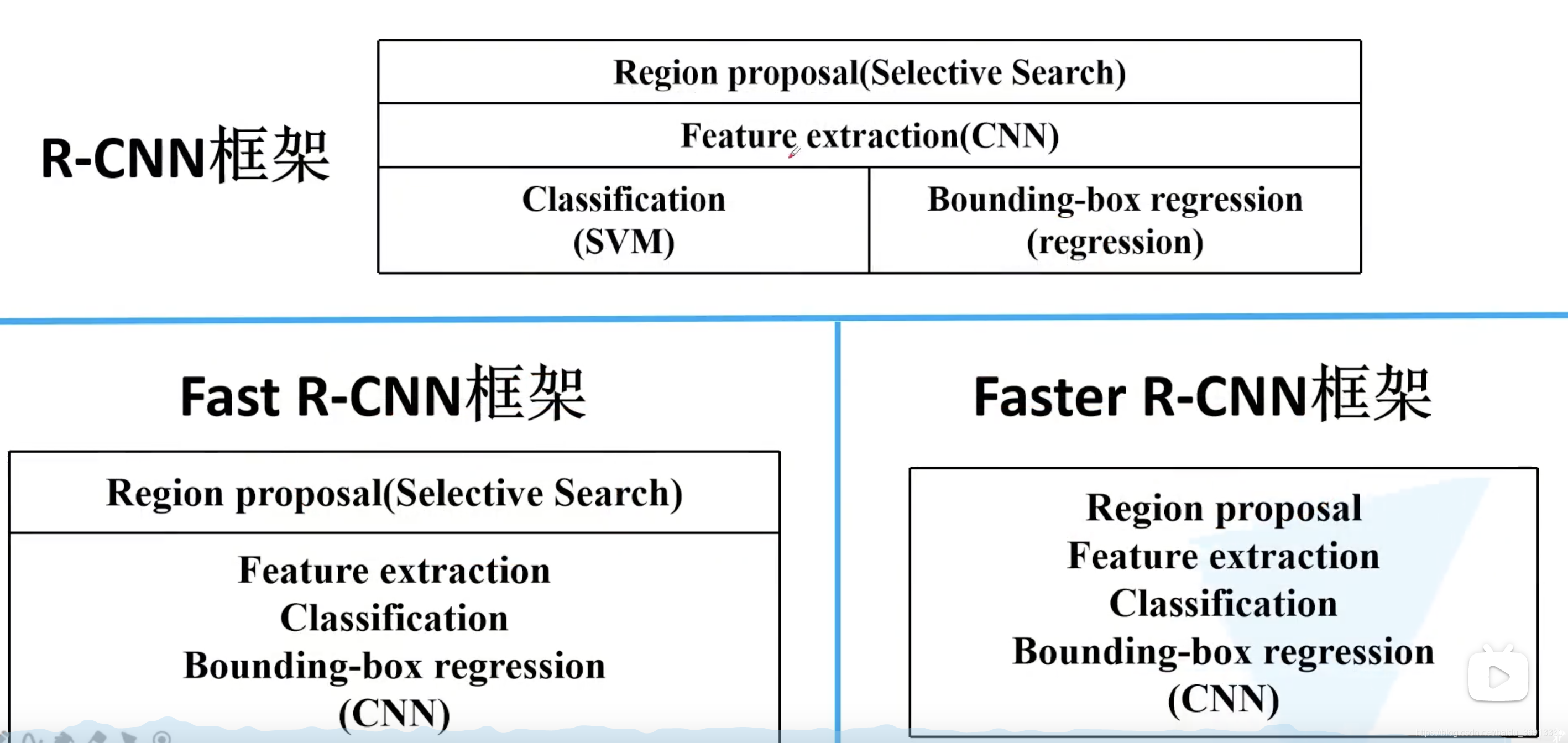
总结起来,R-CNN 包括以下四部分:
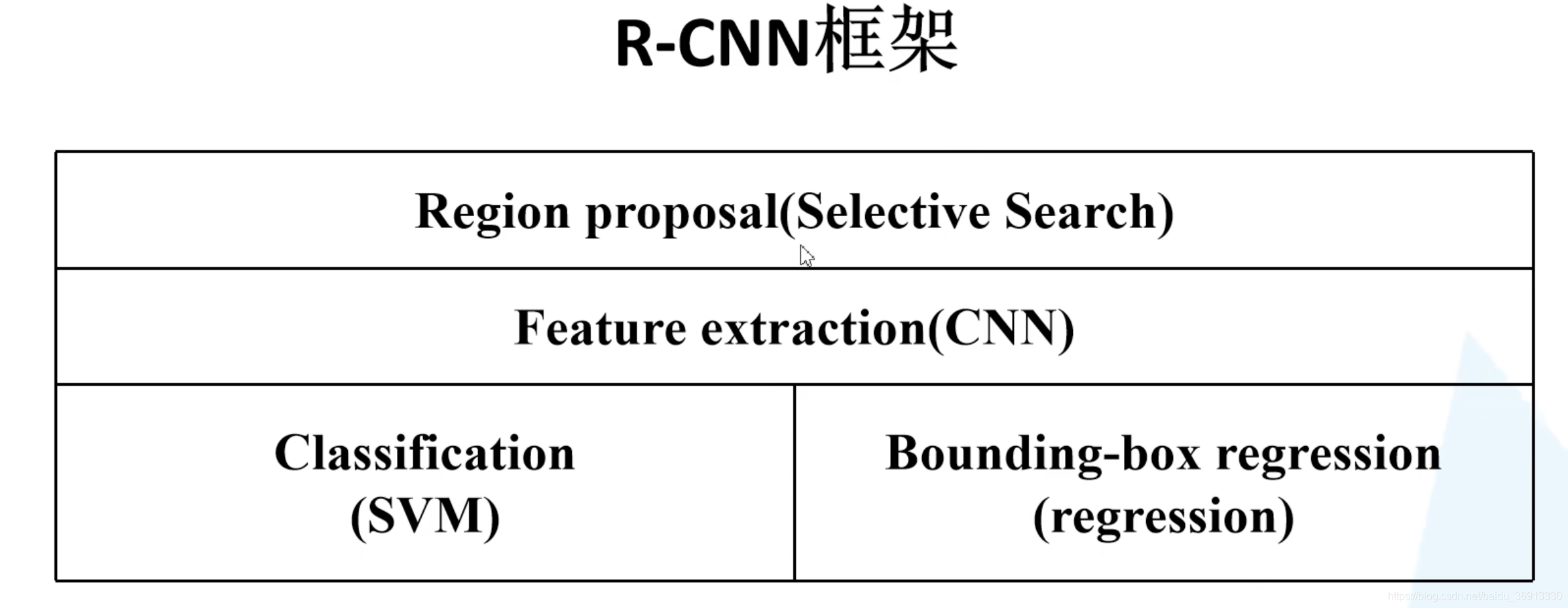
在后面讲 Fast-RCNN 和 Faster-RCNN 的时候这四部分会逐步融合,最终生成一个端对端的完整的网络。
R-CNN 存在的问题:
- 测试速度慢
- 测试一张图约需要 53s (多核CPU),用SS算法提取候选框用时约 2s,一张图像内候选框之间存在大量的重叠,提取特征操作冗余(Fast RCNN将会对其进行优化)。
- 训练速度慢
- 过程及其繁琐
- 训练所需空间大
- 对于 SVM 和 bbox 回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络如 VGG16,从 VOC2007 训练集上的 5k 张图像上提取的特征需要上百GB的存储空间。
2. Fast R-CNN
Fast R-CNN 是作者 Ross Girshick 继 R-CNN 后的又一力作,论文名就叫做 Fast R-CNN,2015年发表的。同样使用 VGG16 作为网络的 backbone,与 R-CNN 相比训练时间快了 9 倍,测试推理时间快了 213 倍,准确率从 62% 提升至了 66% (在 Pascal VOC 数据集上)
Fast R-CNN 算法流程分三个步骤:
- 一张图像生成1k~2k个候选区域(使用 Selective Search 方法)
- 将图像输入网络得到相应的特征图,将 Selective Search 算法生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过 ROI pooling 层(可以看做是SPPNet的简化版本,了解可参考 此处)缩放为 7 × 7 7 \times 7 7×7 大小的特征图,接着将特征图展平通过一系列全连接层获得预测结果。
