后缀数组 + Hash + 二分 or Hash + 二分 + 双指针 求 LCP ---- 2017icpc 青岛 J Suffix (假题!!)_j.suffix 二分-程序员宅基地
题目大意:
就是给你n个串每个串取一个后缀,要求把串拼起来要求字典序最小!!
s u m _ l e n g t h _ o f _ n ≤ 5 e 5 sum\_length\_of\_n\leq 5e5 sum_length_of_n≤5e5
MY Slove :
-
首先我们知道对于最后一个串肯定是取最小后缀的
-
那么我们可以把最后一个串的结果接到倒数第二个串上面在求一次最小后缀就可以得倒数第二个串的结果,依次以此类推就好了。
-
但是这样我们算算复杂度:假如我们每次都把答案拼到下一个串上面求个后缀数组那么我们假设最坏就是 a + z z z z z . . . . . . a+zzzzz...... a+zzzzz......取均摊的复杂度就是 n \sqrt n n那么就是每个串长度是 n \sqrt n n,有 n \sqrt n n个串,答案最坏的情况是全部取,那么你每次都拼接的话,最后一个串要动 n \sqrt n n次,倒数第二个要动 n − 1 \sqrt n-1 n−1次…那么最坏就是 O ( n ( 1 + n ) / 2 + n ( ∑ i = 1 n i ∗ l o g ( i ∗ n ) ) ) O(\sqrt n(1+\sqrt n)/2+ \sqrt n(\sum_{i=1}^{\sqrt n}i*log(i*\sqrt n))) O(n(1+n)/2+n(∑i=1ni∗log(i∗n))) 铁定T飞了(但是实践证明 O ( n 2 ) O(n^2) O(n2)都可以过的假题)
-
我们考虑优化:
-
我们想想后面那一大坨的问题就是:后缀数组求解拼接后字符串的时间复杂度是很大的 n ( ∑ i = 1 n i ∗ l o g ( i ∗ n ) ) \sqrt n(\sum_{i=1}^{\sqrt n}i*log(i*\sqrt n)) n(∑i=1ni∗log(i∗n)) 那么我们可不可以考虑只对原来的字符求后缀数组,去虚假拼接求呢?
-
我们看看后缀排序后的后缀长什么样子:
eg:aba
a
aba
b -
通过观察我们知道要拼接的答案肯定是以最小后缀为前缀的后缀的其中一个这个贪心看肯定是这样的
我们看看这个数据就知道了
3
ababac
b
drl
ans:ababacbdrl
那么我们可以顺着这个串的所有后缀比下去,但是这个串所有后缀字符个数是 O ( n 2 ) O(n^2) O(n2)的?肯定不是这样比呀!!
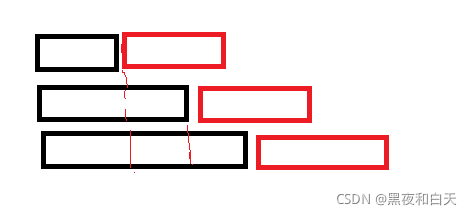
因为我们知道前面是一样的,实际上我们每次只比较后个串多出来的那部分,那部分的长度是 O ( n ) O(n) O(n)
- 但是如果前面都一样怎么办?我们就要看红色重叠的部分了,但是如果暴力比较红色部分复杂度还是将不下来!!因为最坏就是红色的长度了那么有 n n n个后缀就是 O ( n 2 ) O(n^2) O(n2)
- 因为后面是答案串我们可以对答案串进行hash,然后二分那个第一个hash值第一个hash值不一样的位置进行判断字典序!
