大厂面试八股文——数据库redis-程序员宅基地
文章目录
- 最大缓存配置
- 分布式和集群
- 限流算法的几种实现
- Redis实现排行榜
- 在分布式网络中如何保证数据一致性。
- 高可用
- 高并发的实践方案有哪些?
- 分布式-CAP与ACID原则
- 一个key的value较大时的情况
- 如何保证缓存与数据库的一致性
- redis数据结构
- Redis值对象的类型和应用场景
- rehash:
- Redis的定时机制怎么实现的,有哪些弊端,你将如何改进这个弊端
- 如何保证 redis 的高并发和高可用
- Reids的特点/优缺点
- redis相比memcached有哪些优势?
- Redis线程模型
- Redis为什么这么快?
- Redis为什么是单线程的?
- redis6.0多线程实现是什么样的
- 为什么要用redis不用map做缓存
- Redis持久化方式
- Redis的RDB为什么不用线程执行?
- Reids过期时间、生存时间、永久有效设置
- Redis过期键的删除策略
- redis内存回收和内存共享
- 内存淘汰策略:
- Redis的内存用完会发生什么?
- Redis如何做内存优化?
- Redis内存划分
- redis事务
- redis主从架构
- Redis 主从复制
- redis哨兵
- redis集群
- 为什么要做Redis分区
- Redis集群会有写操作丢失吗?
- 有哪些Redis分区实现方案?
- Redis分区有什么缺点?
- Redis实现分布式锁
- 什么是 RedLock
- 如何解决 Redis 的并发竞争 Key 问题
- 缓存雪崩
- 缓存穿透
- 缓存击穿
- 缓存预热
- 缓存降级
- 热点数据和冷数据
- 布隆过滤器
- MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
- 如何保证缓存与数据库双写时的数据一致性?
- Redis常见问题及解决方案
- 在分布式网络中如何保证数据一致性。
- 高可用
- 高并发的实践方案有哪些?
- 分布式-CAP与ACID原则
- 一个key的value较大时的情况
- 如何保证缓存与数据库的一致性
数据库键总是一个字符串对象
数据库键的值可以是字符串对象、列表对象、哈希对象、集合对象、有序集合对象
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足
最大缓存配置
在redis中,允许用户设置的最大使用内存大小是 512G。
在 redis 中,允许用户设置最大使用内存大小 server.maxmemory,在内存限定的情况下是很有用的。譬如,在一台 8G 机子上部署了 4 个 redis 服务点,每一个服务点分配 1.5G 的内存大小,减少内存紧张的情况,由此获取更为稳健的服务。
分布式和集群
- 分布式
- 不同的多台服务器上部署不同的服务器模块,他们之间通过RPC(远程过程调用)来通信和调用
- 集群
- 不同的多台服务器上部署着相同的服务器模块,通过分布式调度软件统一调度
限流算法的几种实现
保障服务稳定的三大利器:熔断降级、服务限流和故障模拟。今天和大家谈谈限流算法的几种实现方式
为什么需要限流
1、与用户打交道的服务
比如web服务、对外API,这种类型的服务有以下几种可能导致机器被拖垮:
- 用户增长过快(这是好事)
- 因为某个热点事件(微博热搜)
- 竞争对象爬虫
- 恶意的刷单
这些情况都是无法预知的,不知道什么时候会有10倍甚至20倍的流量打进来,如果真碰上这种情况,扩容是根本来不及的(弹性扩容都是虚谈,一秒钟你给我扩一下试试)
2、对内的RPC服务
一个服务A的接口可能被BCDE多个服务进行调用,在B服务发生突发流量时,直接把A服务给调用挂了,导致A服务对CDE也无法提供服务。 这种情况时有发生,解决方案有两种:
- 1、每个调用方采用线程池进行资源隔离
- 2、使用限流手段对每个调用方进行限流
限流算法的实现
常见的限流算法有:计数器、令牌桶、漏桶
1、计数器算法
采用计数器实现限流有点简单粗暴,一般我们会限制一秒钟的能够通过的请求数,比如限流qps为100,算法的实现思路就是从第一个请求进来开始计时,在接下去的1s内,每来一个请求,就把计数加1,如果累加的数字达到了100,那么后续的请求就会被全部拒绝。等到1s结束后,把计数恢复成0,重新开始计数。
-
具体的实现可以是这样的:对于每次服务调用,可以通过 AtomicLong#incrementAndGet()方法来给计数器加1并返回最新值,通过这个最新值和阈值进行比较。
这种实现方式,相信大家都知道有一个弊端:如果我在单位时间1s内的前10ms,已经通过了100个请求,那后面的990ms,只能眼巴巴的把请求拒绝,我们把这种现象称为“突刺现象”
2、漏桶算法
为了消除"突刺现象",可以采用漏桶算法实现限流,漏桶算法这个名字就很形象,算法内部有一个容器,类似生活用到的漏斗,当请求进来时,相当于水倒入漏斗,然后从下端小口慢慢匀速的流出。不管上面流量多大,下面流出的速度始终保持不变。
- 不管服务调用方多么不稳定,通过漏桶算法进行限流,每10毫秒处理一次请求。因为处理的速度是固定的,请求进来的速度是未知的,可能突然进来很多请求,没来得及处理的请求就先放在桶里,既然是个桶,肯定是有容量上限,如果桶满了,那么新进来的请求就丢弃。
- 在算法实现方面,可以准备一个队列,用来保存请求,另外通过一个线程池定期从队列中获取请求并执行,可以一次性获取多个并发执行。
- 这种算法,在使用过后也存在弊端:无法应对短时间的突发流量。
3、令牌桶算法
-
从某种意义上讲,令牌桶算法是对漏桶算法的一种改进,桶算法能够限制请求调用的速率,而令牌桶算法能够在限制调用的平均速率的同时还允许一定程度的突发调用。
-
在令牌桶算法中,存在一个桶,用来存放固定数量的令牌。算法中存在一种机制,以一定的速率往桶中放令牌。每次请求调用需要先获取令牌,只有拿到令牌,才有机会继续执行,否则选择选择等待可用的令牌、或者直接拒绝。
-
放令牌这个动作是持续不断的进行,如果桶中令牌数达到上限,就丢弃令牌,所以就存在这种情况,桶中一直有大量的可用令牌,这时进来的请求就可以直接拿到令牌执行,比如设置qps为100,那么限流器初始化完成一秒后,桶中就已经有100个令牌了,这时服务还没完全启动好,等启动完成对外提供服务时,该限流器可以抵挡瞬时的100个请求。所以,只有桶中没有令牌时,请求才会进行等待,最后相当于以一定的速率执行。
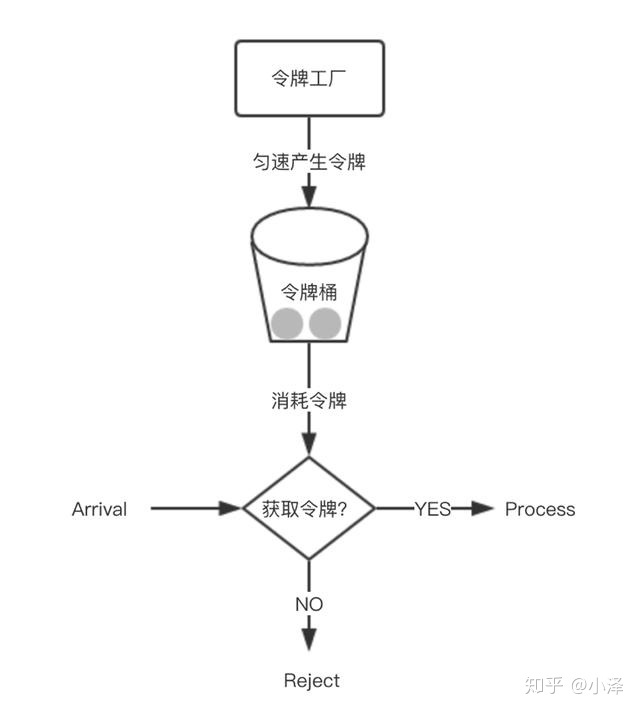
实现思路:可以准备一个队列,用来保存令牌,另外通过一个线程池定期生成令牌放到队列中,每来一个请求,就从队列中获取一个令牌,并继续执行。
幸运的是,通过Google开源的guava包,我们可以很轻松的创建一个令牌桶算法的限流器。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
通过RateLimiter类的create方法,创建限流器。
其实Guava提供了多种create方法,方便创建适合各种需求的限流器。在上述例子中,创建了一个每秒生成10个令牌的限流器,即100ms生成一个,并最多保存10个令牌,多余的会被丢弃。
rateLimiter提供了acquire()和tryAcquire()接口
- 使用acquire()方法,如果没有可用令牌,会一直阻塞直到有足够的令牌。
- 使用tryAcquire()方法,如果没有可用令牌,就直接返回false。
- 使用tryAcquire()带超时时间的方法,如果没有可用令牌,就会判断在超时时间内是否可以等到令牌,如果不能,就返回false,如果可以,就阻塞等待。
集群限流
前面讨论的几种算法都属于单机限流的范畴,但是业务需求五花八门,简单的单机限流,根本无法满足他们。
比如为了限制某个资源被每个用户或者商户的访问次数,5s只能访问2次,或者一天只能调用1000次,这种需求,单机限流是无法实现的,这时就需要通过集群限流进行实现。
**如何实现?**为了控制访问次数,肯定需要一个计数器,而且这个计数器只能保存在第三方服务,比如redis。
大概思路:
每次有相关操作的时候,就向redis服务器发送一个incr命令,比如需要限制某个用户访问/index接口的次数,只需要拼接用户id和接口名生成redis的key,每次该用户访问此接口时,只需要对这个key执行incr命令,在这个key带上过期时间,就可以实现指定时间的访问频率。
Redis实现排行榜
Zset里面的元素是唯一的,有序的,按分数从小到大排序
- 使用Redis的zset数据结构,其中key为固定值,value为排行榜名称,score为排行分数。
- 我们记录点击数,每点击一次,排行榜所在的排名越高。
- Redis的zset数据结构,使用的是从小到大的排序方式,所以我们使用负数来作为排名分数,每点击一次,排行榜的分数-1。
1.ZADD 增加与修改
其时间复杂度为 O(M*log(N)), N 是有序集的基数, M 为成功添加的新成员的数量。如果key不存在就插入,存在就更新。
使用如下:
Copyredis> ZADD page_rank 10 google.com
(integer) 1
说明:
page_rankde 是key,10是分数,google.com是value
2.ZRANK 查询
时间复杂度: O(log(N))
使用如下:
Copyredis> ZRANGE salary 0 -1 # 显示所有成员
1) "peter"
2) "tom"
3) "jack"
redis> ZRANK salary tom # 显示 tom 的薪水排名,第二
(integer) 1
说明:
salary的key,tom是value,只要输入特定的key与value就能查询到对应的排名。
3.时间复杂度: O(log(N))
使用如下:
Copyredis> ZRANGE salary 0 -1 # 显示所有成员
1) "peter"
2) "tom"
3) "jack"
redis> ZRANK salary tom # 显示 tom 的薪水排名,第二
(integer) 1
说明:
salary的key,tom是value,只要输入特定的key与value就能查询到对应的排名。
如果排行榜的设计按一个维度比如金币数量,那只需把其数量取反作为分数score即可。取反是因为zset默认从小到大排序。
如果排行榜的设计按两个维度比如金币数量和用时。由于score是一个可以double类型的参数,设计的时候可以把用时作为小数,用一天的总毫秒数减去花费毫秒数作为小数部分,然后当做字符串拼接起来,然后取反作为score.