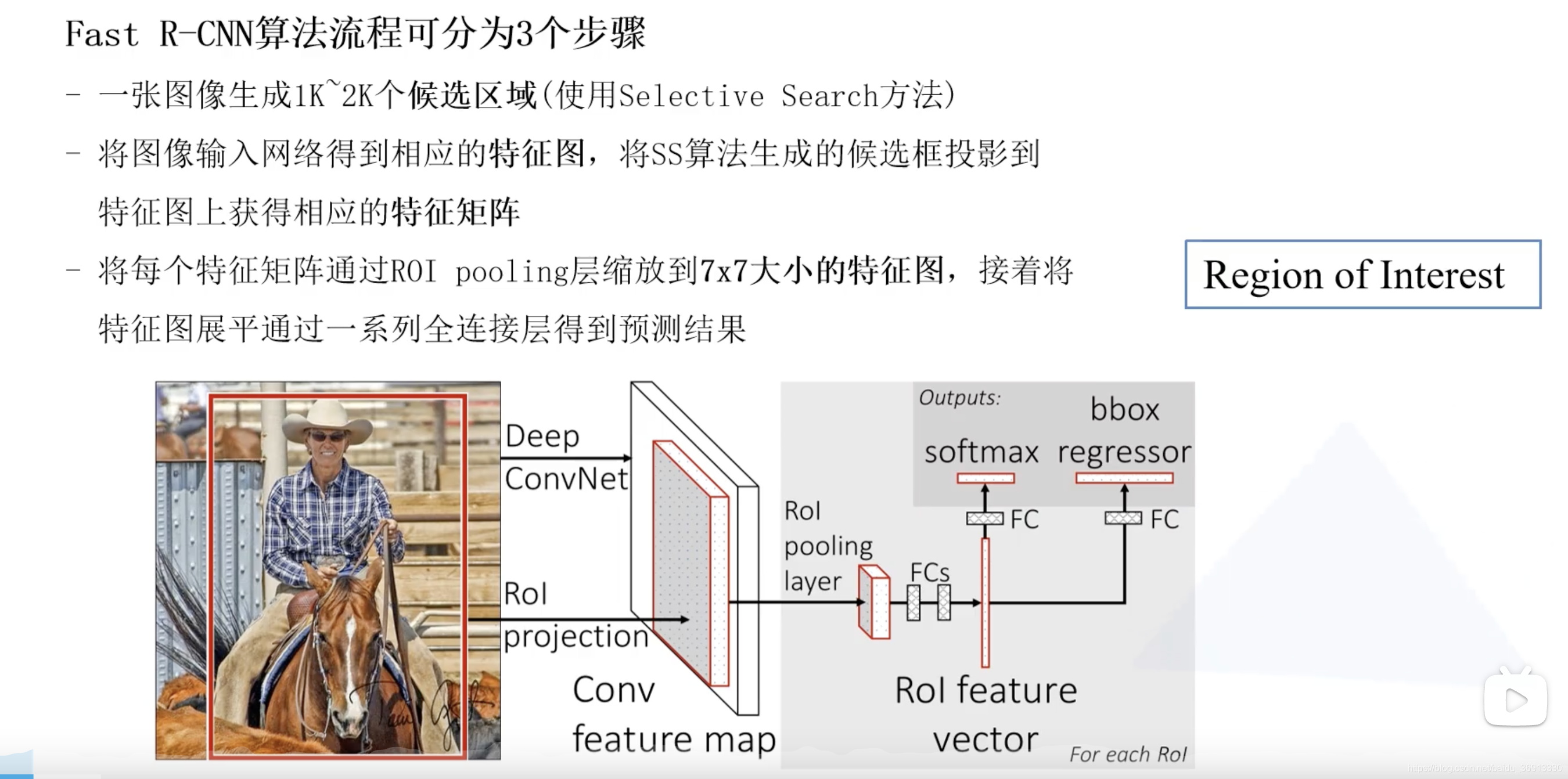
2.1 CNN 模块
第二步就已经和 R-CNN 完全不同了,第三步中 ROI 就是 Region of interest,即感兴趣区域。边界框和目标所属类别同时进行预测。Fast R-CNN 关键在于如何生成候选框的特征?
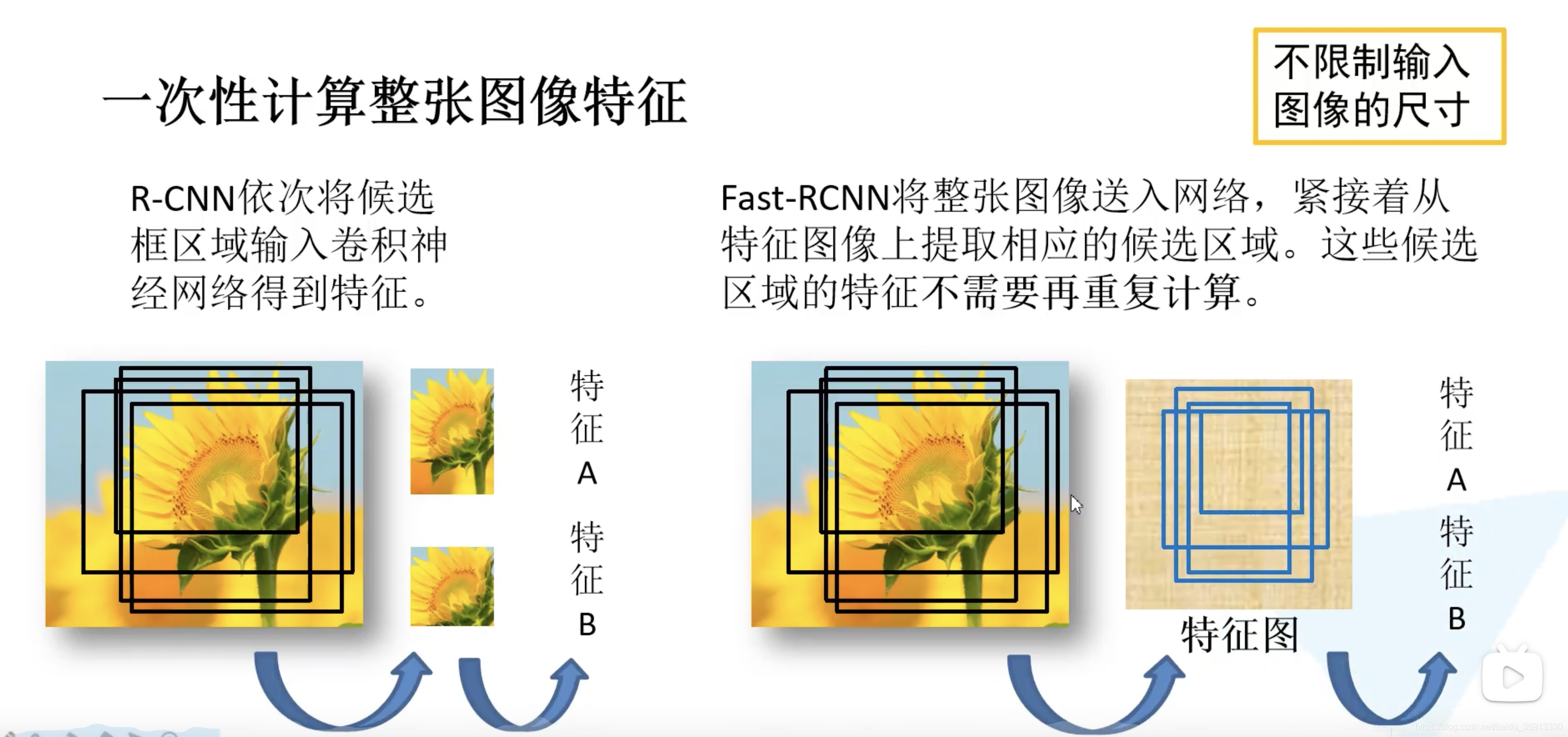
带重复的候选框内的特征不需要重复计算了。训练过程中并不是使用 SS 算法提供的所有的候选区域,训练过程其实只需用使用 2000 个中的一小部分就可以了。

有了训练样本之后,再通过 ROI pooling 层缩放到统一的尺寸。
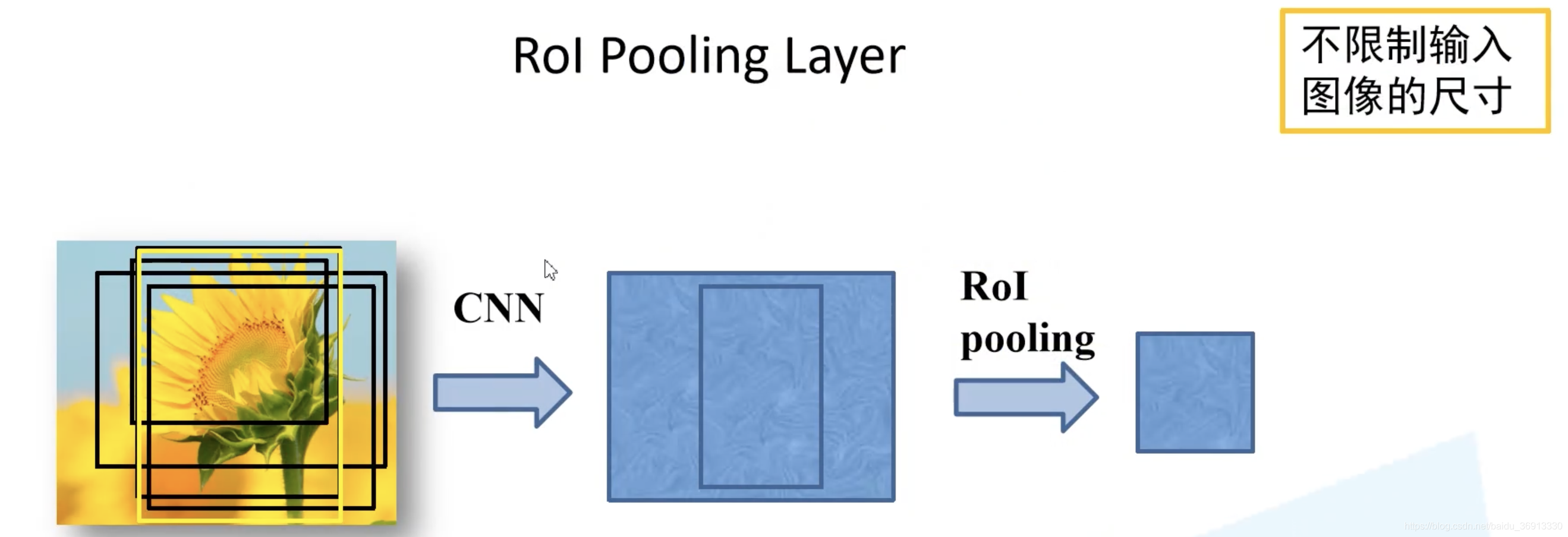
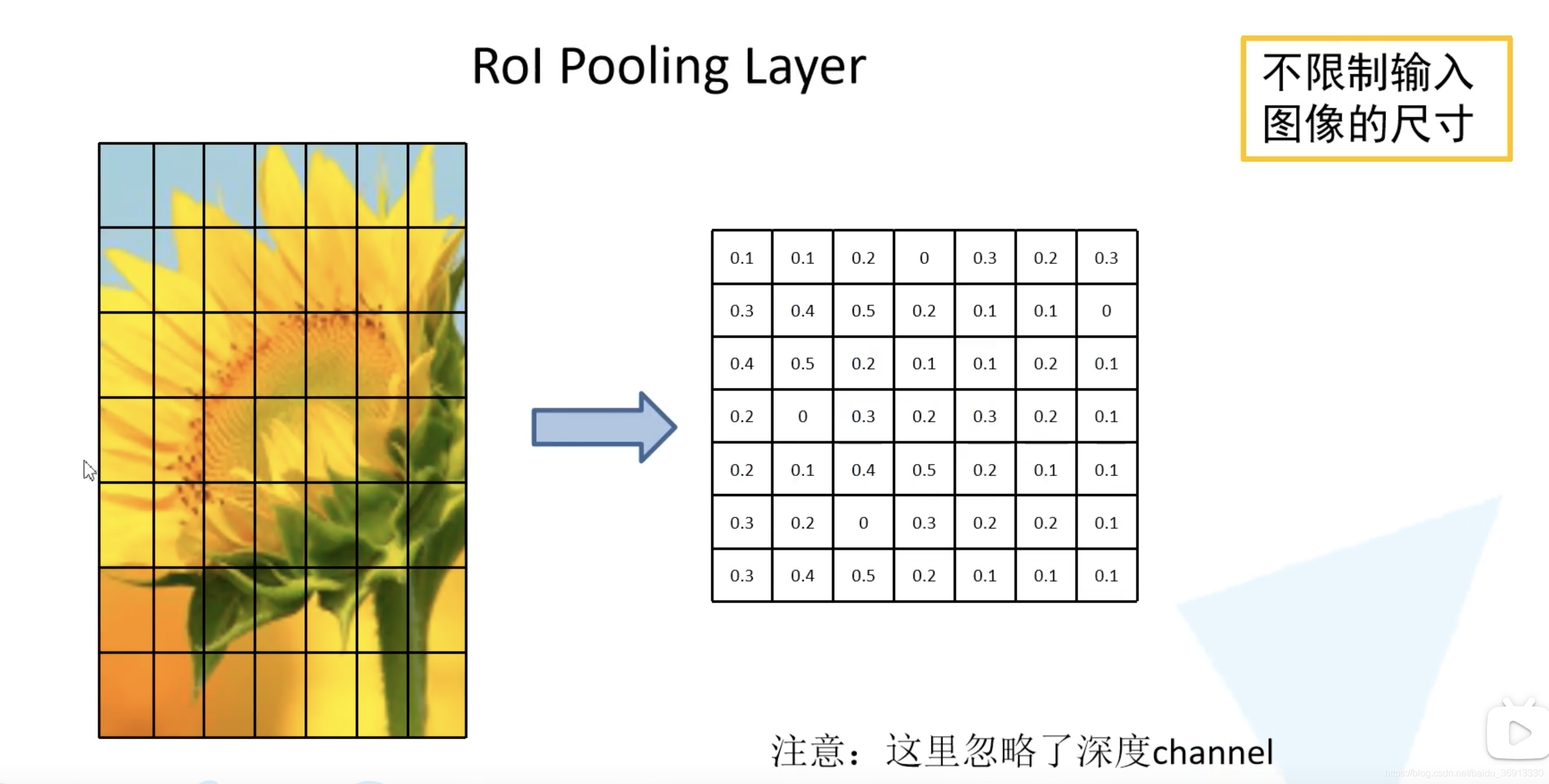
ROI pooling 层如何实现的呢?假设左边的图是一个候选区域在我们特征图上对应的特征矩阵。得到的特征矩阵讲他化为 7 × 7 7 \times 7 7×7 的 49 等份,对于每个区域执行最大池化下采样。无论特征矩阵是什么尺寸的,就可以都统一缩放为 7 × 7 7 \times 7 7×7 大小,这样就可以不限制输入图像的尺寸了。下面示意图是对于一个channel进行操作,其余channel操作相同。
最后的 Fast R-CNN 网络结构如下所示,最后是并联了两个全连接层分别对分类和bbox进行预测。分类结点数为 N+1,因为需要增加上背景。bbox预测的全连接层则是 4 × ( 20 + 1 ) = 84 4 \times (20 + 1) = 84 4×(20+1)=84 个结点,对每一类都要预测出来边界框参数。