- 我们在动态维护答案串的hash,不能正序hash,因为字符是头插入的,那么我们逆着hash
AC code
细节巨多,局难写,写了一晚上
#include <bits/stdc++.h>
#define mid ((l + r) >> 1)
#define Lson rt << 1, l , mid
#define Rson rt << 1|1, mid + 1, r
#define ms(a,al) memset(a,al,sizeof(a))
#define log2(a) log(a)/log(2)
#define _for(i,a,b) for( int i = (a); i < (b); ++i)
#define _rep(i,a,b) for( int i = (a); i <= (b); ++i)
#define for_(i,a,b) for( int i = (a); i >= (b); -- i)
#define rep_(i,a,b) for( int i = (a); i > (b); -- i)
#define lowbit(x) ((-x) & x)
#define IOS std::ios::sync_with_stdio(0); cin.tie(0); cout.tie(0)
#define INF 0x3f3f3f3f
#define LLF 0x3f3f3f3f3f3f3f3f
#define hash Hash
#define next Next
#define pb push_back
#define f first
#define s second
using namespace std;
const int N = 1e6 + 10, mod = 1e9 + 9;
const int maxn = 5e5+10;
// const long double eps = 1e-5;
const int base = 233;
typedef long long ll;
typedef unsigned long long ull;
typedef pair<int,int> PII;
typedef pair<ll,ll> PLL;
typedef pair<double,double> PDD;
template<typename T> void read(T &x) {
x = 0;char ch = getchar();ll f = 1;
while(!isdigit(ch)){
if(ch == '-')f*=-1;ch=getchar();}
while(isdigit(ch)){
x = x*10+ch-48;ch=getchar();}x*=f;
}
template<typename T, typename... Args> void read(T &first, Args& ... args) {
read(first);
read(args...);
}
//......................这里是后缀数组
// sa[l]排序是lth的后缀的开始位置
//ra[l]是起点是l的后缀排名多少
//lcp(suf(i),suf(j)) = min(H(ra[i] + 1),....H(ra[j]));
//区间最小值倍增求
// H(i)是rk[i]和rk[i-1]的lcp
//这个板子下标是从0开始,rank从1开始
//传进来的是int数组但是不能有0
struct SA {
int sa[maxn], ra[maxn], height[maxn];
int t1[maxn], t2[maxn], c[maxn];
int shift[maxn];
inline void init(const string &s) {
for(int i = 0; i < s.size(); ++ i) shift[i] = (int)(s[i]-'a'+1);
build(shift,s.size(),30);
}
void build(int *str, int n, int m) {
//字符数组,长度,字符种类
str[n] = 0;
n++;
int i, j, p, *x = t1, *y = t2;
for (i = 0; i < m; i++) c[i] = 0;//排序的桶
for (i = 0; i < n; i++) c[x[i] = str[i]]++;
for (i = 1; i < m; i++) c[i] += c[i - 1];
for (i = n - 1; i >= 0; i--) sa[--c[x[i]]] = i;
for (j = 1; j <= n; j <<= 1) {
//所有长度为1,2,4,8....的子串的排序
//长度够长的话就是所有的后缀排序
p = 0;
for (i = n - j; i < n; i++) y[p++] = i;
for (i = 0; i < n; i++) if (sa[i] >= j) y[p++] = sa[i] - j;
for (i = 0; i < m; i++) c[i] = 0;
for (i = 0; i < n; i++) c[x[y[i]]]++;
for (i = 1; i < m; i++) c[i] += c[i - 1];
for (i = n - 1; i >= 0; i--) sa[--c[x[y[i]]]] = y[i];
swap(x, y);
p = 1;
x[sa[0]] = 0;
for (i = 1; i < n; i++)
x[sa[i]] = (y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j]) ? p - 1 : p++;
if (p >= n) break;
m = p;
}
n--;
for (int i = 0; i <= n; i++) ra[sa[i]] = i;
for (int i = 0, j = 0, k = 0; i <= n; i++) {
if (k) k--;