在分布式网络中如何保证数据一致性。
拜占庭将军问题
由于地域宽广,守卫边境的多个将军(系统中的多个节点)需要通过信使来传递消息,达成某些一致的决定。但由于将军中可能存在叛徒(系统中节点出错),这些叛徒将努力向不同的将军发送不同的消息,试图会干扰一致性的达成
Leslie Lamport 证明,当叛变者不超过1/3时,存在有效的算法,不论叛变者如何折腾,忠诚的将军们总能达成一致的结果。如果叛变者过多,则无法保证一定能达到一致性。
对于拜占庭将军问题分两种情况:
-
针对非拜占庭错误的情况,一般包括 Paxos、Raft 及其变种。
分布式数据库设计一般都是基于paxos或raft算法。
-
对于要能容忍拜占庭错误的情况,一般包括 PBFT 系列、PoW 系列算法等。
从概率角度,PBFT 系列算法是确定的,一旦达成共识就不可逆转;而 PoW 系列算法则是不确定的,随着时间推移,被推翻的概率越来越小。
paxos
Paxos用于解决分布式系统中一致性问题。分布式一致性算法(Consensus Algorithm)是一个分布式计算领域的基础性问题,其最基本的功能是为了在多个进程之间对某个(某些)值达成一致(强一致);简单来说就是确定一个值,一旦被写入就不可改变。paxos用来实现多节点写入来完成一件事情,例如mysql主从也是一种方案,但这种方案有个致命的缺陷,如果主库挂了会直接影响业务,导致业务不可写,从而影响整个系统的高可用性。paxos协议是只是一个协议,不是具体的一套解决方案。目的是解决多节点写入问题。
paxos协议用来解决的问题可以用一句话来简化:
将所有节点都写入同一个值,且被写入后不再更改。
高可用
高可用HA**(**High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
往往是通过“自动故障转移”来实现系统的高可用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aN2fXWlU-1649155408069)(./pic/常见的互联网分层架构.webp)]
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据**-**缓存层:缓存加速访问存储
(6)数据**-**数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余****+****自动故障转移来综合实现的。
-
【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余来实现的。以nginx为例:有两台nginx,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
自动故障转移:当nginx挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-nginx,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的
高并发、高可用三大法宝:限流、降级、缓存,关于缓存,大家应该接触的最多,互联网业务特点就是读多写少,那么就非常适合使用缓存了
目的:
-
通过对并发访问和请求进行限速或者一个时间窗口内的请求进行限速来保护系统的可用性,一旦达到限制速率就可以拒绝服务(友好定向到错误页或告知资源没有了),排队或者等待(比如秒杀,评论,下单),降级(返回默认数据)。
-
通过压测的手段找到每个系统的处理峰值,然后通过设定峰值阈值,来防止当系统过载时,通过拒绝处理过载的请求来保障系统 可用性,同时也应该根据系统的吞吐量,响应时间,可用率来动态调整限流阈值。
分类:
- 限制总并发数—数据库连接池,线程池
- 限制瞬时并发数—nginx的limit_conn模块,用来限制瞬时并发连接数
- 限制时间窗口内的平均速率—guava的RateLimiter,nginx的limit_req模块,限制每秒平均速率
- 其他—限制远程接口调用速率,限制MQ消费速率,另外,还可以根据网络连接数,网络流量,CPU或内存负载等来限流。
算法:
- 滑动窗口协议—改善吞吐量的技术
- 漏桶—强制限制数据的传输速率,限制的流出速率
- 令牌桶—(控制(流入)速率类型的限流算法)系统以恒定的速度往桶中放入令牌,如果请求需要被处理,则需要先从桶中获取一个令牌,当桶中没有令牌可取,则拒绝服务。当平时处理速率小于桶中令牌的速率,那么在突发流量时桶内有堆积可以有效预防。
令牌桶和漏桶的对比:
- 令牌桶是按照固定的速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数为0,则拒绝新的请求
- 漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入请求数累计到漏桶容量时,则新的请求被拒绝。
- 令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,一次拿3个令牌,4个令牌),并允许一定程度并发流量
- 漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次是2),从而平滑的解决了突发流入速率
- 两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
计数器(***)—通过控制时间段内的请求次数,限制总并发数,比如数据库连接池大小,线程池大小,秒杀并发数都是计数器的用法。只要全局总请求数或者一段时间内的请求数达到设定阈值,则进行限流。对比上面的速率限流,该算法是总数量限流。
策略:
-
Nginx接入层限流
-
- 对某个key对应的总的网络连接数进行限流,可以按照一定的规则如账号,IP,系统调用逻辑等在Nginx层面做限流—连接数限流模块:limit_conn
- 对某个key对应的请求的平均速率进行限流,两种:平滑模式和允许突发模式—请求限流模块:limit_req
-
应用级限流
-
- 限流总并发/连接/请求数—设定合适的阈值(tomcat,redis,mysql等都有类似配置)
- 限流总资源数—数据库连接池,线程池
- 限流接口的总并发/请求数—适用于可降级的业务场景,可以让用户友好接受。可以使用计数器方式实现。
- 限流接口的时间窗口请求数—使用计数器方式
- 平滑限流接口请求数(应对突发流量)—令牌桶/漏桶
理解高并发高可用—限流
高并发的实践方案有哪些?
通用的设计方法主要是从「纵向」和「横向」两个维度出发,俗称高并发处理的两板斧:纵向扩展和横向扩展。
-
纵向扩展
-
提升单机的硬件性能:通过增加内存、CPU核数、存储容量、或者将磁盘升级成SSD等堆硬件的方式来提升。
-
提升单机的软件性能:使用缓存减少IO次数,使用并发或者异步的方式增加吞吐量
-
-
横向扩展
单机性能总会存在极限,所以最终还需要引入横向扩展,通过集群部署以进一步提高并发处理能力,又包括以下2个方向:
-
做好分层架构:因为高并发系统往往业务复杂,通过分层处理可以简化复杂问题,更容易做到横向扩展。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XsF9OsOy-1649155408071)(./pic/分层架构.png)]
当然真实的高并发系统架构会在此基础上进一步完善。比如会做动静分离并引入CDN,反向代理层可以是LVS+Nginx,Web层可以是统一的API网关,业务服务层可进一步按垂直业务做微服务化,存储层可以是各种异构数据库
-
各层进行水平扩展:
无状态水平扩容,有状态做分片路由。业务集群通常能设计成无状态的,而数据库和缓存往往是有状态的,因此需要设计分区键做好存储分片,当然也可以通过主从同步、读写分离的方案提升读性能。
-
高性能
-
1、集群部署,通过负载均衡减轻单机压力。
-
2、多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
-
3、分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
-
4、考虑NoSQL数据库的使用,比如HBase、TiDB等,但是团队必须熟悉这些组件,且有较强的运维能力。
-
5、异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
-
6、限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
-
7、对流量进行削峰填谷,通过MQ承接流量。
-
8、并发处理,通过多线程将串行逻辑并行化。
-
9、预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
-
10、缓存预热,通过异步任务提前预热数据到本地缓存或者分布式缓存中。
-
11、减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
-
12、减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
-
13、程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
-
14、各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
-
15、JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
-
16、锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
高可用
-
1、对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
-
2、非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
-
3、接口层面的超时设置、重试策略和幂等设计。
-
4、降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
-
5、限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
-
6、MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制等。
-
7、灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
-
8、监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
-
9、灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
高扩展
-
1、合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
-
2、存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)。
-
3、业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求源拆(比如To C和To B,APP和H5)。
分布式-CAP与ACID原则
1.1 定义
CAP是“Consistency,Avalilability, Partition Tolerance”的一种简称,其内容分别是:
(1)强一致性:即在分布式系统中的同一数据多副本情形下,对于数据的更新操作体现出的效果与只有单份数据是一样的。
(2)可用性:客户端在任何时刻对大规模数据系统的读/写操作都应该保证在限定延时内完成;
(3)分区容忍性:在大规模分布式数据系统中,网络分区现象,即分区间的机器无法进行网络通信的情况是必然发生的,所以系统应该能够在这种情况下仍然继续工作。
对于一个大规模分布式数据系统来说,CAP三要素是不可兼得的,同一系统至多只能实现其中的两个,而必须放宽第3个要素来保证其他两个要素被满足。一般在网络环境下,运行环境出现网络分区是不可避免的,所以系统必须具备分区容忍性§特性,所以在一般在这种场景下设计大规模分布式系统时,往往在AP和CP中进行权衡和选择。
1.2 为什么分布式环境下CAP三者不可兼得呢?
由于上面已经提到对于分布式环境下,P是必须要有的,所以该问题可以转化为:如果P已经得到,那么C和A是否可以兼得?可以分为两种情况来进行推演:
(1) 如果在这个分布式系统中数据没有副本,那么系统必然满足强一致性条件,因为只有独本数据,不会出现数据不一致的问题,此时C和P都具备。但是如果某些服务
器宕机,那必然会导致某些数据是不能访问的,那A就不符合了。
(2) 如果在这个分布式系统中数据是有副本的,那么如果某些服务器宕机时,系统还是可以提供服务的,即符合A。但是很难保证数据的一致性,因为宕机的时候,可能
有些数据还没有拷贝到副本中,那么副本中提供的数据就不准确了。
所以一般情况下,会根据具体业务来侧重于C或者A,对于一致性要求比较高的业务,那么对访问延迟时间要求就会低点;对于访问延时有要求的业务,那么对于数据一致性要求就会低点。一致性模型主要可以分为下面几类:强一致性、弱一致性、最终一致性、因果一致性、读你所写一致性、会话一致性、单调读一致性、以及单调写一致性,所以需要根据不同的业务选择合适的一致性模型。
-
ACID原则
ACID是关系型数据库系统采纳的原则,其代表的含义分别是: (1) 原子性(Atomicity):是指一个事务要么全部执行,要么完全不执行。 (2) 一致性(Consistency): 事务在开始和结束时,应该始终满足一致性约束。比如系统要求A+B=100,那么事务如果改变了A的数值,则B的数值也要相应修改来满足这样一致性要求;与CAP中的C代表的含义是不同的。 (3) 事务独立(Isolation):如果有多个事务同时执行,彼此之间不需要知晓对方的存在,而且执行时互不影响,事务之间需要序列化执行,有时间顺序。 (4) 持久性(Durability):事务的持久性是指事务运行成功以后,对系统状态的更新是永久的,不会无缘无故回滚撤销。
一个key的value较大时的情况
1.内存不均:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
2.阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
3.阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用。
大key的风险:
1.读写大key会导致超时严重,甚至阻塞服务。
2.如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
redis使用会出现大key的场景:
1.单个简单key的存储的value过大;
2.hash、set、zset、list中存储过多的元素。
解决问题:
1.单个简单key的存储的value过大的解决方案:
将大key拆分成对个key-value,使用multiGet方法获得值,这样的拆分主要是为了减少单台操作的压力,而是将压力平摊到集群各个实例中,降低单台机器的IO操作。
2.hash、set、zset、list中存储过多的元素的解决方案:
1).类似于第一种场景,使用第一种方案拆分;
2).以hash为例,将原先的hget、hset方法改成(加入固定一个hash桶的数量为10000),先计算field的hash值模取10000,确定该field在哪一个key上。
将大key进行分割,为了均匀分割,可以对field进行hash并通过质数N取余,将余数加到key上面,我们取质数N为997。
那么新的key则可以设置为:
newKey = order_20200102_String.valueOf( Math.abs(order_id.hashcode() % 997) )
field = order_id
value = 10
hset (newKey, field, value) ;
hget(newKey, field)
如何保证缓存与数据库的一致性
删除缓存有两种方式:
- 先删除缓存,再更新数据库。解决方案是使用延迟双删。
- 先更新数据库,再删除缓存。解决方案是消息队列或者其他 binlog 同步,引入消息队列会带来更多的问题,并不推荐直接使用。
针对缓存一致性要求不是很高的场景,那么只通过设置超时时间就可以了。
其实,如果不是很高的并发,无论你选择先删缓存还是后删缓存的方式,都几乎很少能产生这种问题,但是在高并发下,你应该知道怎么解决问题。
先删缓存,再更新数据库
1.先删除缓存,数据库还没有更新成功,此时如果读取缓存,缓存不存在,去数据库中读取到的是旧值,缓存不一致发生
延时双删的方案的思路是,为了避免更新数据库的时候,其他线程从缓存中读取不到数据,就在更新完数据库之后,再 Sleep 一段时间,然后再次删除缓存。
Sleep 的时间要对业务读写缓存的时间做出评估,Sleep 时间大于读写缓存的时间即可。
流程如下:
- 线程1删除缓存,然后去更新数据库。
- 线程2来读缓存,发现缓存已经被删除,所以直接从数据库中读取,这时候由于线程1还没有更新完成,所以读到的是旧值,然后把旧值写入缓存。
- 线程1,根据估算的时间,Sleep,由于 Sleep 的时间大于线程2读数据+写缓存的时间,所以缓存被再次删除。
- 如果还有其他线程来读取缓存的话,就会再次从数据库中读取到最新值。
先更新数据库,再删除缓存
更新数据库成功,如果删除缓存失败或者还没有来得及删除,那么,其他线程从缓存中读取到的就是旧值,还是会发生不一致。
解决方案:
- 先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果
这个解决方案其实问题更多。
- 引入消息中间件之后,问题更复杂了,怎么保证消息不丢失更麻烦。
- 就算更新数据库和删除缓存都没有发生问题,消息的延迟也会带来短暂的不一致性,不过这个延迟相对来说还是可以接受的。
为了解决缓存一致性的问题单独引入一个消息队列,太复杂了。
其实,一般大公司本身都会有监听 binlog 消息的消息队列存在,主要是为了做一些核对的工作。
这样,我们可以借助监听 binlog 的消息队列来做删除缓存的操作。这样做的好处是,不用你自己引入,侵入到你的业务代码中,中间件帮你做了解耦,同时,中间件的这个东西本身就保证了高可用。
当然,这样消息延迟的问题依然存在,但是相比单纯引入消息队列的做法更好一点。
而且,如果并发不是特别高的话,这种做法的实时性和一致性都还算可以接受的。
其他解决方案
设置缓存过期时间
每次放入缓存的时候,设置一个过期时间,比如5分钟,以后的操作只修改数据库,不操作缓存,等待缓存超时后从数据库重新读取。
如果对于一致性要求不是很高的情况,可以采用这种方案。
这个方案还会有另外一个问题,就是如果数据更新的特别频繁,不一致性的问题就很大了。
在实际生产中,我们有一些活动的缓存数据是使用这种方式处理的。
因为活动并不频繁发生改变,而且对于活动来说,短暂的不一致性并不会有什么大的问题。
redis数据结构
简单动态字符串
构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示
struct sdshdr{
//记录buf数组中已使用字节的数量
//等于 SDS 保存字符串的长度
int len;
//记录 buf 数组中未使用字节的数量
int free;
//字节数组,用于保存字符串
char buf[];
}
C字符串与SDS之间的区别:
-
常数复杂度获取字符串长度
redis将获取字符串的长度将为 O ( 1 ) O(1) O(1),确保获取字符串长度的工作不会成为redis的性能瓶颈
-
杜绝缓冲区溢出
- C字符串不记录自身长度易造成缓冲区溢出。比如strcat将src字符串中的内容拼接到dest字符串的末尾
- SDS杜绝缓冲区溢出的可能性:当SDS的API对SDS进行修改时,API先检查SDS的空间是否满足修改所需的要求,如果不满足话,API自动将SDS的空间扩展至执行修改所需的大小。
-
减少修改字符串带来的内存重分配问题
通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略
-
二进制安全
- C字符串中的字符必须符合某种编码,并且除了字符串的末尾之外,字符串里面不能包含空字符,否则最先被程序读入的空字符将误认为是字符串结尾。限制C字符只能保持文本数据,二不能保存图片、音频、视频、压缩文件这样的二进制数据。
- SDS的API是二进制安全的,不仅可以保存文本数据,还可以保存任意格式的二进制数据。
-
兼容部分C字符串函数
链表
链表键的底层实现之一就是链表。当一个列表键包含了数量比较多的元素,又或列表中包含的元素都是比较长的字符串时,redis就会用链表作为列表键的底层实现。
redis服务器使用链表来保存多个客户端的状态信息,以及使用链表来构建客户端输出缓冲区。
双向链表
typedef struct listNode{
struct listNode *prev;
struct listNode *next;
void *value;
}
typedef struct list{
//表头节点
listNode *head;
//表尾节点
listNode *tail;
//链表所包含的节点数量
unsigned long len;
//节点值复制函数,复制链表节点所保持的值
void *(*dup)(void *ptr);
//节点值释放函数,释放链表节点所保持的值
void *(*free)(void *ptr);
//节点值对比函数
int (*match)(void *ptr,void *key);
}list;
Redis链表特性:
-
双端:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
-
无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。
-
带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。
-
多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值
字典(哈希表)
redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希节点就保存了字典中的一个键值对。
哈希表结构定义:
typedef struct dictht{
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
//总是等于 size-1
unsigned long sizemask;
//该哈希表已有节点的数量
unsigned long used;
}dictht
哈希表是由数组 table 组成,table 中每个元素都是指向 dict.h/dictEntry 结构,dictEntry 结构定义如下:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntry
哈希表最大的问题是存在哈希冲突,如何解决哈希冲突,有开放地址法和链地址法。这里采用的便是链地址法,通过next这个指针可以将多个哈希值相同的键值对连接在一起,用来解决哈希冲突。
- 哈希算法:Redis计算哈希值和索引值方法如下:
#1、使用字典设置的哈希函数,计算键 key 的哈希值``
hash = dict->type->hashFunction(key);
#2、使用哈希表的sizemask属性和第一步得到的哈希值,计算索引值``
index = hash & dict->ht[x].sizemask;
-
解决哈希冲突:这个问题上面我们介绍了,方法是链地址法。通过字典里面的 *next 指针指向下一个具有相同索引值的哈希表节点。
-
扩容和收缩:当哈希表保存的键值对太多或者太少时,就要通过 rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。具体步骤:
- 如果执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
- 重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
- 所有键值对都迁徙完毕后,释放原哈希表的内存空间。
-
触发扩容的条件:
- 服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
ps:负载因子 = 哈希表已保存节点数量 / 哈希表大小。
-
渐近式 rehash
什么叫渐进式 rehash?