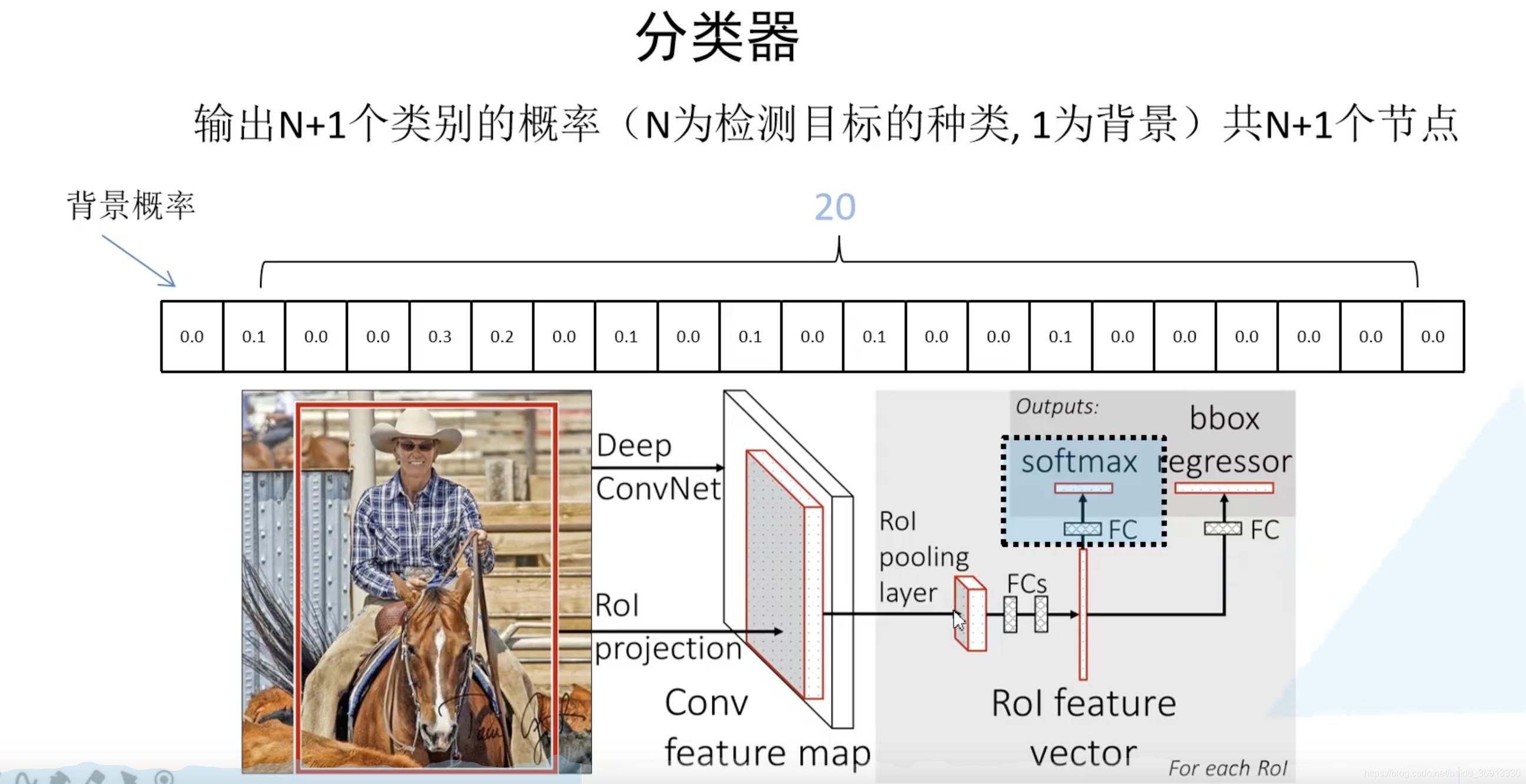

看上去边界框回归器的输出很奇怪,怎么得到预测框呢?从下图可见, d x d_x dx 和 d y d_y dy 是用来调整候选框中心坐标的参数, d w d_w dw 和 d h d_h dh 是用来调整候选框大小的参数。通过这个公式我们也可以计算 ground-truth 的 v x , v y , v w , v h v_x, v_y, v_w, v_h vx,vy,vw,vh 四个候选框参数。

2.2 损失函数
训练损失如下所示:

分类损失其实是交叉熵损失,在交叉熵中 o i ∗ o_i^* oi∗ 只有在真实类别处为1,其余为0(one-hot code),所以 L o s s c l s = − l o g ( p u ) Loss_{cls} = -log(p_u) Losscls=−log(pu)。


边界框回归损失由四部分组成,四个预测参数的 S m o o t h L 1 Smooth_{L1} SmoothL1 损失构成的, λ \lambda λ 是一个平衡系数,第二项中括号表示当 u ≥ 1 u \geq 1 u≥1 时为1,否则为 0。 u u u 是目标的真实标签。这个部分说明候选区域确实是我们需要检测的部分,对应着正样本。当 u = 0 u = 0 u=0 对应着负样本,就没有边界框损失了。

2.3 小结
Fast R-CNN 只有两个部分了,速度瓶颈依然在 SS 算法。Faster R-CNN 将 SS 算法也交由神经网络实现,就构建出端到端的网络了。

疑问:边界框预测就意味着一张图中不能出现两个人?因为一个类别预测了一个框。
个人思考:应该是每一个投影后的区域会经过后面的全连接层,所以一个边界框中就只有一个物体,所以边界框预测仅需要对每一类预测四个参数就可以了!
3. Faster R-CNN
Faster R-CNN 是作者 Ross Girshick 继 Fast R-CNN 后的又一力作,同样使用 VGG16 作为 backbone,推理速度在 GPU 上达到 5fps(每秒检测五张图,包括候选区域生成),准确度也有一定的进步。核心在于 RPN 区域生成网络(Region Proposal Network)。
Faster R-CNN 算法流程分三个步骤:
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将 RPN 生成的候选框投影到特征图上获得相应的特征矩阵。
- 将每个特征矩阵通过 ROI pooling 层(可以看做是SPPNet的简化版本,了解可参考 此处)缩放为 7 × 7 7 \times 7 7×7 大小的特征图,接着将特征图展平通过一系列全连接层获得预测结果。

3.1 RPN 网络结构
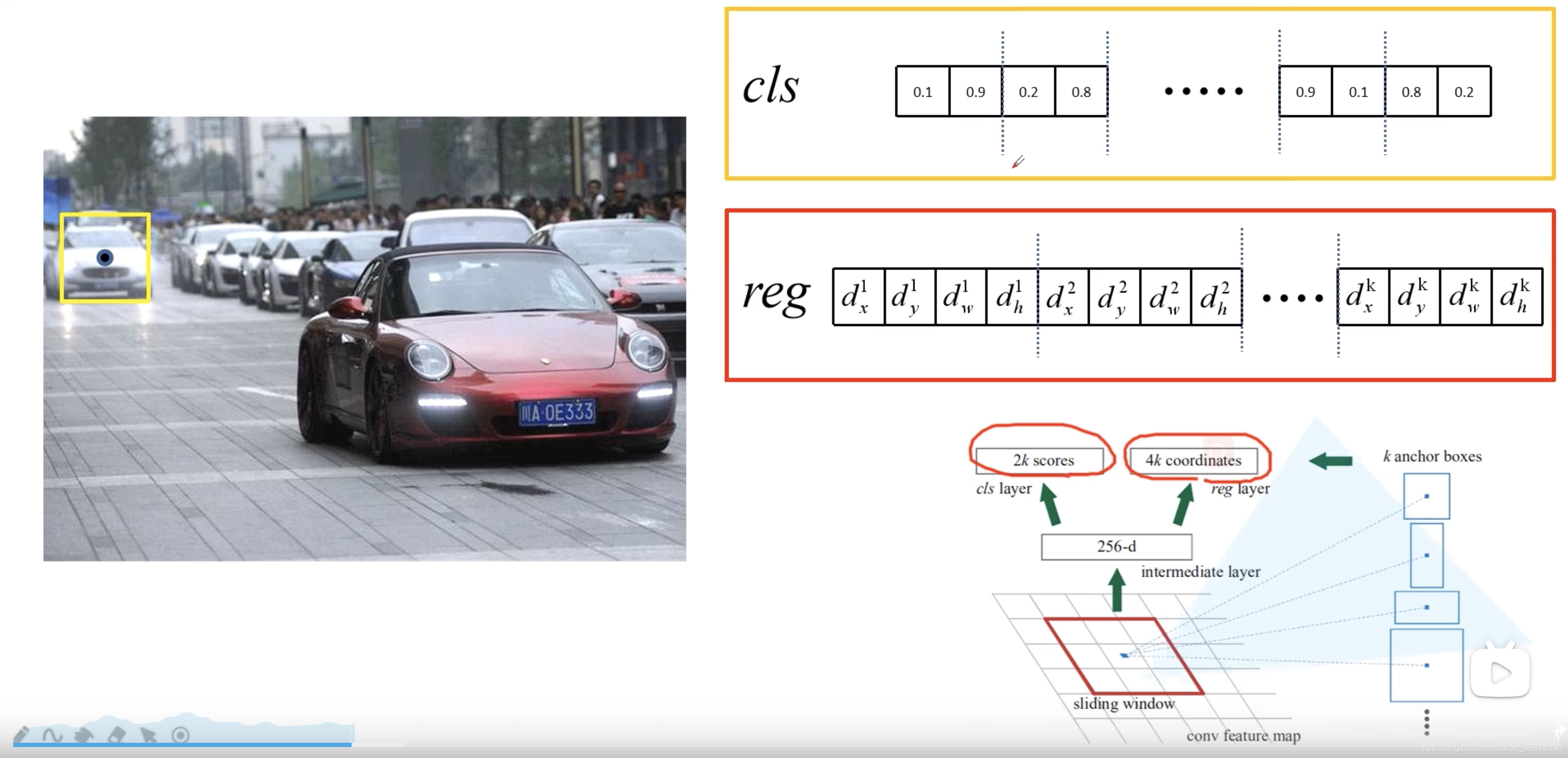
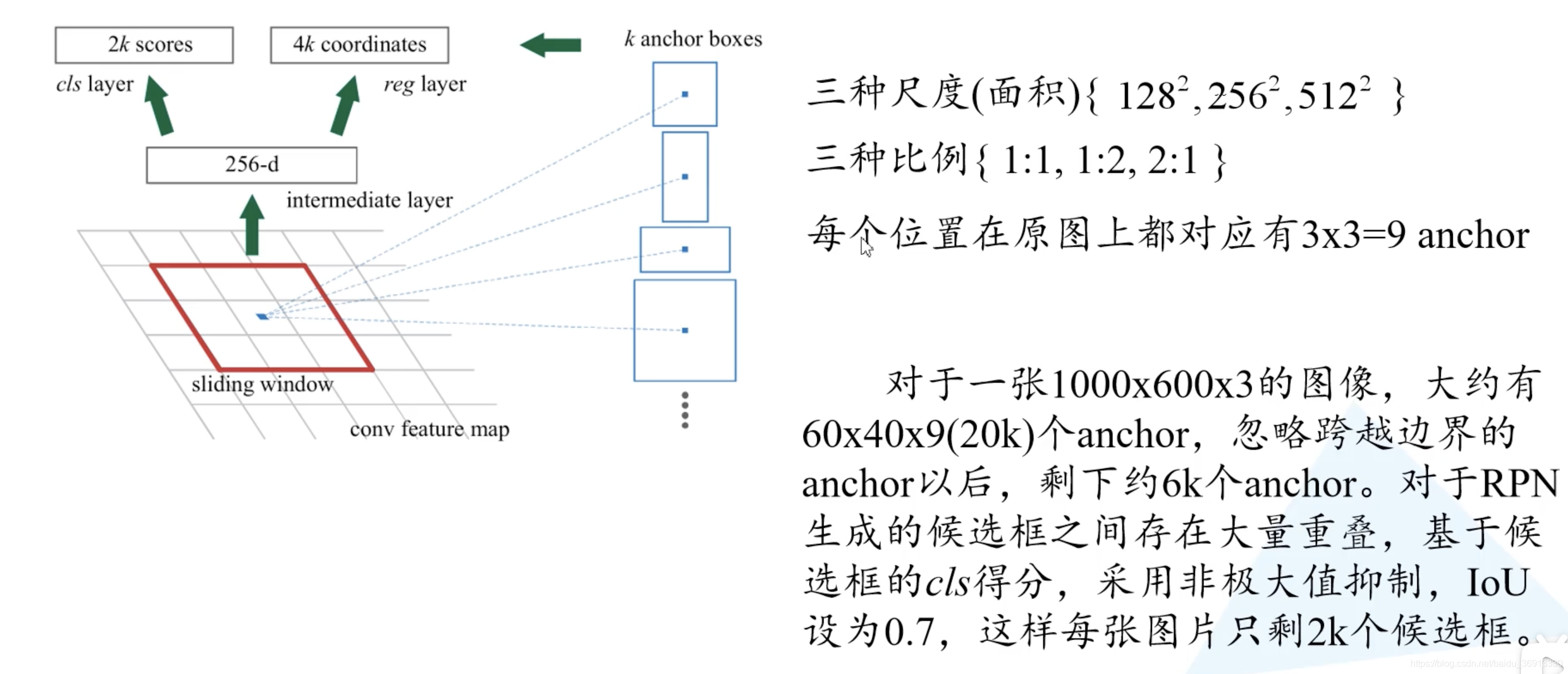
在特征图上使用滑动窗口,每滑动到一个位置生成一个一维的向量, 在向量的基础上通过两个全连接层去输出目标概率和边界框回归参数。2k 中的 k 指的是 k 个 anchor boxes,2是指为背景的概率和为前景的概率。每个 anchor 有 4 个边界框回归参数。这里一维向量的维度是根据使用backbone的通道数来定的,比如VGG16为512个通道,而使用ZF网络则是256个通道。对于每个 3 × 3 3 \times 3 3×3 的滑动窗口计算中心点在原图中的位置。然后特征图点的k 个 anchor boxes 对应着原图对应点为中心计算 k 个 anchor boxes。每个都给定了大小和形状,例如下图中给出来了三个示例。
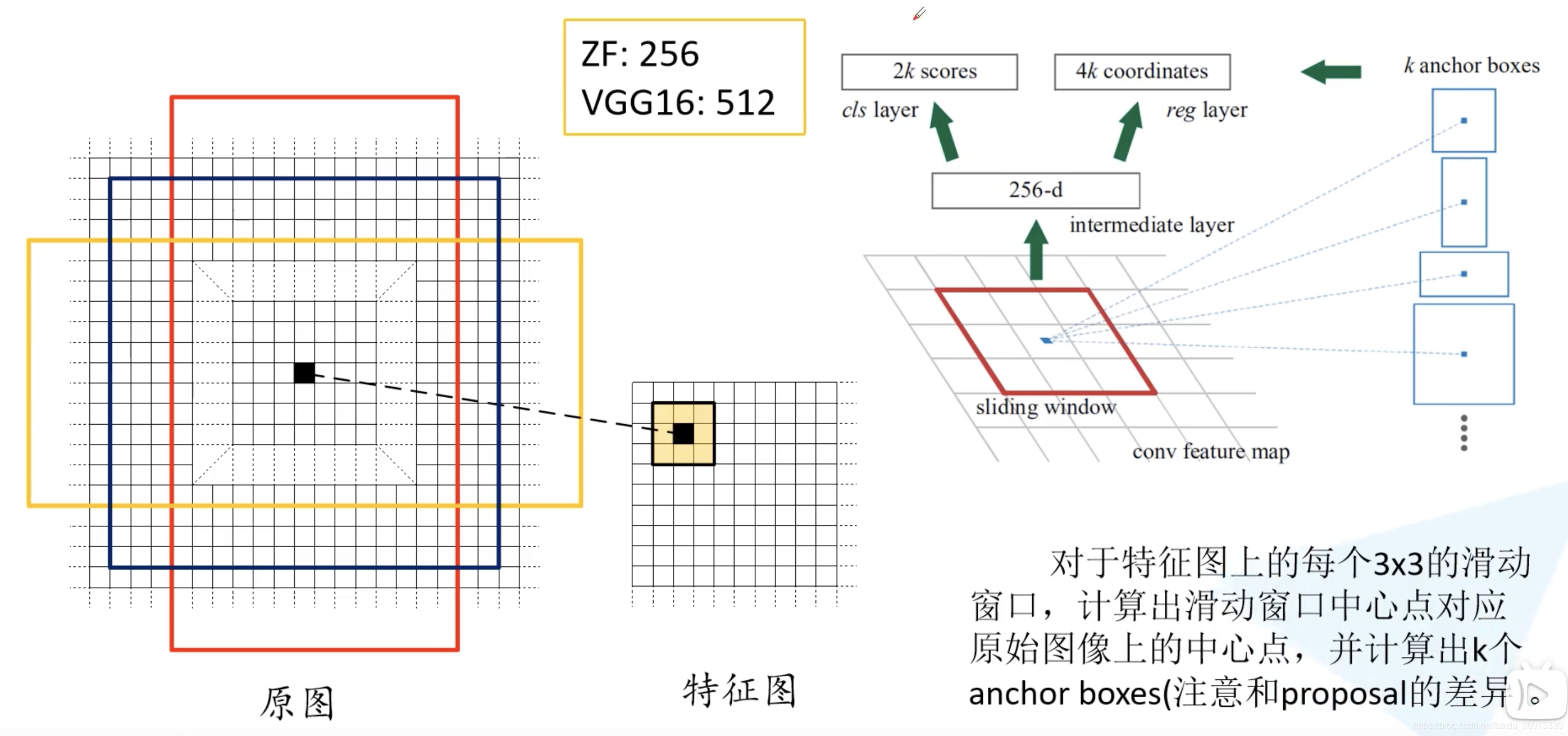
注意这里只预测每个 anchor boxes 是前景还是背景,没有具体的类别。因为是滑动窗口,所以 anchor boxes 中可能有目标物体也可能没有。然后给出了中心位置的偏移量和大小调整,训练希望能够尽可能准确的框选出目标。所检测物体的大小和长宽比都可能是不同的,所以给出了一系列的 anchor 来预测目标的位置。
接下来讲讲 Faster R-CNN 中给出了哪些尺度和比例的 anchor boxes。不同尺度不同比例对应着蓝色,红色,绿色的九个 anchor。也就是实际上每个地方都会生成 2 × 9 = 18 2 \times 9 = 18 2×9=18 个类别分数和 4 × 9 = 36 4 \times 9 = 36 4×9=36 个边界框回归参数。 3 × 3 3 \times 3 3×3 的滑动窗口在 ZF 网络中感受野为 171,而在 VGG16 中为 228。为什么还能预测 256 甚至 512 感受野呢?作者在论文中提出的观点是通过小感受野预测比他大的感受野是有可能的。例如通过经验我们看到物体的一部分就大概猜出了全貌。实际使用中这个也是有效的。