- 扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在Redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。
- Redis采用渐进式 rehash,这样在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的
跳跃表
为什么要使用skiplist而不是红黑树
-
skiplist的复杂度和红黑树一样,而且实现起来更简单。
-
在并发环境下skiplist有另外一个优势,红黑树在插入和删除的时候可能需要做一些rebalance的操作,这样的操作可能会涉及到整个树的其他部分,而skiplist的操作显然更加局部性一些,锁需要盯住的节点更少,因此在这样的情况下性能好一些
就是在server端,对并发和性能有要求的情况下,如何选择合适的数据结构(这里是跳跃表和红黑树)。如果单纯比较性能,跳跃表和红黑树可以说相差不大,但是加上并发的环境就不一样了,如果要更新数据,跳跃表需要更新的部分就比较少,锁的东西也就比较少,所以不同线程争锁的代价就相对少了,而红黑树有个平衡的过程,牵涉到大量的节点,争锁的代价也就相对较高了。性能也就不如前者了。不过这些对redis这个单进程单线程server来说都是浮云
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。具有如下性质:
1、由很多层结构组成;
2、每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
3、最底层的链表包含了所有的元素;
4、如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
5、链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;
如果一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,redis会使用跳表来作为有序集合键的底层实现。
redis两个地方用到跳跃表:
-
实现有序集合键
-
在集群节点中用作内部结构
-
搜索:从最高层的链表节点开始,如果比当前节点要大和比当前层的下一个节点要小,那么则往下找,也就是和当前层的下一层的节点的下一个节点进行比较,以此类推,一直找到最底层的最后一个节点,如果找到则返回,反之则返回空。
-
插入:首先确定插入的层数,有一种方法是假设抛一枚硬币,如果是正面就累加,直到遇见反面为止,最后记录正面的次数作为插入的层数。当确定插入的层数k后,则需要将新元素插入到从底层到k层。
-
删除:在各个层中找到包含指定值的节点,然后将节点从链表中删除即可,如果删除以后只剩下头尾两个节点,则删除这一层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zustprd8-1649155408073)(pic/跳跃表.png)]
Redis中跳跃表节点定义如下:
typedef struct zskiplistNode {
//层
struct zskiplistLevel{
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
}level[];
//后退指针
struct zskiplistNode *backward;
//分值
double score;
//成员对象
robj *obj;
} zskiplistNode
多个跳跃表节点构成一个跳跃表:
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist;
整数集合
整数集合是集合键的底层实现之一,当一个集合只包含整数值元素,且这个集合的元素数量不多时,redis就会使用整数集合作为集合键的底层实现。
整数集合是redis用于保存整数值的集合抽象数据结构,可以保存int16_t、int32_t或int64_t的整数值,集合不会出现重复。
typedef struct intset{
//编码方式
unit32_t encoding;
unit32_t length;
int8_t contents[];
}intset
升级:将一个新元素添加导致整数集合里,并且新元素类型比整数集合现有所有元素类型都要长,整数集合需要先进行升级,才能将新元素添加到整数集合
- 根据新元素的类型,扩展整数集合底层数组的空间大小,并未新元素分配空间。
- 将底层数组现有的元素转换成与新元素相同的类型,并将类型转换后的元素放置到正确的位上,而且在放置元素的过程中,需要继续维持底层数组的有序性质不变。
- 将新元素添加到底层数组里面。
升级操作为整数集合带来了操作上的灵活性,并且尽可能节约内存。
整数集合不支持降级。
压缩列表
压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
通常作为列表键和哈希键的底层实现之一。
**压缩列表的原理:**压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fxYEmIGn-1649155408074)(pic/压缩列表.png)]
压缩列表的每个节点构成如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HWlxCl8A-1649155408076)(pic/压缩列表的每个节点构成.png)]
-
previous_entry_ength:记录压缩列表前一个字节的长度。previous_entry_ength的长度可能是1个字节或者是5个字节,如果上一个节点的长度小于254,则该节点只需要一个字节就可以表示前一个节点的长度了,如果前一个节点的长度大于等于254,则previous length的第一个字节为254,后面用四个字节表示当前节点前一个节点的长度。利用此原理即当前节点位置减去上一个节点的长度即得到上一个节点的起始位置,压缩列表可以从尾部向头部遍历。这么做很有效地减少了内存的浪费。
-
encoding:节点的encoding保存的是节点的content的内容类型以及长度,encoding类型一共有两种,一种字节数组一种是整数,encoding区域长度为1字节、2字节或者5字节长。
-
content:content区域用于保存节点的内容,节点内容类型和长度由encoding决定。
Redis值对象的类型和应用场景
Redis使用前面说的五大数据类型来表示键和值,每次在Redis数据库中创建一个键值对时,至少会创建两个对象,一个是键对象,一个是值对象,而Redis中的每个对象都是由 redisObject 结构来表示:
typedef struct redisObject{
//类型
unsigned type:4;//对象的type属性记录了对象的类型
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;//对象的 prt 指针指向对象底层的数据结构,而数据结构由 encoding 属性来决定
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tlJyD2r6-1649155408077)(pic/对象底层的数据结构.png)]
Redis五大数据类型,string,hash,list,set,zset
string(字符串):
String是最常用的一种数据类型,一个字符串类型的值能存储最大容量是512M
字符串对象的编码可以是int,raw或者embstr。
-
int 编码:保存的是可以用 long 类型表示的整数值。
-
raw 编码:保存长度大于44字节的简单字符串(SDS)(redis3.2版本之前是39字节,之后是44字节)。
-
embstr 编码:保存长度小于等于44字节的简单字符串(SDS)(redis3.2版本之前是39字节,之后是44字节)
embstr与raw都使用redisObject和sds保存数据,区别:
- embstr的使用只分配一次内存空间(因此redisObject和sds是连续的),
- raw需要分配两次内存空间(分别为redisObject和sds分配空间)。
- 与raw相比,embstr的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便
- 而embstr的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个redisObject和sds都需要重新分配空间,因此redis中的embstr实现为只读。
hash
哈希对象的键是一个字符串类型,值是一个键值对集合
可以存储多个键值对之间的映射。和字符串一样,散列存储的值既可以是字符串又可以是数字值,并且用户同样可以对散列存储的数字执行自增操作或者是自减操作
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象中,将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾。
- 保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存至的节点在后。
- 先添加到哈希对象中的键值对被放在压缩列表的表头方向,而后添加到哈希对象中的键值对会被放在压缩列表的表尾方向。
hashtable编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存。
同时满足以下两个条件,哈希对象使用ziplist编码:
- 哈希对象保存 的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量小于512个,不能满足这两个条件的哈希对象需要使用hashtable编码
list(列表)
应用:微博关注,消息队列
列表对象的编码可以是 ziplist(压缩列表) 和 linkedlist(双端链表)
当同时满足下面两个条件时,使用ziplist(压缩列表)编码:
-
列表保存元素个数小于512个
-
每个元素长度小于64字节
不能满足这两个条件的时候使用 linkedlist 编码
set(集合)
集合对象的编码可以是intset或hashtable
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。
hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含一个集合元素,而字典的值则全部被设置为NULL
当集合同时满足以下两个条件时,使用 intset 编码:
-
集合对象中所有元素都是整数
-
集合对象所有元素数量不超过512
不能满足这两个条件的就使用 hashtable 编码
使用场景:
- 共同好友、二度好友
- 利用唯一性,可以统计访问网站的所有独立 IP
- 好友推荐的时候,根据 tag 求交集,大于某个 threshold 就可以推荐
zset(有序集合)
有序集合的编码可以是 ziplist 或者 skiplist。
-
ziplist编码的压缩对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存、第一个节点保存元素的成员,第二个元素则保存元素的分值。
-
压缩列表内的集合元素按分值由小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素被放置在靠近表尾的方向。
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
-
保存的元素数量小于128;
-
保存的所有元素长度都小于64字节。
不能满足上面两个条件的使用 skiplist 编码
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构
应用场景:
-
对于string 数据类型,因为string 类型是二进制安全的,可以用来存放图片,视频等内容,另外由于Redis的高性能读写功能,而string类型的value也可以是数字,可以用作计数器(INCR,DECR),比如分布式环境中统计系统的在线人数,秒杀等。
-
对于 hash 数据类型,value 存放的是键值对,比如可以做单点登录存放用户信息。
- 对于 list 数据类型,可以实现简单的消息队列,另外可以利用lrange命令,做基于redis的分页功能
-
对于 set 数据类型,由于底层是字典实现的,查找元素特别快,另外set 数据类型不允许重复,利用这两个特性我们可以进行全局去重,比如在用户注册模块,判断用户名是否注册;另外就是利用交集、并集、差集等操作,可以计算共同喜好,全部的喜好,自己独有的喜好等功能。
-
对于 zset 数据类型,有序的集合,可以做范围查找,排行榜应用,取 TOP N 操作等
rehash:
扩展和收缩哈希表:
-
为字典的ht[1]哈希表分配空间,取决于ht[0]当前包含的键值对数量(ht[0].used),大小为 2 n 2^n 2n
- 扩展:ht[1]大小为第一个大于等于ht[0].used*2的 2 n 2^n 2n
- 收缩:ht[1]大小为第一个大于等于ht[0].used的 2 n 2^n 2n
-
将ht[0]的所有键值对rehash到ht[1]上面:rehash重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上
-
将ht[0]的键值对迁移到ht[1]后,释放ht[0],将ht[1]设置ht[0],并在ht[1]新创建一个空白哈希表,为下一次哈希准备
负载因子=哈希表已保存节点数量、哈希表大小
自动开始哈希执行扩展:
- 服务器目前没执行BGSAVE或BGREWRITEAOF命令,并且负载因子大于1
- 服务器正在执行BGSAVE命令或BGREWRITEAOF命令,并且哈希表的负载因子大于等于5
自动开始哈希执行收缩:
- 哈希表的负载因子小于0.1
为了避免rehash对服务器性能造成影响,服务器不是一次性将ht[0]里面的所有键值对全部rehash到ht[1],而是分多次、渐进式将ht[0]里面的键值对慢慢的rehash到ht[1]
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash正式开始工作。
- 在rehash进行期间,每次对字典执行添加、删除、查找或更新操作时,程序除了执行指定的操作,还将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash完成后,程序将rehashidx属性值加1
将rehash键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,避免集中式rehash带来的庞大计算量
Redis的定时机制怎么实现的,有哪些弊端,你将如何改进这个弊端
Redis服务器是一个事件驱动程序,服务器需要处理以下两类事件:文件事件(服务器对套接字操作的抽象)和时间事件(服务器对定时操作的抽象)。Redis的定时机制就是借助时间事件实现的。
一个时间事件主要由以下三个属性组成:id:时间事件标识号;when:记录时间事件的到达时间;timeProc:时间事件处理器,当时间事件到达时,服务器就会调用相应的处理器来处理时间。一个时间事件根据时间事件处理器的返回值来判断是定时事件还是周期性事件。
弊端:Redis对时间事件的实际处理时间并不准时,通常会比时间事件设定的到达事件稍晚一些。
改进:多线程?一个处理文件事件,一个处理时间事件?