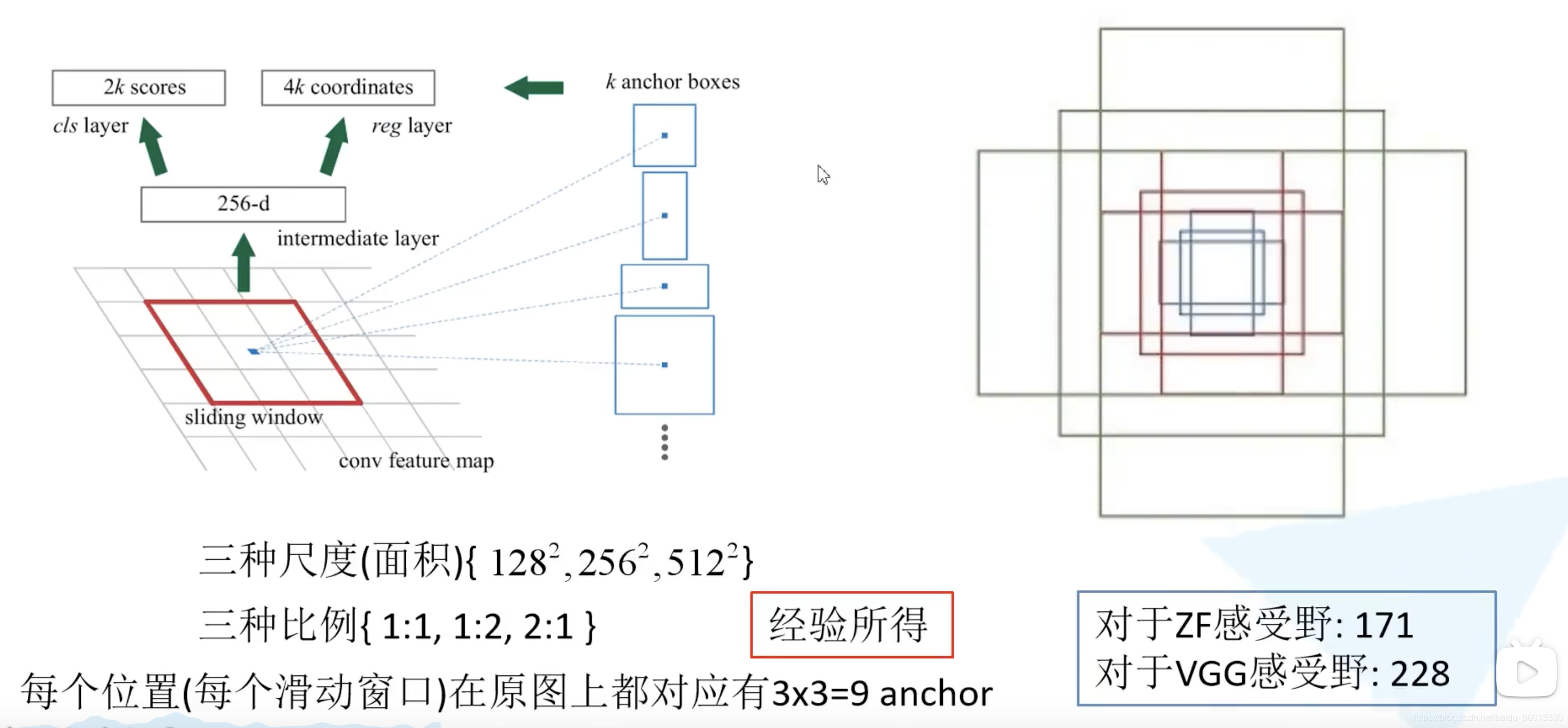
下图给出了ZF网络如何计算感受野的:
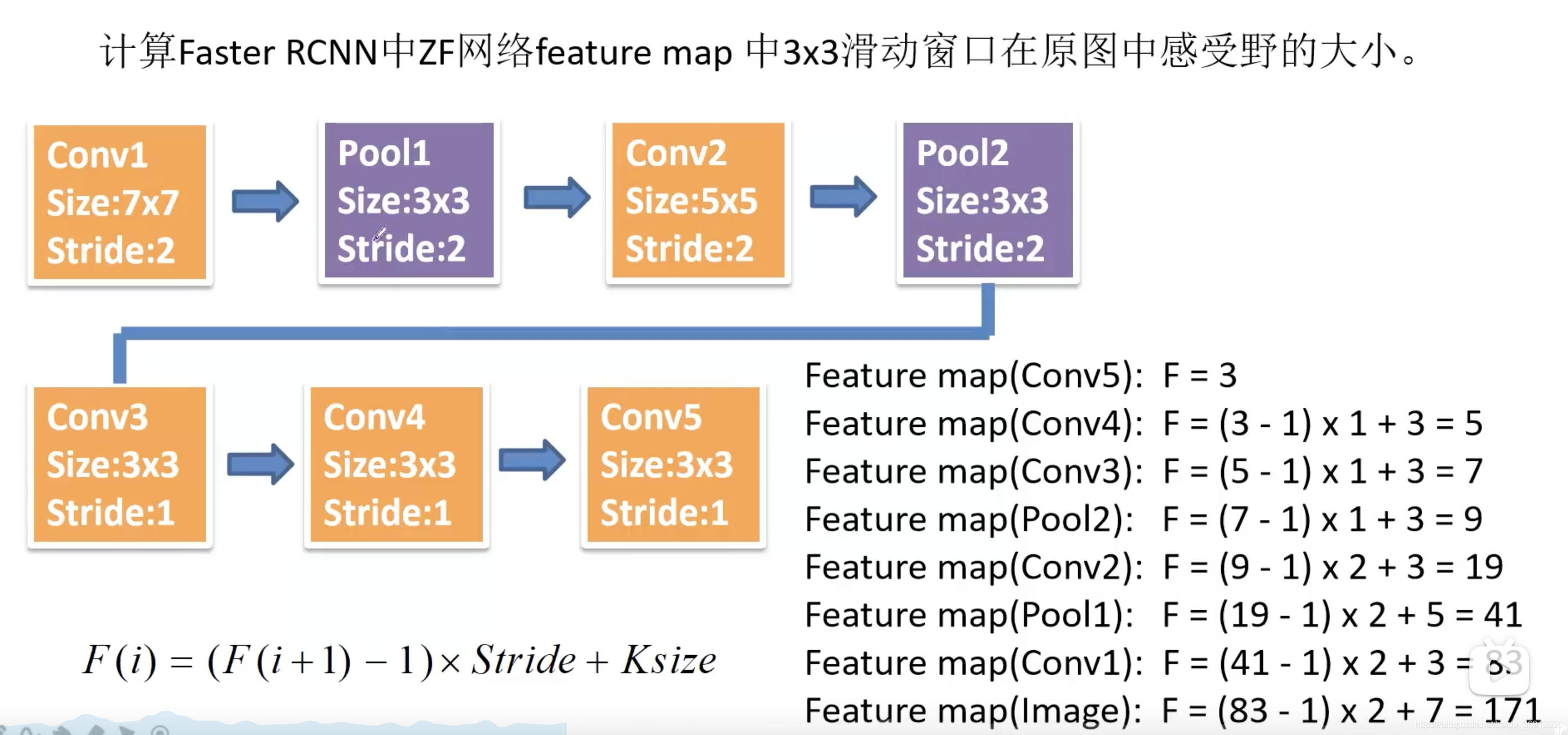
对于一个 1000 × 600 × 3 1000 \times 600 \times 3 1000×600×3 的图像,特征图大约就是 60 × 40 60 \times 40 60×40 大小。获得大量的候选框有很多的重叠,基于候选框的cls得分,采用非极大值抑制,设定 iou 为 0.7(也就是说找到最大cls的,删除和它iou大于等于0.7的候选框,然后找下一个…),就获得近似原始 SS 算法个数的 2k 个候选框。注意:anchor 和候选框不一样,anchor 加上四个边界框回归参数才能成为候选框。
多说一下滑动窗口怎么实现的?其实就是使用步长为1,padding也为 1 的 3 × 3 3 \times 3 3×3 卷积。卷积后得到的和特征图尺寸深度都是一样的。得到的特征矩阵上并联两个 1 × 1 1 \times 1 1×1 的卷积层,就能得到类别回归的预测和边界框回归的预测。
实际上生成的这么多 anchor 并不是每个都用来训练 RPN 网络。对于每张图片我们从上万个 anchor 当中采样 256 个 anchor,这些 anchor 由正样本和负样本 1:1 组成的。如果正样本不足 128,就用负样本进行填充。两种定义正样本的方式:(1)anchor 与 ground-truth 的 iou 超过 0.7,(2)某个 anchor 与 ground-truth 拥有最大的 iou。负样本是与所有的 ground-truth 的 iou 都小于 0.3 的。

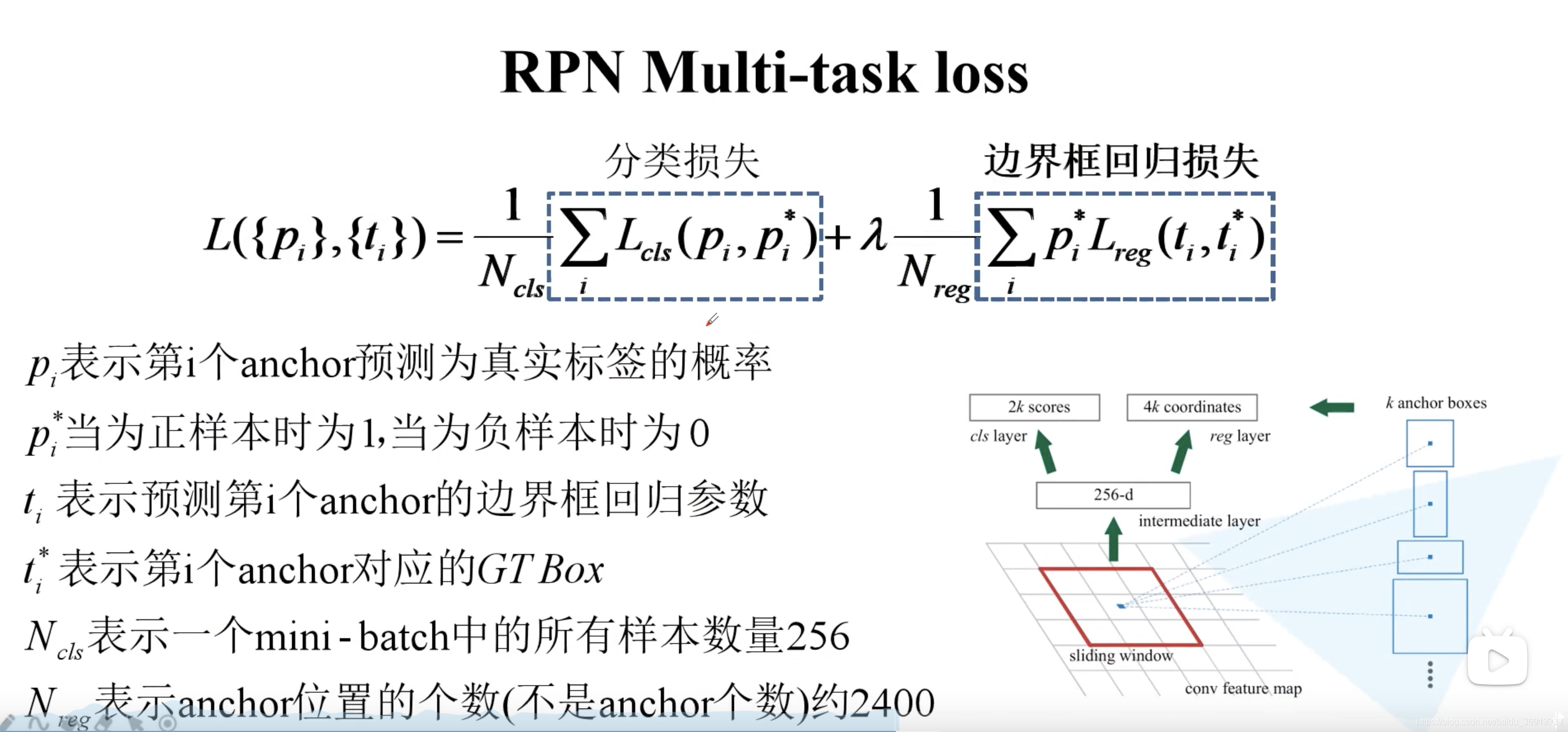
3.2 RPN 损失
RPN的损失也分为两个部分,分类损失和边界框回归损失。其中注意,anchor 位置的个数其实就是特征图大小,也就是 60 × 40 60 \times 40 60×40 近似于 2400。 λ \lambda λ 是一个平衡系数,论文中取 10。
注意分类损失这里其实用的是类似多分类的 softmax cross-entropy,而不是二分类的 sigmoid cross-entropy。在下图中,第一项损失为 − log 0.9 -\log 0.9 −log0.9,第二项因为真实标签为 0,所以为 − log 0.2 -\log 0.2 −log0.2,依此类推。
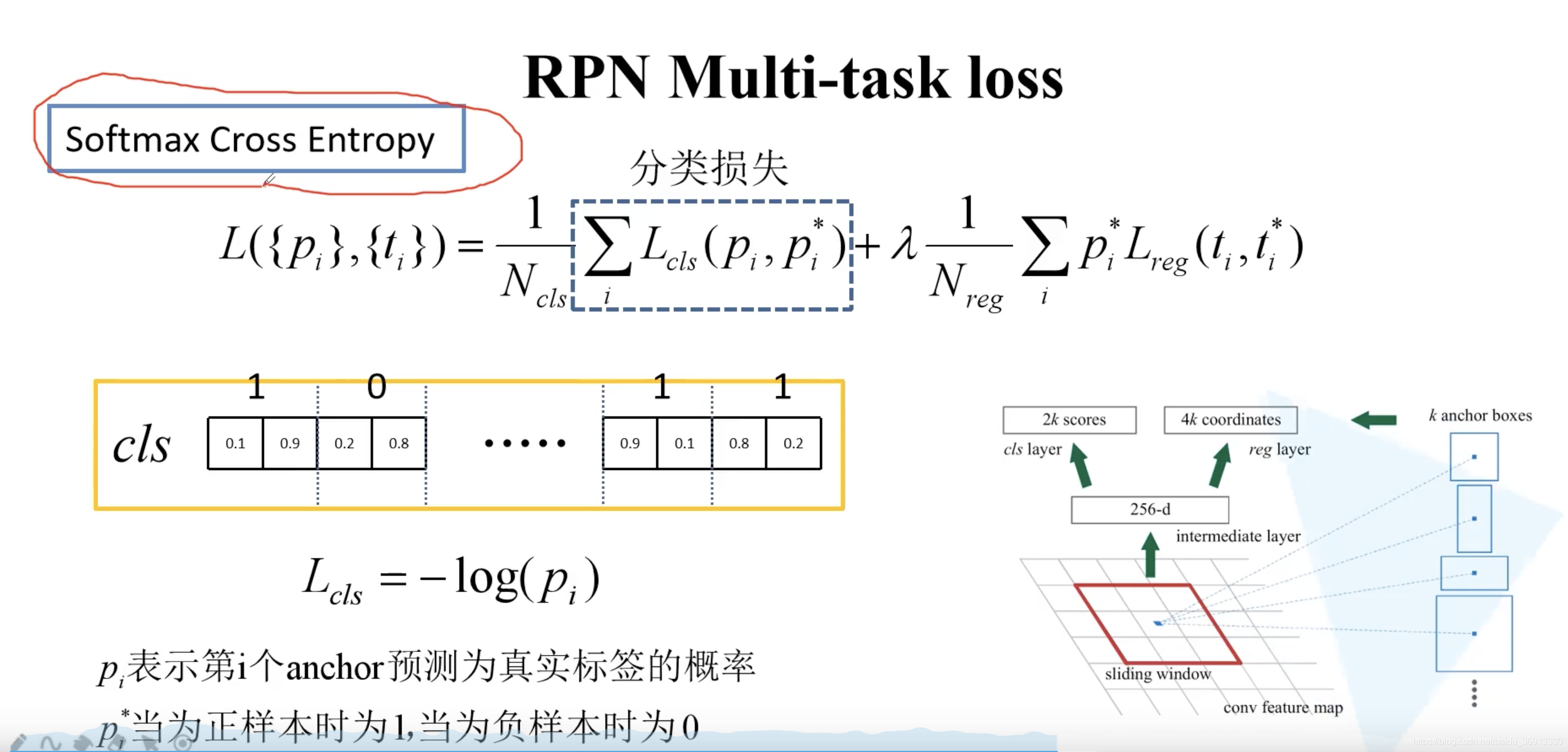
如果使用二分类的交叉熵损失,就是 k 个预测得分,而不是 2k 了。经过 sigmoid 输出后,如果是接近 1 则是前景,如果是接近 0 则是背景。此时 loss 依然是 − ( log 0.9 + log 0.8 + . . . ) -(\log 0.9+\log 0.8 + ...) −(log0.9+log0.8+...)。pytorch 官方实现的 Faster R-CNN 就是使用的二分类的交叉熵损失
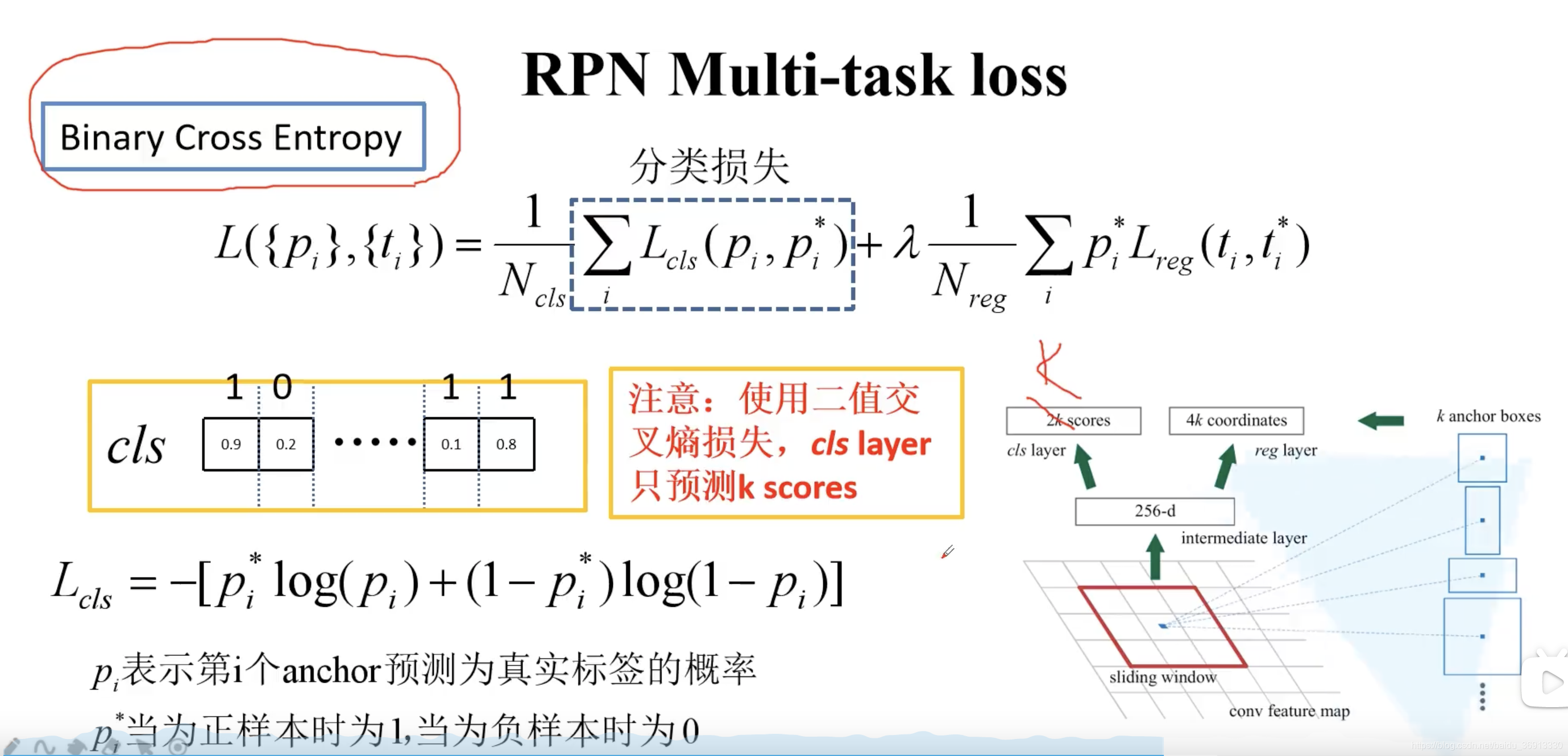
边界框回归损失和 Fast R-CNN 是一样的。 p i ∗ p_i^* pi∗ 保证只对真实的边界框才计算损失。 t t t 是直接预测出来的, t ∗ t^* t∗ 则要根据 ground-truth 计算出来。

3.3 Faster R-CNN 训练
现在是联合训练(pytorch官方实现的方法也是联合训练),原来论文是分别训练。

3.4 小结
Faster R-CNN 仅包含一个部分了。

最后比较一下 R-CNN 到 Fast R-CNN 再到 Faster R-CNN 的进步。
智能推荐
苹果https java_apple登录 后端java实现最终版-程序员宅基地
文章浏览阅读298次。import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;import com.auth0.jwk.Jwk;import com.helijia.appuser.modules.user.vo.AppleCredential;import com.helijia.common.api.model.Api..._com.auth0.jwk.jwk
NLP学习记录(六)最大熵模型MaxEnt_顺序潜在最大熵强化学习(maxent rl)-程序员宅基地
文章浏览阅读4.7k次。原理在叧掌握关于未知分布的部分信息的情况下,符合已知知识的概率分布可能有夗个,但使熵值最大的概率分布最真实地反映了事件的的分布情况,因为熵定义了随机变量的不确定性,弼熵值最大时,随机变量最不确定,最难预测其行为。最大熵模型介绍我们通过一个简单的例子来介绍最大熵概念。假设我们模拟一个翻译专家的决策过程,关于英文单词in到法语单词的翻译。我们的翻译决策模型p给每一个单词或短语分配一..._顺序潜在最大熵强化学习(maxent rl)
计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署-程序员宅基地
文章浏览阅读107次。计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署。springboot基于springboot的影视资讯管理系统。ssm基于SSM高校教师个人主页网站的设计与实现。ssm基于JAVA的求职招聘网站的设计与实现。springboot校园头条新闻管理系统。ssm基于SSM框架的毕业生离校管理系统。ssm预装箱式净水站可视化信息管理系统。ssm基于SSM的网络饮品销售管理系统。
Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素_saxparseexception; linenumber: 35; columnnumber: 9-程序员宅基地