如何保证 redis 的高并发和高可用
-
redis 实现高并发主要依靠主从架构,一主多从,一般来说,很多项目其实就足够了,单主用来写入数据,单机几万 QPS,多从用来查询数据,多个从实例可以提供每秒 10w 的 QPS。
-
如果想要在实现高并发的同时,容纳大量的数据,那么就需要 redis 集群,使用 redis 集群之后,可以提供每秒几十万的读写并发。
-
redis 高可用,如果是做主从架构部署,那么加上哨兵就可以了,就可以实现,任何一个实例宕机,可以进行主备切换
Reids的特点/优缺点
Redis是一个key-value存储系统,它支持丰富的数据类型
-
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存。
因为是纯内存操作,读写数据的效率极高,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB
-
支持保存多种数据结构,如string,list,set,sorted set,hash。此外单个value的最大限制是1GB,不像 memcached只能保存1MB的数据
-
数据持久化:跟memcache不同的是,储存在Redis中的数据是持久化的,断电或重启后,数据也不会丢失
-
Redis的缺点:数据库容量受到物理内存的限制,不能用作海量数据的高性能读写
Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
redis相比memcached有哪些优势?
- memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
- redis的速度比memcached快很多
- redis可以持久化其数据
Redis线程模型
Redis基于Reactor模式开发了网络事件处理器,,它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。
- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联不同的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时, 与操作相对应的文件事件就会产生, 这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
文件事件处理器以单线程方式运行, 通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性
Redis为什么这么快?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
Redis为什么是单线程的?
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了(毕竟采用多线程会有很多麻烦!)
redis6.0多线程实现是什么样的
从Redis自身角度来说,因为读写网络的read/write系统调用占用了Redis执行期间大部分CPU时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
• 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
• 使用多线程充分利用多核,典型的实现比如 Memcached。
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
• 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
• 多线程任务可以分摊 Redis 同步 IO 读写负荷
开启了多线程
- Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:io-threads-do-reads yes
线程数如何设置
-
开启多线程后,还需要设置线程数,否则是不生效的。同样修改redis.conf配置文件
官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了
Redis6.0多线程的实现机制
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U2p70V30-1649155408078)(pic/Redis6.0多线程.png)]
流程简述如下:
1、主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列
2、主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程
3、主线程阻塞等待 IO 线程读取 socket 完毕
4、主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行
5、主线程阻塞等待 IO 线程将数据回写 socket 完毕
6、解除绑定,清空等待队列
设计有如下特点:
1、IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
2、IO 线程只负责读写 socket 解析命令,不负责命令处理
Redis的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以我们不需要去考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
为什么要用redis不用map做缓存
缓存分为本地缓存和分布式缓存
-
以java为例,使用自带的map或者guava实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着jvm的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性
-
使用redis或memcached之类的称为分布式缓存
- 在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持redis或memcached服务的高可用,整个程序架构上较为复杂。
- Redis 可以用几十 G 内存来做缓存,Map 不行,一般 JVM 也就分几个 G 数据就够大了;Redis 的缓存可以持久化,Map 是内存对象,程序一重启数据就没了
Redis持久化方式
https://blog.csdn.net/hguisu/article/details/90748916
持久化:将数据(如内存中的对象)保存到可永久保存的存储设备中
Redis 为什么要持久化?
数据都是缓存在内存中的,当你重启系统或者关闭系统后,缓存在内存中的数据都会消失殆尽,再也找不回来
Redis提供了将内存数据持久化到硬盘,以及用持久化文件来恢复数据库数据的功能
-
RDB定时快照方式(snapshot): RDB 将数据库的快照(snapshot)以二进制的方式保存到磁盘中。
-
**AOF基于语句追加文件的方式:**则以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据库状态的目的。
- 默认是RDB持久
- redis 的持久化机制,将数据写入内存的同时,异步的慢慢的将数据写入磁盘文件里,进行持久化,RDB是数据,AOF是写命令。
- 同时使用 RDB 和 AOF 两种持久化机制,那么在 redis 重启的时候,会使用 AOF 来重新构建数据,因为 AOF 中的数据更加完整。
RDB定时快照方式(snapshot): RDB 将数据库的快照(snapshot)以二进制的方式保存到磁盘中。
**AOF基于语句追加文件的方式:**则以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据库状态的目的
RDB持久化
1.手动触发
生成RDB文件,一个SAVE,另一个BGSAVE
-
SAVE命令会阻塞redis服务器进程,直到RDB文件创建完,在服务器进程阻塞期间,服务器不能处理任何命令请求。
-
BGSAVE命令会派生一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求。
2.自动触发
自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave。
是将数据先存储在内存,然后当数据累计达到某些设定的伐值的时候,就会触发一次DUMP操作,将变化的数据一次性写入数据文件(RDB文件)
AOF持久化
1.手动触发
使用bgrewriteaof命令:
Redis主进程fork子进程来执行AOF重写,这个子进程创建新的AOF文件来存储重写结果,防止影响旧文件。
**因为fork采用了写时复制机制,子进程不能访问在其被创建出来之后产生的新数据。**Redis使用“AOF重写缓冲区”保存这部分新数据,最后父进程将AOF重写缓冲区的数据写入新的AOF文件中然后使用新AOF文件替换老文件
2.自动触发
和RDB一样,配置在redis.conf文件里:
- appendonly:是否打开AOF持久化功能,appendonly默认是 no, 改成appendonly yes。
- appendfilename:AOF文件名称
- appendfsync:同步频率
- auto-aof-rewrite-min-size:如果文件大小小于此值不会触发AOF,默认64MB
- auto-aof-rewrite-percentage:Redis记录最近的一次AOF操作的文件大小,如果当前AOF文件大小增长超过这个百分比则触发一次重写,默认100
RDB和AOF的优缺点
RDB持久化
优点:RDB文件紧凑,体积小,网络传输快,适合全量复制;恢复速度比AOF快很多。当然,与AOF相比,RDB最重要的优点之一是对性能的影响相对较小。
缺点:RDB文件的致命缺点在于其数据快照的持久化方式决定了必然做不到实时持久化,而在数据越来越重要的今天,数据的大量丢失很多时候是无法接受的,因此AOF持久化成为主流。此外,RDB文件需要满足特定格式,兼容性差(如老版本的Redis不兼容新版本的RDB文件)。
AOF持久化
与RDB持久化相对应,AOF的优点在于支持秒级持久化、兼容性好,缺点是文件大、恢复速度慢、对性能影响大。
如何选择合适的持久化方式
一般来说, 如果想达到足以媲美PostgreSQL的数据安全性, 你应该同时使用两种持久化功能。
-
如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失,那么你可以只使用RDB持久化。
-
有很多用户都只使用AOF持久化,但并不推荐这种方式:
因为定时生成RDB快照(snapshot)非常便于进行数据库备份,并且 RDB 恢复数据集的速度也要比AOF恢复的速度要快,除此之外, 使用RDB还可以避免AOF程序的bug
Redis持久化数据和缓存怎么做扩容?
如果Redis被当做缓存使用,使用一致性哈希实现动态扩容缩容。
如果Redis被当做一个持久化存储使用,必须使用固定的keys-to-nodes映射关系,节点的数量一旦确定不能变化。否则的话(即Redis节点需要动态变化的情况),必须使用可以在运行时进行数据再平衡的一套系统,而当前只有Redis集群可以做到这样
Redis的RDB为什么不用线程执行?
每个进程都有独立的内存空间,子进程继承的父进程内存采用copy on write机制来降低内存使用开销和提高fork的性能,进程里所有的线程是共享同一个内存空间的,所以没有copy on write。
每个进程都有一个页表,页表是内存空间的基础,进程里的线程公用一个页表,另外copy on write机制是os实现的,所以线程自己无法copy on write。
但是你可以抬杠说,可以自己实现copy on write,有个问题是你在复制buffer的时候没法控制别的线程不去操作同一块内存,加锁的话性能太差了
-
redis对rdb的定位非常简单,只是单纯的进行镜像备份,基于fork的实现刚好完全满足需求,场景非常合适。
-
Copy-on-write虽然原理简单,真要在redisDb或内存池上面高质量的实现出来,难度还是相当高的,尤其在redis这样应用广泛的项目上,代码健壮是上新功能的前提。
Reids过期时间、生存时间、永久有效设置
-
通过EXPIRE或PEXPIRE命令,客户端可以以秒或毫秒为数据库中的某个键设置生存时间
-
可以通过EXPIREAT或PEXPIREAT命令,以秒或毫秒精度给数据库中的某个键设置过期时间。
-
PERSIST命令设置永久有效
通过expire来设置key 的过期时间,那么对过期的数据怎么处理呢?
除了缓存服务器自带的缓存失效策略之外(Redis默认的有6中策略可供选择),我们还可以根据具体的业务需求进行自定义的缓存淘汰,常见的策略有两种:
- 定时去清理过期的缓存;
- 当有用户请求过来时,再判断这个请求所用到的缓存是否过期,过期的话就去底层系统得到新数据并更新缓存。
两者各有优劣,第一种的缺点是维护大量缓存的key是比较麻烦的,第二种的缺点就是每次用户请求过来都要判断缓存失效,逻辑相对比较复杂!具体用哪种方案,大家可以根据自己的应用场景来权衡。
保存过期时间
redisDb结构的expire字典保存了数据库中所有键的过期时间,称为过期字典:
- 过期字典是一个指针,指向键空间的某个键对象
- 过期字典的值是一个long long类型的整数,保存了键所指向的数据库键的过期时间——一个毫秒精度的unix时间戳
Redis过期键的删除策略
三种不同的删除策略:
-
立即删除。在设置键的过期时间时,创建一个定时器,当过期时间达到时,由时间处理器自动执行键的删除操作。
该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量
-
惰性删除。键过期了就不管。每次从dict字典中按key取值时,先检查此key是否已经过期,如果过期了就删除该键,如果没过期,就返回键值。
该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
db.c/expireIfNeeded函数实现
-
定时删除。每隔一段时间,对expires字典进行检查,删除里面的过期键。
该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
redis.c/activeExpireCycle函数实现
Redis中同时使用了惰性过期和定期过期两种过期策略。
redis内存回收和内存共享
内存回收
typedef struct redisObject{
//类型
unsigned type:4;
//编码
unsigned encoding:4;
//指向底层数据结构的指针
void *ptr;
//引用计数
int refcount;
//记录最后一次被程序访问的时间
unsigned lru:22;
}robj
Redis自己构建了一个内存回收机制,通过在 redisObject 结构中的 refcount 属性实现。这个属性会随着对象的使用状态而不断变化:
-
创建一个新对象,属性 refcount 初始化为1
-
对象被一个新程序使用,属性 refcount 加 1
-
对象不再被一个程序使用,属性 refcount 减 1
-
当对象的引用计数值变为 0 时,对象所占用的内存就会被释放。
引用计数的内存回收机制其实是不被Java采用的,因为不能克服循环引用的例子(比如 A 具有 B 的引用,B 具有 C 的引用,C 具有 A 的引用,除此之外,这三个对象没有任何用处了),这时候 A B C 三个对象会一直驻留在内存中,造成内存泄露。那么 Redis 既然采用引用计数的垃圾回收机制,如何解决这个问题呢?
在前面介绍 redis.conf 配置文件时,在 MEMORY MANAGEMENT 下有个 maxmemory-policy 配置:
maxmemory-policy :当内存使用达到最大值时,redis使用的清楚策略。有以下几种可以选择:
-
volatile-lru 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
-
allkeys-lru 利用LRU算法移除任何key
-
volatile-random 移除设置过过期时间的随机key
-
allkeys-random 移除随机key
-
volatile-ttl 移除即将过期的key(minor TTL)
-
noeviction noeviction 不移除任何key,只是返回一个写错误 ,默认选项
通过这种配置,也可以对内存进行回收。
共享内存
refcount 属性除了能实现内存回收以外,还能用于内存共享。
比如通过如下命令 set k1 100,创建一个键为 k1,值为100的字符串对象,接着通过如下命令 set k2 100 ,创建一个键为 k2,值为100 的字符串对象,那么 Redis 是如何做的呢?
-
将数据库键的值指针指向一个现有值的对象
-
将被共享的值对象引用refcount 加 1
注意:Redis的共享对象目前只支持整数值的字符串对象。之所以如此,实际上是对内存和CPU(时间)的平衡:共享对象虽然会降低内存消耗,但是判断两个对象是否相等却需要消耗额外的时间。对于整数值,判断操作复杂度为O(1);对于普通字符串,判断复杂度为O(n);而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
虽然共享对象只能是整数值的字符串对象,但是5种类型都可能使用共享对象(如哈希、列表等的元素可以使用)
对象的空转时间
在 redisObject 结构中,前面介绍了 type、encoding、ptr 和 refcount 属性,最后一个 lru 属性,该属性记录了对象最后一次被命令程序访问的时间。
使用 OBJECT IDLETIME 命令可以打印给定键的空转时长,通过将当前时间减去值对象的 lru 时间计算得到
lru 属性除了计算空转时长以外,还可以配合前面内存回收配置使用。如果Redis打开了maxmemory选项,且内存回收算法选择的是volatile-lru或allkeys—lru,那么当Redis内存占用超过maxmemory指定的值时,Redis会优先选择空转时间最长的对象进行释放。
内存淘汰策略:
Redis官方给的警告,当内存不足时,Redis会根据配置的缓存策略淘汰部分keys,以保证写入成功。当无淘汰策略时或没有找到适合淘汰的key时,Redis直接返回out of memory错误。
6种数据淘汰策略
全局的键空间选择性移除
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
设置过期时间的键空间选择性移除
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
Redis的内存用完会发生什么?
如果达到设置的上限,Redis的写命令会返回错误信息(但是读命令还可以正常返回。)或者你可以配置内存淘汰机制,当Redis达到内存上限时会冲刷掉旧的内容。
Redis如何做内存优化?
https://www.cnblogs.com/jxxblogs/p/12248245.html
可以好好利用Hash,list,sorted set,set等集合类型数据
- 通常情况下很多小的Key-Value可以用更紧凑的方式存放到一起。尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面
Redis内存划分
1.数据
作为数据库,数据是最主要的部分;这部分占用的内存会统计在used_memory中。
2.进程本身运行需要的内存
Redis主进程本身运行肯定需要占用内存,如代码、常量池等等;这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
3.缓冲内存
缓冲内存包括客户端缓冲区、复制积压缓冲区、AOF缓冲区等;其中,客户端缓冲存储客户端连接的输入输出缓冲;复制积压缓冲用于部分复制功能;AOF缓冲区用于在进行AOF重写时,保存最近的写入命令。在了解相应功能之前,不需要知道这些缓冲的细节;这部分内存由jemalloc分配,因此会统计在used_memory中。
4.内存碎片
内存碎片是Redis在分配、回收物理内存过程中产生的。例如,如果对数据的更改频繁,而且数据之间的大小相差很大,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。内存碎片不会统计在used_memory中。
redis事务
redis是怎么保证多线程进来的多个命令,保持顺序进入单线程的命令处理模块的
-
multi可以在客户端打包要执行的命令批量的提交到服务端,从而减少每条指令每次发送的网络通讯
multi指令的用途是保证multi和exec之间的所有指令不被其他客户端的指令打扰的一个个执行
-
服务端收到multi指令后,会一直等到exec指令到达,才将所有的指令一起放入队列执行
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
Redis 事务的本质是通过MULTI、EXEC、WATCH等一组命令的集合。Redis提供的事务是将多个命令打包,然后一次性、按照先进先出的顺序有序的执行。在执行过程中不会被打断*(在事务执行过程,其他客户端提交的命令请求不会插入到事务执行命令序列中),当事务队列中的所以命令都被执行(无论成功还是失败)*完毕之后,事务才会结束
Redis事务相关命令:
-
MULTI :开启事务,redis会将后续的命令逐个放入队列中,然后使用EXEC命令来原子化执行这个命令系列。
-
**EXEC:**执行事务中的所有操作命令。
-
若在事务队列中存在命令性错误,则执行EXEC命令时,所有命令都不会执行
-
若在事务队列中存在语法性错误,则执行EXEC命令时,其他正确命令会被执行,错误命令抛出异常
-
-
**DISCARD:**取消事务,放弃执行事务块中的所有命令。
-
**WATCH:**监视一个或多个key,如果事务在执行前,这个key(或多个key)被其他命令修改,则事务被中断,不会执行事务中的任何命令。同时返回Nullmulti-bulk应答以通知调用者事务执行失败
- watch指令类似于乐观锁
-
**UNWATCH:**取消WATCH对所有key的监视。
Redis事务没有隔离级别的概念:
批量操作在发送 EXEC 命令前被放入队列缓存,并不会被实际执行
Redis不保证原子性:
原子性:数据库中的某个事务A中要更新t1表、t2表的某条记录,当事务提交,t1、t2两个表都被更新,若其中一个表操作失败,事务将回滚
Redis中,单条命令是原子性执行的,但事务不保证原子性,且没有回滚。事务中任意命令执行失败,其余的命令仍会被执行。
redis主从架构
单机的 Redis,能够承载的 QPS 大概就在上万到几万不等。对于缓存来说,一般都是用来支撑读高并发的。因此架构做成主从(master-slave)架构,一主多从,主负责写,并且将数据复制到其它的 slave 节点,从节点负责读。所有的读请求全部走从节点。这样也可以很轻松实现水平扩容,支撑读高并发。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o7s5BxgH-1649155408079)(pic/redis主从架构.png)]
redis replication -> 主从架构 -> 读写分离 -> 水平扩容支撑读高并发
Redis 主从复制
复制是高可用Redis的基础,哨兵在复制基础上实现高可用的。
- 复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
- 缺陷:故障恢复无法自动化;写操作无法负载均衡;存储能力受到单机的限制。
主从复制:主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,但是数据是存储在一台服务器上,如果这台服务器出现故障,比如硬盘坏了,也会导致数据丢失
为了避免单点故障,需要将数据复制多份部署在多台不同的服务器上,即使有一台服务器出现故障其他服务器依然可以继续提供服务。
redis2.8以前,从服务器断线重连,为了让从服务器补足一小部分缺失的数据,却让主从服务器重新执行一次SYNC命令,非常低效。
复制:
-
同步操作:将从服务器的数据库状态跟新至主服务器当前所处的数据库状态
当客户端向从服务器发送SALVEOF命令,要求从服务器复制主服务器,从服务器先执行同步操作,同步操作通过向主服务器发送PSYNC命令来完成:
-
命令传播:用于在主服务器的数据库状态被修改,导致主从服务器的数据库状态出现不一致,让主服务器的数据库重新回到一致状态。
主服务器命令传播时,不仅将写命令发给所有服务器,还会入队到复制积压缓冲区
全量复制:用于初次复制情况
-
当启动一个 slave node 的时候,它会发送一个
PSYNC命令给 master node。如果这是 slave node 初次连接到 master node,那么会触发一次full resynchronization全量复制。此时 master 会启动一个后台线程,开始执行BGSAVE命令生成一份RDB快照文件,同时还会将从客户端 client 新收到的所有写命令缓存在内存中。 -
RDB文件生成完毕后, master 会将这个RDB发送给 slave,slave 会先写入本地磁盘,然后再从本地磁盘加载到内存中, -
接着 master 会将内存中缓存的写命令发送到 slave,slave 执行这些命令,奖数据库的状态更新至主服务器状态
slave node 如果跟 master node 有网络故障,断开了连接,会自动重连,连接之后 master node 仅会复制给 slave 部分缺少的数据。
增量复制:处理断线后复制情况,将服务器缺少的写命令发送给服务器执行就可以
-
从服务器重新连上主服务器时,从服务器通过PSYNC命令将复制积压缓冲区命令发给主服务器
- 如果复制偏移量之后的数据在复制积压缓冲区,执行增量复制
- 如果复制偏移量之后的数据不在复制积压缓冲区,执行全量复制
-
初次复制主服务器会将自己运行ID发给从服务器,从服务器断线重连,从服务器保存的运行ID和连接的主服务器ID相同,则主服务器可以执行增量复制。否则,执行全量复制
心跳:主从有长连接心跳,主节点默认每10S向从节点发ping命令,repl-ping-slave-period控制发送频率.
主从的缺点
-
主从复制,若主节点出现问题,则不能提供服务,需要人工修改配置将从变主
-
主从复制主节点的写能力单机,能力有限
-
单机节点的存储能力也有限
主从故障如何故障转移
-
主节点(master)故障,从节点slave-1端执行 slaveof no one后变成新主节点;
-
其它的节点成为新主节点的从节点,并从新节点复制数据;
-
需要人工干预,无法实现高可用
redis哨兵
原理:当主节点出现故障时,由Redis Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。
- 监控:Sentinel不断的检查主服务和从服务器是否按照预期正常工作。
- 提醒:被监控的Redis出现问题时,Sentinel会通知管理员或其他应用程序。
- 自动故障转移:监控的主Redis不能正常工作,Sentinel会开始进行故障迁移操作。将一个从服务器升级新的主服务器。 让其他从服务器挂到新的主服务器。同时向客户端提供新的主服务器地址。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VGkjW692-1649155408080)(pic/哨兵机制.png)]
其实整个过程只需要一个哨兵节点来完成,首先使用Raft算法(选举算法)实现选举机制,选出一个哨兵节点(来当主人master)完成转移和通知
-
每个哨兵节点每10秒会向主节点发送info命令,通过返回额INFO命令可以获取:
- 主服务器本身的信息
- 主服务器属下的从服务器信息。哨兵无须用户提供从服务器的地址信息,就可以自动发现从服务器
-
发现主服务器下的从服务器时,哨兵会创建连接到从服务器的命令连接和订阅连接
- 每个哨兵节点每10秒向从节点发送info命令,获取从节点的信息
-
每个哨兵节点每隔2秒会向被监视的主服务器和从服务器发送主节点的信息及当前哨兵节点的信息,同时每个哨兵节点也会订阅连接,来了解其它哨兵节点的信息及对主节点的判断
-
每隔1秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次ping命令做一次心跳检测,这个也是哨兵用来判断节点是否正常的重要依据
客观下线:当哨兵判断一个主服务器下线后,为确定是否真下线,会通过指令sentinel is-masterdown-by-addr寻求其它哨兵节点对主节点的判断,当超过quorum(选举)个数,哨兵将主服务器实例结构flags属性的SSRT_O_DOWN标识打开,此时主节点客观下线
选取领头哨兵:
当主服务器客观下线,会选取一个领头哨兵执行故障转移操作,领头哨兵选取方法:通过sentinel is-master-down-by-addr命令都希望成为领导者,只有一个sentinel节点完成故障转移
- 每个做主观下线的Sentinel节点向其他Sentinel节点发送命令,要求将它设置为领导者.
- 收到命令的Sentinel节点如果没有同意通过其他Sentinel节点发送命令,那么将同意该请求,否则拒绝
- 如果该Sentinel节点发现自己的票数已经超过Sentinel集合半数且超过quorum,那么它将成为领导者
- 如果此过程有没有Sentinel节点成为了领导者,那么将等待一段时间重新进行选举
如果是哨兵偶数的话有可能在每个配置纪元中会有两个节点拿到相同的票数,从而不断进入新的配置纪元
故障转移
选出领头哨兵后,对已下线的主服务器进行故障转移:
-
让已下线的主服务器下的所有从服务器中选出一个从服务器做主服务器
领头哨兵将所有从服务器保存在一个列表里,一项一项g过滤:
- 删除处于下线或断线的从服务器
- 删除最近5秒没有回复过领头哨兵的INFO命令的从服务器
- 删除已下线主服务器连接断开down-after-milliseconds*10毫秒的从服务器,剩余的从服务器教新的
- 之后,会根据从服务器的优先级排序,选出优先级最高的从服务器。
- 优先级相同话,按从服务器的复制偏移量,选出偏移量最大的
- 优先级,复制偏移量相同,选运行ID最小的
-
让已下线的主服务器下的所有从服务器改为复制新的主服务器
-
将已下线主服务器设置为新的竹服务器的从服务器,当这个旧的主服务器重新上线,塔旧会成为新的主服务器的从服务器
由Sentinel节点定期监控发现主节点是否出现了故障
- sentinel会向master发送心跳PING来确认master是否存活,如果master在“一定时间范围”内不回应PONG 或者是回复了一个错误消息,那么这个sentinel会主观地(单方面地)认为这个master已经不可用了
redis哨兵的作用
- 监控主数据库和从数据库是否正常运行
- 主数据库出现故障时,可以自动将从数据库转换为主数据库,实现自动切换。
redis集群
https://github.com/doocs/advanced-java/blob/main/docs/high-concurrency/redis-cluster.md
-
如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个 G,单机就足够了,可以使用 replication,一个 master 多个 slaves,要几个 slave 跟你要求的读吞吐量有关,然后自己搭建一个 sentinel 集群去保证 Redis 主从架构的高可用性
-
Redis cluster,主要是针对海量数据+高并发+高可用的场景
集群(Redis Cluster)时redis3.0开始引入的分布式解决方案,并提供复制和故障转移功能
当数据量过大到一台服务器存放不下的情况时,主从模式或sentinel模式就不能满足需求了,这时候需要对存储的数据进行分片,将数据存储到多个Redis实例中,cluster模式的出现就是为了解决单机Redis容量有限的问题
Redis cluster 介绍
- 自动将数据进行分片,每个 master 上放一部分数据
- 提供内置的高可用支持,部分 master 不可用时,还是可以继续工作的
数据库:集群节点只是用0号数据库保存节点键值对一级键值对过期时间
slot(槽)
Redis 3.0版本开始正式提供。Redis Cluster并没有使用一致性hash,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的节点会将查询请求发送到正确的节点上执行
方案说明
- 通过哈希的方式,将数据分片,每个节点均分存储一定哈希槽(哈希值)区间的数据,默认分配了16384 个槽位
- 每份数据分片会存储在多个互为主从的多节点上
- 数据写入先写主节点,再同步到从节点(支持配置为阻塞同步)
- 同一分片多个节点间的数据不保持一致性
- 读取数据时,当客户端操作的key没有分配在该节点上时,redis会返回转向指令,指向正确的节点
- 扩容时时需要需要把旧节点的数据迁移一部分到新节点
- 在 redis cluster 架构下,每个 redis 要放开两个端口号,比如一个是 6379,另外一个就是 加1w 的端口号,比如 16379。
- 16379 端口号是用来进行节点间通信的,也就是 cluster bus 的东西,cluster bus 的通信,用来进行故障检测、配置更新、故障转移授权。cluster bus 用了另外一种二进制的协议,gossip 协议,用于节点间进行高效的数据交换,占用更少的网络带宽和处理时间
对数据库的16384个槽都指派后,集群就会上线,客户端可以向集群发送命令,接受命令的节点会计算出命令要处理的数据库键属于哪个槽,并检测这个槽是否指派给自己
- 键指派给自己,节点直接执行名
- 没有,节点会向客户端返回一个MOved错误。指引客户端转向正确的节点,并再次发送之前执行的命令
计算键属于哪个槽:
- CRC16(key) & 16383
判断节点是否由当前节点负责:
- 计算出键的槽i后,节点会检查自己的clusterState.slots数组的项i,判断键所造槽是否由自己负责。如果值等于clusterState.myself
集群的作用
可以归纳为两点:
-
数据分区:数据分区(或称数据分片)是集群最核心的功能。
集群将数据分散到多个节点,一方面突破了Redis单机内存大小的限制,存储容量大大增加;另一方面每个主节点都可以对外提供读服务和写服务,大大提高了集群的响应能力