文章浏览阅读1.6w次。不知道大家有没有遇到过与我类似的报错情况,今天发生了此错误后就黏贴复制了报错信息“Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素 'beans' 必须不含字符 [子级], 因为该类型的内容类型为“仅元素”。”然后就是一顿的百度啊, 可一直都没有找到..._saxparseexception; linenumber: 35; columnnumber: 9; cvc-complex-type.2.3:
计算机科学与技术创新创业意见,计算机科学与技术学院大学生创新创业工作会议成功举行...-程序员宅基地
文章浏览阅读156次。(通讯员 粟坤萍 2018-04-19)4月19日,湖北师范大学计算机科学与技术学院于教育大楼学院会议室1110成功召开大学生创新创业工作会议。参与本次会议的人员有党总支副书记黄海军老师,创新创业学院吴杉老师,计算机科学与技术学院创新创业活动指导老师,15、16、17级各班班主任及学生代表。首先吴杉老师介绍了“互联网+”全国大学生创新创业大赛的相关工作进度,动员各级班主任充分做好“大学生创新创业大..._湖北师范 吴杉
【Android逆向】爬虫进阶实战应用必知必会-程序员宅基地
文章浏览阅读1.1w次,点赞69次,收藏76次。安卓逆向技术是一门深奥且充满挑战的领域。通过本文的介绍,我们了解了安卓逆向的基本概念、常用工具、进阶技术以及实战案例分析。然而,逆向工程的世界仍然在不断发展和变化,新的技术和方法不断涌现。展望未来,随着安卓系统的不断更新和加固,逆向工程将面临更大的挑战。同时,随着人工智能和机器学习技术的发展,我们也许能够看到更智能、更高效的逆向工具和方法的出现。由于篇幅限制,本文仅对安卓逆向技术进行了介绍和案例分析。
随便推点
Python数据可视化之环形饼图_数据可视化绘制饼图或圆环图-程序员宅基地
文章浏览阅读1.1k次。制作饼图还需要下载pyecharts库,Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。随着学习python的热潮不断增加,Python数据可视化也不停的被使用,那我今天就介绍一下Python数据可视化中的饼图。在我们的生活和学习中,编程是一项非常有用的技能,能够丰富我们的视野,为各行各业的领域提供了新的角度。环形饼图的制作并不难,主要是在于数据的打包和分组这里会有点问题,属性的标签可以去 这个网站进行修改。图中的zip压缩函数,并分组打包。_数据可视化绘制饼图或圆环图
SpringMVC开发技术~5~基于注解的控制器_jsp/servlet到controller到基于注解的控制器-程序员宅基地
文章浏览阅读325次。1 Spring MVC注解类型Controller和RequestMapping注释类型是SpringMVC API最重要的两个注释类型。基于注解的控制器的几个优点:一个控制器类可以控制几个动作,而一个实现了Controller接口的控制器只能处理一个动作。这就允许将相关操作写在一个控制器类内,从而减少应用类的数量基于注解的控制器的请求映射不需要存储在配置文件中,而是使用RequestM..._jsp/servlet到controller到基于注解的控制器
利用波特图来满足动态控制行为的要求-程序员宅基地