Redis单机内存大小受限问题,在介绍持久化和主从复制时都有提及;例如,如果单机内存太大,bgsave和bgrewriteaof的fork操作可能导致主进程阻塞,主从环境下主机切换时可能导致从节点长时间无法提供服务,全量复制阶段主节点的复制缓冲区可能溢出……。
-
高可用:集群支持主从复制和主节点的自动故障转移(与哨兵类似);当任一节点发生故障时,集群仍然可以对外提供服务。
集群节点之间的通信
集群元数据的维护有两种方式:集中式、Gossip 协议。Redis cluster 节点间采用 gossip 协议进行通信。
集中式是将集群元数据(节点信息、故障等等)几种存储在某个节点上。集中式元数据集中存储的一个典型代表,就是大数据领域的 storm 。它是分布式的大数据实时计算引擎,是集中式的元数据存储的结构,底层基于 zookeeper(分布式协调的中间件)对所有元数据进行存储维护
gossip 协议
Redis 采用 gossip 协议,所有节点都持有一份数据,不同的节点如果出现了数据的变更,就不断将数据发送给其它的节点,让其它节点也进行数据的变更。
常用的Gossip消息有ping消息、pong消息、meet消息、fail消息
-
meet消息:某个节点发送 meet 给新加入的节点,让新节点加入集群中,然后新节点就会开始与其它节点进行通信。
-
ping消息:集群内交换最频繁的消息,集群内每个节点每秒向其它节点发ping消息,用于检测节点是在在线和状态信息,ping消息发送封装自身节点和其他节点的状态数据;
-
pong消息,当接收到ping meet消息时,作为响应消息返回给发送方,用来确认正常通信,包含自己的状态和其它信息,也用于信息广播和更新
-
fail消息:当节点判定集群内的另一节点下线时,会向集群内广播一个fail消息
判断节点宕机
如果一个节点认为另外一个节点宕机,那么就是 pfail ,主观宕机。如果多个节点都认为另外一个节点宕机了,那么就是 fail ,客观宕机
从节点过滤
对宕机的 master node,从其所有的 slave node 中,选择一个切换成 master node。
检查每个 slave node 与 master node 断开连接的时间,如果超过了 cluster-node-timeout * cluster-slave-validity-factor ,那么就没有资格切换成 master 。
从节点选举
每个从节点,都根据自己对 master 复制数据的 offset,来设置一个选举时间,offset 越大(复制数据越多)的从节点,选举时间越靠前,优先进行选举。
所有的 master node 开始 slave 选举投票,给要进行选举的 slave 进行投票,如果大部分 master node (N/2 + 1) 都投票给了某个从节点,那么选举通过,那个从节点可以切换成 master。
从节点执行主备切换,从节点切换为主节点。
分布式寻址算法
hash 算法
(大量缓存重建)
来了一个 key,首先计算 hash 值,然后对节点数取模。然后打在不同的 master 节点上。一旦某一个 master 节点宕机,所有请求过来,都会基于最新的剩余 master 节点数去取模,尝试去取数据。这会导致大部分的请求过来,全部无法拿到有效的缓存,导致大量的流量涌入数据库。
一致性 hash 算法
- 将机器映射到环中
- 将数据映射到环中
- 添加节点
- 删除节点
一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡)
- 一致性 hash 算法将整个 hash 值空间组织成一个虚拟的圆环,整个空间按顺时针方向组织,下一步将各个 master 节点(使用服务器的 ip 或主机名)进行 hash。这样就能确定每个节点在其哈希环上的位置。
- 相同的哈希函数计算需要存储数据的哈希值,要将这些数据映射到环中,从此位置沿环顺时针“行走”,遇到的第一个 master 节点就是 key 所在位置。
- 在一致性哈希算法中,如果一个节点挂了,受影响的数据仅仅是此节点到环空间前一个节点(沿着逆时针方向行走遇到的第一个节点)之间的数据,其它不受影响。增加一个节点也同理。
- 如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响
一致性哈希算法缺点:
-
随机分布节方式使得难均匀的分布哈希值域;尤其在动态增加节点后,即使原先的分布均匀也很难保证继续均匀。
-
当一个节异常时,该节点的压力全部转移到相邻的一个节点,当加入一个新节点时,只能为一个相邻节点分摊压力。
为了解决这种热点问题,一致性 hash 算法引入了虚拟节点机制,即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
扩展能力提升
前面我们分析过,普通哈希算法当需要扩容增加服务节点的时候,会导致原油哈希映射大面积失效。现在,我们来看下一致性哈希是如何解决这个问题的。
如下图所示,当缓存服务集群要新增一个节点node3时,受影响的只有 key3 对应的数据 value3,此时只需把 value3 由原来的节点 node0 迁移到新增节点 node3 即可,其余节点存储的数据保持不动。
容错能力提升
普通哈希算法当某一服务节点宕机下线,也会导致原来哈希映射的大面积失效,失效的映射触发数据迁移影响缓存服务性能,容错能力不足。一起来看下一致性哈希是如何提升容错能力的。
如下图所示,假设 node2 节点宕机下线,则原来存储于 node2 的数据 value2 和 value5 ,只需按顺时针方向选择新的存储节点 node0 存放即可,不会对其他节点数据产生影响。一致性哈希能把节点宕机造成的影响控制在顺时针相邻节点之间,避免对整个集群造成影响。
存在的问题
上面展示了一致性哈希如何解决普通哈希的扩展和容错问题,原理比较简单,在理想情况下可以良好运行,但在实际使用中还有一些实际问题需要考虑,下面具体分析。
数据倾斜
试想一下若缓存集群内的服务节点比较少,就像我们例子中的三个节点,而哈希环的空间又有很大(一般是 0 ~ 2^32),这会导致什么问题呢?
可能的一种情况是,较少的服务节点哈希值聚集在一起,比如下图所示这种情况 node0 、node1、node2 聚集在一起,缓存数据的 key 哈希都映射到 node2 的顺时针方向,数据按顺时针寻找存储节点就导致全都存储到 node0 上去,给单个节点很大的压力!这种情况称为数据倾斜。
数据倾斜和节点宕机都可能会导致缓存雪崩。
-
数据倾斜导致所有缓存数据都打到 node0 上面,有可能会导致 node0 不堪重负被压垮了,node0 宕机,数据又都打到 node1 上面把 node1 也打垮了,node1 也被打趴传递给 node2,这时候故障就像像雪崩时滚雪球一样越滚越大。
-
还有一种情况是节点由于各种原因宕机下线。比如下图所示的节点 node2 下线导致原本在node2 的数据压到 node0 , 在数据量特别大的情况下也可能导致节点雪崩,具体过程就像刚才的分析一样。
总之,连锁反应导致的整个缓存集群不可用,就称为节点雪崩。
解决上述两个棘手的问题呢?可以通过「虚拟节点」的方式解决。
- 所谓虚拟节点,就是对原来单一的物理节点在哈希环上虚拟出几个它的分身节点,这些分身节点称为「虚拟节点」。打到分身节点上的数据实际上也是映射到分身对应的物理节点上,这样一个物理节点可以通过虚拟节点的方式均匀分散在哈希环的各个部分,解决了数据倾斜问题。
- 由于虚拟节点分散在哈希环各个部分,当某个节点宕机下线,他所存储的数据会被均匀分配给其他各个节点,避免对单一节点突发压力导致的节点雪崩问题。
Redis cluster 的 hash slot 算法
-
Redis cluster 有固定的
16384个 hash slot,对每个key计算CRC16值,然后对16384取模,可以获取 key 对应的 hash slot。 -
Redis cluster 中每个 master 都会持有部分 slot,比如有 3 个 master,那么可能每个 master 持有 5000 多个 hash slot。hash slot 让 node 的增加和移除很简单,增加一个 master,就将其他 master 的 hash slot 移动部分过去,减少一个 master,就将它的 hash slot 移动到其他 master 上去。移动 hash slot 的成本是非常低的。客户端的 api,可以对指定的数据,让他们走同一个 hash slot,通过
hash tag来实现。 -
任何一台机器宕机,另外两个节点,不影响的。因为 key 找的是 hash slot,不是机器。
redis集群优缺点:
优点
-
无中心架构,支持动态扩容,对业务透明
-
具备Sentinel的监控和自动Failover(故障转移)能力
-
客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
-
高性能,客户端直连redis服务,免去了proxy代理的损耗
-
运维也很复杂,数据迁移需要人工干预
-
只能使用0号数据库
-
不支持批量操作(pipeline管道操作)
-
分布式逻辑和存储模块耦合等
为什么要做Redis分区
分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
Redis集群会有写操作丢失吗?
Redis并不能保证数据的强一致性,这意味这在实际中集群在特定的条件下可能会丢失写操作。
有哪些Redis分区实现方案?
- 客户端分区就是在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。大多数客户端已经实现了客户端分区。
- 代理分区 意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
- 查询路由(Query routing) 的意思是客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。
基于客户端分配
Redis Sharding是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。Java redis客户端驱动jedis,支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool
优点
- 优势在于非常简单,服务端的Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强
缺点
- 由于sharding处理放到客户端,规模进一步扩大时给运维带来挑战。
- 客户端sharding不支持动态增删节点。服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整。连接不能共享,当应用规模增大时,资源浪费制约优化
基于代理服务器分片
客户端发送请求到一个代理组件,代理解析客户端的数据,并将请求转发至正确的节点,最后将结果回复给客户端
特征:
- 透明接入,业务程序不用关心后端Redis实例,切换成本低
- Proxy 的逻辑和存储的逻辑是隔离的
- 代理层多了一次转发,性能有所损耗
业界开源方案
- Twtter开源的Twemproxy
- 豌豆荚开源的Codis
Redis分区有什么缺点?
- 涉及多个key的操作通常不会被支持。例如你不能对两个集合求交集,因为他们可能被存储到不同的Redis实例(实际上这种情况也有办法,但是不能直接使用交集指令)。
同时操作多个key,则不能使用Redis事务. - 分区使用的粒度是key,不能使用一个非常长的排序key存储一个数据集(The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set)
- 当使用分区的时候,数据处理会非常复杂,例如为了备份你必须从不同的Redis实例和主机同时收集RDB / AOF文件。
- 分区时动态扩容或缩容可能非常复杂。Redis集群在运行时增加或者删除Redis节点,能做到最大程度对用户透明地数据再平衡,但其他一些客户端分区或者代理分区方法则不支持这种特性。然而,有一种预分片的技术也可以较好的解决这个问题。
Redis实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系
分布式锁需要具备哪些条件
- 互斥性:在任意一个时刻,只有一个客户端持有锁。
- 无死锁:即便持有锁的客户端崩溃或者其他意外事件,锁仍然可以被获取。
- 容错:只要大部分Redis节点都活着,客户端就可以获取和释放锁
何为分布式锁?
- 当在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
分布式锁的条件:
- 可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
- 这把锁要是一把可重入锁(避免死锁)
- 这把锁最好是一把阻塞锁
- 这把锁最好是一把公平锁
- 有高可用的获取锁和释放锁功能
- 获取锁和释放锁的性能要好
Redis中可以使用SETNX命令实现分布式锁。返回值:设置成功,返回 1 。设置失败,返回 0 。
- 当且仅当 key 不存在,将 key 的值设为 value。
- 若给定的 key 已经存在,则 SETNX 不做任何动作
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
expire: EXPIRE key seconds
为给定 key 设置生存时间,当 key 过期时(生存时间为 0 ),它会被自动删除
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AsrAGDi8-1649155408082)(J:\面试\2021.2.16\pic\v2-0355cb24df218aa75384bec1af5a98af_720w.jpg)]
实现分布式锁问题
如果出现了这么一个问题:如果setnx是成功的,但是expire设置失败,那么后面如果出现了释放锁失败的问题,那么这个锁永远也不会被得到,业务将被锁死?
解决的办法:使用set的命令,同时设置锁和过期时间
set参数:
set key value [EX seconds] [PX milliseconds] [NX|XX]
EX seconds:设置失效时长,单位秒
PX milliseconds:设置失效时长,单位毫秒
NX:key不存在时设置value,成功返回OK,失败返回(nil)
XX:key存在时设置value,成功返回OK,失败返回(nil)
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个“合理”的过期时间释放锁,使用DEL命令将锁数据删除
单机Redis实现分布式锁
获取锁
获取锁的过程很简单,客户端向Redis发送命令:
SET resource_name my_random_value NX PX 30000
my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。PX 30000表示这个锁有一个30秒的自动过期时间。
释放锁
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
之前获取锁的时候生成的my_random_value 作为参数传到Lua脚本里面,作为:ARGV[1],而 resource_name 作为KEYS[1]。Lua脚本可以保证操作的原子性。
关于单点Redis实现分布式锁的讨论
- 网络上有文章说用如下命令获取锁:
SETNX resource_name my_random_value
EXPIRE resource_name 30
由于这两个命令不是原子的。如果客户端在执行完SETNX后crash了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁,其他的客户端就永远获取不到这个锁了。
- 为什么
my_random_value要设置成随机值?
保证了一个客户端释放的锁是自己持有的那个锁。如若不然,可能出现锁不安全的情况。
客户端1获取锁成功。
客户端1在某个操作上阻塞了很长时间。
过期时间到了,锁自动释放了。
客户端2获取到了对应同一个资源的锁。
客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
- 用 SETNX获取锁
Redis集群实现分布式锁
上面的讨论中我们有一个非常重要的假设:Redis是单点的。如果Redis是集群模式,我们考虑如下场景:
客户端1从Master获取了锁。
Master宕机了,存储锁的key还没有来得及同步到Slave上。
Slave升级为Master。
客户端2从新的Master获取到了对应同一个资源的锁。
客户端1和客户端2同时持有了同一个资源的锁,锁不再具有安全性。
就此问题,Redis作者antirez写了RedLock算法来解决这种问题。
RedLock获取锁
- 获取当前时间。
- 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串
my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。 - 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的单机Redis Lua脚本释放锁的方法)。
RedLock释放锁
客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
什么是 RedLock
Redis 官方站提出了一种权威的基于 Redis 实现分布式锁的方式名叫 Redlock,此种方式比原先的单节点的方法更安全。它可以保证以下特性:
- 安全特性:互斥访问,即永远只有一个 client 能拿到锁
- 避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区
- 容错性:只要大部分 Redis 节点存活就可以正常提供服务
如何解决 Redis 的并发竞争 Key 问题
Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
在实践中,当然是从以可靠性为主。所以首推Zookeeper。
参考:https://www.jianshu.com/p/8bddd381de06
缓存雪崩
缓存雪崩:当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力。
1、避免缓存集中失效,
2、增加互斥锁,控制数据库请求,重建缓存。
3、提高缓存的HA,如:redis集群。
- 缓存数据的过期时间设置随机(不同的key设置不同的超时时间),防止同一时间大量数据过期现象发生。
- 一般并发量不是特别多的时候,使用最多的解决方案是加锁排队。增加互斥锁,控制数据库请求,重建缓存。
- 给每一个缓存数据增加相应的缓存标记,记录缓存的是否失效,如果缓存标记失效,则更新数据缓存。
缓存穿透
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。另外也有一个更为简单粗暴的方法(我们采用的就是这种),如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿
key对应的数据存在,但在redis中过期(但数据库中有的数据),此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端数据库加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端数据库压垮。
解决方案
-
设置热点数据永远不过期。
-
加互斥锁,互斥锁
就是在缓存失效的时候(判断拿出来的值为空),不是立即去load数据库,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) {
//代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) {
//代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else {
//这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key。
缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
解决方案
-
直接写个缓存刷新页面,上线时手工操作一下;
-
数据量不大,可以在项目启动的时候自动进行加载;
-
定时刷新缓存;
缓存降级
当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,仍然需要保证服务还是可用的,即使是有损服务。系统可以根据一些关键数据进行自动降级,也可以配置开关实现人工降级。
缓存降级的最终目的是保证核心服务可用,即使是有损的。而且有些服务是无法降级的(如加入购物车、结算)。
在进行降级之前要对系统进行梳理,看看系统是不是可以丢卒保帅;从而梳理出哪些必须誓死保护,哪些可降级;比如可以参考日志级别设置预案:
-
一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
-
警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
-
错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
-
严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
服务降级的目的,是为了防止Redis服务故障,导致数据库跟着一起发生雪崩问题。因此,对于不重要的缓存数据,可以采取服务降级策略,例如一个比较常见的做法就是,Redis出现问题,不去数据库查询,而是直接返回默认值给用户。
热点数据和冷数据
热点数据,缓存才有价值
对于冷数据而言,大部分数据可能还没有再次访问到就已经被挤出内存,不仅占用内存,而且价值不大。频繁修改的数据,看情况考虑使用缓存
对于热点数据,比如我们的某IM产品,生日祝福模块,当天的寿星列表,缓存以后可能读取数十万次。再举个例子,某导航产品,我们将导航信息,缓存以后可能读取数百万次。
数据更新前至少读取两次,缓存才有意义。这个是最基本的策略,如果缓存还没有起作用就失效了,那就没有太大价值了。
那存不存在,修改频率很高,但是又不得不考虑缓存的场景呢?有!比如,这个读取接口对数据库的压力很大,但是又是热点数据,这个时候就需要考虑通过缓存手段,减少数据库的压力,比如我们的某助手产品的,点赞数,收藏数,分享数等是非常典型的热点数据,但是又不断变化,此时就需要将数据同步保存到Redis缓存,减少数据库压力
布隆过滤器
https://www.cnblogs.com/liyulong1982/p/6013002.html
bloomfilter就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景就是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小
算法:
1. 首先需要k个hash函数,每个函数可以把key散列成为1个整数
2. 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中。
优点:不需要存储key,节省空间
缺点:
1. 算法判断key在集合中时,有一定的概率key其实不在集合中
2. 无法删除
典型的应用场景:
-
某些存储系统的设计中,会存在空查询缺陷:当查询一个不存在的key时,需要访问慢设备,导致效率低下。
-
比如一个前端页面的缓存系统,可能这样设计:先查询某个页面在本地是否存在,如果存在就直接返回,如果不存在,就从后端获取。但是当频繁从缓存系统查询一个页面时,缓存系统将会频繁请求后端,把压力导入后端。
MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
-
首先缓存预热,将我们认为是热点的数据放在redis中,然后根据请求更新数据,redis内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
如何保证缓存与数据库双写时的数据一致性?
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
还有一种方式就是可能会暂时产生不一致的情况,但是发生的几率特别小,就是先更新数据库,然后再删除缓存。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XJBS5JWO-1649155408084)(pic/数据一致性.png)]
Redis常见问题及解决方案
- Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
- 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
- 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
- 尽量避免在压力很大的主库上增加从库
- 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变
参考:https://www.cnblogs.com/kismetv/p/8654978.html
数据库键总是一个字符串对象
数据库键的值可以是字符串对象、列表对象、哈希对象、集合对象、有序集合对象
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足
如果排行榜的设计按一个维度比如金币数量,那只需把其数量取反作为分数score即可。取反是因为zset默认从小到大排序。
如果排行榜的设计按两个维度比如金币数量和用时。由于score是一个可以double类型的参数,设计的时候可以把用时作为小数,用一天的总毫秒数减去花费毫秒数作为小数部分,然后当做字符串拼接起来,然后取反作为score.
在分布式网络中如何保证数据一致性。
拜占庭将军问题
由于地域宽广,守卫边境的多个将军(系统中的多个节点)需要通过信使来传递消息,达成某些一致的决定。但由于将军中可能存在叛徒(系统中节点出错),这些叛徒将努力向不同的将军发送不同的消息,试图会干扰一致性的达成
Leslie Lamport 证明,当叛变者不超过1/3时,存在有效的算法,不论叛变者如何折腾,忠诚的将军们总能达成一致的结果。如果叛变者过多,则无法保证一定能达到一致性。
对于拜占庭将军问题分两种情况:
-
针对非拜占庭错误的情况,一般包括 Paxos、Raft 及其变种。
分布式数据库设计一般都是基于paxos或raft算法。
-
对于要能容忍拜占庭错误的情况,一般包括 PBFT 系列、PoW 系列算法等。
从概率角度,PBFT 系列算法是确定的,一旦达成共识就不可逆转;而 PoW 系列算法则是不确定的,随着时间推移,被推翻的概率越来越小。
paxos
Paxos用于解决分布式系统中一致性问题。分布式一致性算法(Consensus Algorithm)是一个分布式计算领域的基础性问题,其最基本的功能是为了在多个进程之间对某个(某些)值达成一致(强一致);简单来说就是确定一个值,一旦被写入就不可改变。paxos用来实现多节点写入来完成一件事情,例如mysql主从也是一种方案,但这种方案有个致命的缺陷,如果主库挂了会直接影响业务,导致业务不可写,从而影响整个系统的高可用性。paxos协议是只是一个协议,不是具体的一套解决方案。目的是解决多节点写入问题。
paxos协议用来解决的问题可以用一句话来简化:
将所有节点都写入同一个值,且被写入后不再更改。
高可用
高可用HA**(**High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
往往是通过“自动故障转移”来实现系统的高可用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xSjggZEh-1649155755854)(./pic/常见的互联网分层架构.webp)]
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据**-**缓存层:缓存加速访问存储
(6)数据**-**数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余****+****自动故障转移来综合实现的。
-
【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余来实现的。以nginx为例:有两台nginx,一台对线上提供服务,另一台冗余以保证高可用,常见的实践是keepalived存活探测,相同virtual IP提供服务。
自动故障转移:当nginx挂了的时候,keepalived能够探测到,会自动的进行故障转移,将流量自动迁移到shadow-nginx,由于使用的是相同的virtual IP,这个切换过程对调用方是透明的
高并发、高可用三大法宝:限流、降级、缓存,关于缓存,大家应该接触的最多,互联网业务特点就是读多写少,那么就非常适合使用缓存了
目的:
-
通过对并发访问和请求进行限速或者一个时间窗口内的请求进行限速来保护系统的可用性,一旦达到限制速率就可以拒绝服务(友好定向到错误页或告知资源没有了),排队或者等待(比如秒杀,评论,下单),降级(返回默认数据)。
-
通过压测的手段找到每个系统的处理峰值,然后通过设定峰值阈值,来防止当系统过载时,通过拒绝处理过载的请求来保障系统 可用性,同时也应该根据系统的吞吐量,响应时间,可用率来动态调整限流阈值。
分类:
- 限制总并发数—数据库连接池,线程池
- 限制瞬时并发数—nginx的limit_conn模块,用来限制瞬时并发连接数
- 限制时间窗口内的平均速率—guava的RateLimiter,nginx的limit_req模块,限制每秒平均速率
- 其他—限制远程接口调用速率,限制MQ消费速率,另外,还可以根据网络连接数,网络流量,CPU或内存负载等来限流。
算法:
- 滑动窗口协议—改善吞吐量的技术
- 漏桶—强制限制数据的传输速率,限制的流出速率
- 令牌桶—(控制(流入)速率类型的限流算法)系统以恒定的速度往桶中放入令牌,如果请求需要被处理,则需要先从桶中获取一个令牌,当桶中没有令牌可取,则拒绝服务。当平时处理速率小于桶中令牌的速率,那么在突发流量时桶内有堆积可以有效预防。
令牌桶和漏桶的对比:
- 令牌桶是按照固定的速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数为0,则拒绝新的请求
- 漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入请求数累计到漏桶容量时,则新的请求被拒绝。
- 令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,一次拿3个令牌,4个令牌),并允许一定程度并发流量
- 漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次是2),从而平滑的解决了突发流入速率
- 两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
计数器(***)—通过控制时间段内的请求次数,限制总并发数,比如数据库连接池大小,线程池大小,秒杀并发数都是计数器的用法。只要全局总请求数或者一段时间内的请求数达到设定阈值,则进行限流。对比上面的速率限流,该算法是总数量限流。
策略:
-
Nginx接入层限流
-
- 对某个key对应的总的网络连接数进行限流,可以按照一定的规则如账号,IP,系统调用逻辑等在Nginx层面做限流—连接数限流模块:limit_conn
- 对某个key对应的请求的平均速率进行限流,两种:平滑模式和允许突发模式—请求限流模块:limit_req
-
应用级限流
-
- 限流总并发/连接/请求数—设定合适的阈值(tomcat,redis,mysql等都有类似配置)
- 限流总资源数—数据库连接池,线程池
- 限流接口的总并发/请求数—适用于可降级的业务场景,可以让用户友好接受。可以使用计数器方式实现。
- 限流接口的时间窗口请求数—使用计数器方式
- 平滑限流接口请求数(应对突发流量)—令牌桶/漏桶
理解高并发高可用—限流
高并发的实践方案有哪些?