文章浏览阅读260次,点赞3次,收藏4次。相位裕量可以从增益图中的交越频率处读取(参见图2)。使用的开关频率、选择的外部元件(例如电感和输出电容),以及各自的工作条件(例如输入电压、输出电压和负载电流)都会产生巨大影响。图2所示为波特图中控制环路的增益曲线,其中提供了两条重要信息。对于图2所示的控制环路,这个所谓的交越频率出现在约80 kHz处。通过使用波特图,您可以查看控制环路的速度,特别是其调节稳定性。图2. 显示控制环路增益的波特图(约80 kHz时,达到0 dB交越点)。图3. 控制环路的相位曲线,相位裕量为60°。
Glibc Error: `_obstack@GLIBC_2.2.5‘ can‘t be versioned to common symbol ‘_obstack_compat‘_`_obstack@glibc_2.2.5' can't be versioned to commo-程序员宅基地
文章浏览阅读1.8k次。Error: `_obstack@GLIBC_2.2.5’ can’t be versioned to common symbol '_obstack_compat’原因:https://www.lordaro.co.uk/posts/2018-08-26-compiling-glibc.htmlThis was another issue relating to the newer binutils install. Turns out that all was needed was to initi_`_obstack@glibc_2.2.5' can't be versioned to common symbol '_obstack_compat
基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)_电影售票系统javaweb-程序员宅基地
文章浏览阅读3k次。基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)运行环境Java≥8、MySQL≥5.7开发工具eclipse/idea/myeclipse/sts等均可配置运行适用课程设计,大作业,毕业设计,项目练习,学习演示等功能说明前台用户:查看电影列表、查看排版、选座购票、查看个人信息后台管理员:管理电影排版,活动,会员,退票,影院,统计等前台:后台:技术框架_电影售票系统javaweb
分分钟拯救监控知识体系-程序员宅基地
文章浏览阅读95次。分分钟拯救监控知识体系本文出自:http://liangweilinux.blog.51cto.com0 监控目标我们先来了解什么是监控,监控的重要性以及监控的目标,当然每个人所在的行业不同、公司不同、业务不同、岗位不同、对监控的理解也不同,但是我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。监控目标1.对系统不间断实时监控:实际上是对系统不间..._不属于监控目标范畴的是 实时反馈系统当前状态