通用的设计方法主要是从「纵向」和「横向」两个维度出发,俗称高并发处理的两板斧:纵向扩展和横向扩展。
-
纵向扩展
-
提升单机的硬件性能:通过增加内存、CPU核数、存储容量、或者将磁盘升级成SSD等堆硬件的方式来提升。
-
提升单机的软件性能:使用缓存减少IO次数,使用并发或者异步的方式增加吞吐量
-
-
横向扩展
单机性能总会存在极限,所以最终还需要引入横向扩展,通过集群部署以进一步提高并发处理能力,又包括以下2个方向:
-
做好分层架构:因为高并发系统往往业务复杂,通过分层处理可以简化复杂问题,更容易做到横向扩展。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9CI639FJ-1649155755855)(./pic/分层架构.png)]
当然真实的高并发系统架构会在此基础上进一步完善。比如会做动静分离并引入CDN,反向代理层可以是LVS+Nginx,Web层可以是统一的API网关,业务服务层可进一步按垂直业务做微服务化,存储层可以是各种异构数据库
-
各层进行水平扩展:
无状态水平扩容,有状态做分片路由。业务集群通常能设计成无状态的,而数据库和缓存往往是有状态的,因此需要设计分区键做好存储分片,当然也可以通过主从同步、读写分离的方案提升读性能。
-
高性能
-
1、集群部署,通过负载均衡减轻单机压力。
-
2、多级缓存,包括静态数据使用CDN、本地缓存、分布式缓存等,以及对缓存场景中的热点key、缓存穿透、缓存并发、数据一致性等问题的处理。
-
3、分库分表和索引优化,以及借助搜索引擎解决复杂查询问题。
-
4、考虑NoSQL数据库的使用,比如HBase、TiDB等,但是团队必须熟悉这些组件,且有较强的运维能力。
-
5、异步化,将次要流程通过多线程、MQ、甚至延时任务进行异步处理。
-
6、限流,需要先考虑业务是否允许限流(比如秒杀场景是允许的),包括前端限流、Nginx接入层的限流、服务端的限流。
-
7、对流量进行削峰填谷,通过MQ承接流量。
-
8、并发处理,通过多线程将串行逻辑并行化。
-
9、预计算,比如抢红包场景,可以提前计算好红包金额缓存起来,发红包时直接使用即可。
-
10、缓存预热,通过异步任务提前预热数据到本地缓存或者分布式缓存中。
-
11、减少IO次数,比如数据库和缓存的批量读写、RPC的批量接口支持、或者通过冗余数据的方式干掉RPC调用。
-
12、减少IO时的数据包大小,包括采用轻量级的通信协议、合适的数据结构、去掉接口中的多余字段、减少缓存key的大小、压缩缓存value等。
-
13、程序逻辑优化,比如将大概率阻断执行流程的判断逻辑前置、For循环的计算逻辑优化,或者采用更高效的算法。
-
14、各种池化技术的使用和池大小的设置,包括HTTP请求池、线程池(考虑CPU密集型还是IO密集型设置核心参数)、数据库和Redis连接池等。
-
15、JVM优化,包括新生代和老年代的大小、GC算法的选择等,尽可能减少GC频率和耗时。
-
16、锁选择,读多写少的场景用乐观锁,或者考虑通过分段锁的方式减少锁冲突。
上述方案无外乎从计算和 IO 两个维度考虑所有可能的优化点,需要有配套的监控系统实时了解当前的性能表现,并支撑你进行性能瓶颈分析,然后再遵循二八原则,抓主要矛盾进行优化。
高可用
-
1、对等节点的故障转移,Nginx和服务治理框架均支持一个节点失败后访问另一个节点。
-
2、非对等节点的故障转移,通过心跳检测并实施主备切换(比如redis的哨兵模式或者集群模式、MySQL的主从切换等)。
-
3、接口层面的超时设置、重试策略和幂等设计。
-
4、降级处理:保证核心服务,牺牲非核心服务,必要时进行熔断;或者核心链路出问题时,有备选链路。
-
5、限流处理:对超过系统处理能力的请求直接拒绝或者返回错误码。
-
6、MQ场景的消息可靠性保证,包括producer端的重试机制、broker侧的持久化、consumer端的ack机制等。
-
7、灰度发布,能支持按机器维度进行小流量部署,观察系统日志和业务指标,等运行平稳后再推全量。
-
8、监控报警:全方位的监控体系,包括最基础的CPU、内存、磁盘、网络的监控,以及Web服务器、JVM、数据库、各类中间件的监控和业务指标的监控。
-
9、灾备演练:类似当前的“混沌工程”,对系统进行一些破坏性手段,观察局部故障是否会引起可用性问题。
高可用的方案主要从冗余、取舍、系统运维3个方向考虑,同时需要有配套的值班机制和故障处理流程,当出现线上问题时,可及时跟进处理。
高扩展
-
1、合理的分层架构:比如上面谈到的互联网最常见的分层架构,另外还能进一步按照数据访问层、业务逻辑层对微服务做更细粒度的分层(但是需要评估性能,会存在网络多一跳的情况)。
-
2、存储层的拆分:按照业务维度做垂直拆分、按照数据特征维度进一步做水平拆分(分库分表)。
-
3、业务层的拆分:最常见的是按照业务维度拆(比如电商场景的商品服务、订单服务等),也可以按照核心接口和非核心接口拆,还可以按照请求源拆(比如To C和To B,APP和H5)。
分布式-CAP与ACID原则
1.1 定义
CAP是“Consistency,Avalilability, Partition Tolerance”的一种简称,其内容分别是:
(1)强一致性:即在分布式系统中的同一数据多副本情形下,对于数据的更新操作体现出的效果与只有单份数据是一样的。
(2)可用性:客户端在任何时刻对大规模数据系统的读/写操作都应该保证在限定延时内完成;
(3)分区容忍性:在大规模分布式数据系统中,网络分区现象,即分区间的机器无法进行网络通信的情况是必然发生的,所以系统应该能够在这种情况下仍然继续工作。
对于一个大规模分布式数据系统来说,CAP三要素是不可兼得的,同一系统至多只能实现其中的两个,而必须放宽第3个要素来保证其他两个要素被满足。一般在网络环境下,运行环境出现网络分区是不可避免的,所以系统必须具备分区容忍性§特性,所以在一般在这种场景下设计大规模分布式系统时,往往在AP和CP中进行权衡和选择。
1.2 为什么分布式环境下CAP三者不可兼得呢?
由于上面已经提到对于分布式环境下,P是必须要有的,所以该问题可以转化为:如果P已经得到,那么C和A是否可以兼得?可以分为两种情况来进行推演:
(1) 如果在这个分布式系统中数据没有副本,那么系统必然满足强一致性条件,因为只有独本数据,不会出现数据不一致的问题,此时C和P都具备。但是如果某些服务
器宕机,那必然会导致某些数据是不能访问的,那A就不符合了。
(2) 如果在这个分布式系统中数据是有副本的,那么如果某些服务器宕机时,系统还是可以提供服务的,即符合A。但是很难保证数据的一致性,因为宕机的时候,可能
有些数据还没有拷贝到副本中,那么副本中提供的数据就不准确了。
所以一般情况下,会根据具体业务来侧重于C或者A,对于一致性要求比较高的业务,那么对访问延迟时间要求就会低点;对于访问延时有要求的业务,那么对于数据一致性要求就会低点。一致性模型主要可以分为下面几类:强一致性、弱一致性、最终一致性、因果一致性、读你所写一致性、会话一致性、单调读一致性、以及单调写一致性,所以需要根据不同的业务选择合适的一致性模型。
-
ACID原则
ACID是关系型数据库系统采纳的原则,其代表的含义分别是: (1) 原子性(Atomicity):是指一个事务要么全部执行,要么完全不执行。 (2) 一致性(Consistency): 事务在开始和结束时,应该始终满足一致性约束。比如系统要求A+B=100,那么事务如果改变了A的数值,则B的数值也要相应修改来满足这样一致性要求;与CAP中的C代表的含义是不同的。 (3) 事务独立(Isolation):如果有多个事务同时执行,彼此之间不需要知晓对方的存在,而且执行时互不影响,事务之间需要序列化执行,有时间顺序。 (4) 持久性(Durability):事务的持久性是指事务运行成功以后,对系统状态的更新是永久的,不会无缘无故回滚撤销。
一个key的value较大时的情况
1.内存不均:单value较大时,可能会导致节点之间的内存使用不均匀,间接地影响key的部分和负载不均匀;
2.阻塞请求:redis为单线程,单value较大读写需要较长的处理时间,会阻塞后续的请求处理;
3.阻塞网络:单value较大时会占用服务器网卡较多带宽,可能会影响该服务器上的其他Redis实例或者应用。
大key的风险:
1.读写大key会导致超时严重,甚至阻塞服务。
2.如果删除大key,DEL命令可能阻塞Redis进程数十秒,使得其他请求阻塞,对应用程序和Redis集群可用性造成严重的影响。
redis使用会出现大key的场景:
1.单个简单key的存储的value过大;
2.hash、set、zset、list中存储过多的元素。
解决问题:
1.单个简单key的存储的value过大的解决方案:
将大key拆分成对个key-value,使用multiGet方法获得值,这样的拆分主要是为了减少单台操作的压力,而是将压力平摊到集群各个实例中,降低单台机器的IO操作。
2.hash、set、zset、list中存储过多的元素的解决方案:
1).类似于第一种场景,使用第一种方案拆分;
2).以hash为例,将原先的hget、hset方法改成(加入固定一个hash桶的数量为10000),先计算field的hash值模取10000,确定该field在哪一个key上。
将大key进行分割,为了均匀分割,可以对field进行hash并通过质数N取余,将余数加到key上面,我们取质数N为997。
那么新的key则可以设置为:
newKey = order_20200102_String.valueOf( Math.abs(order_id.hashcode() % 997) )
field = order_id
value = 10
hset (newKey, field, value) ;
hget(newKey, field)
如何保证缓存与数据库的一致性
删除缓存有两种方式:
- 先删除缓存,再更新数据库。解决方案是使用延迟双删。
- 先更新数据库,再删除缓存。解决方案是消息队列或者其他 binlog 同步,引入消息队列会带来更多的问题,并不推荐直接使用。
针对缓存一致性要求不是很高的场景,那么只通过设置超时时间就可以了。
其实,如果不是很高的并发,无论你选择先删缓存还是后删缓存的方式,都几乎很少能产生这种问题,但是在高并发下,你应该知道怎么解决问题。
智能推荐
opencv学习笔记二(加载、修改、保存图像imread、cvtColor、imwrite)_cvtcolor(currentframe, currentframe, cv_bgr2gray);-程序员宅基地
文章浏览阅读986次。修改图像时报错:0x00007FFB930E7788 处(位于 Project1.exe 中)有未经处理的异常: Microsoft C++ 异常: cv::Exception,位于内存位置 0x000000E69A8FE160 处。但是最终也可以运行源代码:#include<opencv2/opencv.hpp>#include<iostream>#i..._cvtcolor(currentframe, currentframe, cv_bgr2gray); 0x00007ff9e863cf19 处(位
罗技K580键盘快捷键(ipad)_罗技k580键盘按键功能图解-程序员宅基地
文章浏览阅读1.5w次,点赞2次,收藏2次。Carl + 空格:切换输入法caps lock:中英文切换shift + 字母:大写字母F1:回主页F3:返回F2 + 左右键(alt键 + tab):程序间切换alt + z:撤销当我们忘记快捷键时,可在任意程序中常按alt键,会显示属于该程序的快捷键。注意 ->| 键为Tab键..._罗技k580键盘按键功能图解
XML和JSON的格式和解析_xml json报文格式样例-程序员宅基地
文章浏览阅读806次。1.XML这是一个xml的格式的示例:<?xml version="1.0" encoding="UTF-8"?><books> <book id="1001"> <name>book1</name> <info>这是第1本书的简介!</info> </book> <book id="1002"> <name>b_xml json报文格式样例
android webview在弹出软键盘时,布局没有上移的解决办法_webview拉起软键盘屏幕未上移-程序员宅基地
文章浏览阅读5k次。1、新建类AndroidBug5497Workaround:import android.app.Activity;import android.graphics.Rect;import android.os.Build.VERSION;import android.os.Build.VERSION_CODES;import android.view.View;import andro..._webview拉起软键盘屏幕未上移
虚幻引擎编辑器开发基础(二)_虚幻 编辑器开发-程序员宅基地
文章浏览阅读1.6k次,点赞6次,收藏9次。虚幻引擎编辑器开发基础(二)文章目录虚幻引擎编辑器开发基础(二)一、前言二、编辑器窗口扩展2.1 菜单栏和工具栏扩展2.1.1 FExtender2.1.2 UToolMenu2.1.3 菜单栏扩展拓展新菜单栏拓展已有菜单栏2.1.4 工具栏扩展2.1.5 小结2.2 属性细节面板扩展2.2.1 细节面板(DetailsView)的创建2.2.2 细节面板的扩展定制创建任意UI隐藏成员变量UI自定义成员变量UI2.3 视窗ViewPort扩展三、自定义资源四、自定义编辑器模式五、Commandlet参考文_虚幻 编辑器开发
【图文】linux环境安装jdk1.8并配置环境变量_linux安装jdk1.8配置环境变量-程序员宅基地
文章浏览阅读713次。写在前面: 安装环境准备:操作系统: CentOS7.5 64位JDK版本: 1.8工具:Xshell 7+Xftp 71. oracle官网下载jdk(以jdk-8u281-linux-x64.tar.gz为例)下载地址:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html2:上传至linux环境本文使用的是Xftp 7,如果没有安装Xftp 7,可以使用rz命令上传。(安装rz命令:yum_linux安装jdk1.8配置环境变量
随便推点
剪刀石头布_c++中,遇到3,5,7,报剪刀石头布-程序员宅基地
文章浏览阅读332次。现在一共有N个人(分别记为1, 2, …, N)在玩剪刀石头布,如果知道他们每个人都出了什么,你能找出来谁是winner吗?当且仅当一个人可以赢其他所有人时,才称这个人是winner。我们将剪刀记作2,石头记作0,布记作5,那么胜负关系就应当是2能赢5,5能赢0,0能赢2。Input输入数据的第一行包含一个整数T ( 1 ,表示接下来一共有T组测试数据。每组测试数据的第_c++中,遇到3,5,7,报剪刀石头布
利用vscode调试nodejs代码实践总结-程序员宅基地
文章浏览阅读946次。2018.5.12更新最近在用vscode 1.23版本的时候发现outDir不可以使用了,建议这么改吧,直接program采用编译后的文件,然后打开sourceMaps,同时在babel编译的时候自己搞--watch及时生成.map文件便于vscode索引;如果你要编译其他语言,其实可以在package.json当中添加scripts..._vscode调试nodejs查看堆栈
影像增强器结构及原理_影像增强器的结构-程序员宅基地
文章浏览阅读7.6k次。影像增强器由输入面、光电阴极、集束电极、阳极及输出面在真空状态下构成。转换X射线后光电子通过高压加速,通过由集束电极、阳极构成的电子透镜集束,在输出面上成像。..._影像增强器的结构
RT-Thread:W25Q128虚拟U盘并搭载文件系统_rtthread w25q128 usb同时挂载-程序员宅基地
文章浏览阅读2k次。文章目录前言一、配置工程二、W25Q128搭载文件系统总结前言使用片外Flash W25Q128虚拟成U盘。一、配置工程1、打开W25Q1282、打开USB Drever3、开启大容量设备,并设置容量设备名称为W25Q1284、编译、下载和运行,第一次插入电脑后提示需要格式化,我们选择快速格式化即可。二、W25Q128搭载文件系统1、参考我之前的博文,注意工程使用刚刚配置好虚拟U盘的工程。2、编译、下载和运行,发现当前程序只能是要么虚拟成U盘,要么让W25Q128搭载文件系统,_rtthread w25q128 usb同时挂载
Koa----koa-static 中间件的使用_koa-body koa-static-程序员宅基地
文章浏览阅读2.3k次。1.安装npm install koa-static --save2.引入let static = require('koa-static');3.配置// 引入配置静态托管app.use(static(静态资源所放在的目录)可配置多个)// app.use(static(__dirname,'static'));//方式一// console.log(__d..._koa-body koa-static
redis使用时一段时间后会报出RedisConnectionFailureException: java.net.SocketException: Broken pipe;异常_org.springframework.data.redis.redisconnectionfail-程序员宅基地
文章浏览阅读1.6k次。异常信息org.springframework.data.redis.RedisConnectionFailureException: java.net.SocketException: Broken pipe; nested exception is redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketException: Broken pipe at org.springframework.da_org.springframework.data.redis.redisconnectionfailureexception: java.net.soc