j = sa[ra[i] - 1];
while (str[i + k] == str[j + k]) k++;
height[ra[i]] = k;
}
st_init(height, n);
}
int lg[maxn], table[23][maxn];
void st_init(int *arr, int n) {
if (!lg[0]) {
lg[0] = -1;
for (int i = 1; i < maxn; i++)
lg[i] = lg[i / 2] + 1;
}
for (int i = 1; i <= n; ++i)
table[0][i] = arr[i];
for (int i = 1; i <= lg[n]; ++i)
for (int j = 1; j <= n; ++j)
if (j + (1 << i) - 1 <= n)
table[i][j] = min(table[i - 1][j], table[i - 1][j + (1 << (i - 1))]);
//从j开始长度是2^i次方得st表
}
int lcp(int l, int r) {
l = ra[l], r = ra[r];
if (l > r) swap(l, r);
++l;
int t = lg[r - l + 1];//区间长度
return min(table[t][l], table[t][r - (1 << t) + 1]);
}
} sa;
//............................... 这里是Hash
string s[maxn], ans;
ull pw[maxn];
vector<ull> Hash;
inline void insert(char a) {
ull last = Hash.empty() ? 0ull : Hash.back();
last = last * base + a - 'a' + 1;
Hash.push_back(last);
}
inline ull gethash(int l,int r) {
if(r < l) return 0;
return (ull)Hash[r]-(l - 1 < 0 ? 0ull : Hash[l-1])*pw[r-l+1];
}
//........................
inline void update(int i, int anspos) {
// 更新答案
for(int m = s[i].size()-ans.size()-1; m >= anspos; -- m) insert(s[i][m]), ans += s[i][m];
}
int main() {
IOS;
pw[0] = 1;
for(int i = 1; i < maxn; ++ i) pw[i] = pw[i-1] * base;
int _;
cin >> _;
while (_--) {
Hash.clear();
int n;
cin >> n;
for(int i = 1; i <= n; ++ i) cin >> s[i];
sa.init(s[n]);
ans = s[n].substr(sa.sa[1]); // 先找到最后一个串的最小后缀
for(int i = ans.size()-1; i >= 0; -- i) insert(ans[i]); // 逆着Hash
reverse(ans.begin(),ans.end()); // 将答案串反过来
for(int i = n - 1; i >= 1; -- i) {
// 枚举第i个串
if(s[i].size()==1) {
insert(s[i][0]); ans += s[i]; continue;}// 特判长度为1的串
// 对这个串建立后缀数组
sa.init(s[i]);
// 把答案串拼到新串后面
for(int j = (int)ans.size()-1; j >= 0; -- j) s[i] += ans[j];
int anspos = sa.sa[1]; //anspos = 答案后缀的开头位置
for(int k = 2; k <= s[i].size()-ans.size(); ++ k) {
// 枚举这个串的每个后缀
if(sa.lcp(sa.sa[k],sa.sa[k-1]) != s[i].size()-ans.size()-anspos) {
// 如果不是以前面后缀为前缀那就结束了后面答案不会更优
update(i,anspos);
break;
}
int eps = s[i].size() - ans.size() - sa.sa[k-1];
int is = 0;
// 只比较突出的部分
int j;
for(j = 0; j+anspos+eps < s[i].size() && j+sa.sa[k]+eps<s[i].size()-ans.size(); ++ j)
if(s[i][j+anspos+eps] < s[i][j+sa.sa[k]+eps]) {
// 如果在黑
is = 1;
update(i,anspos);
break;
} else if(s[i][j+anspos+eps] > s[i][j+sa.sa[k]+eps]) {
anspos = sa.sa[k];
if(k == s[i].size()-ans.size()) update(i,anspos);//如果到了最后一个串了可以直接更新了
is = 2;
break;
} else if(j+anspos+eps == s[i].size()-1) {
is = 1;
update(i,anspos);
break;
}
if(is == 1) break; // is == 1 表示可以确定答案了提前退出就好了
if(is == 2) continue;
//...................................二分红色部分
int l = 0, r = s[i].size()-(j+anspos+eps)-1;
//注意我是把答案串拼到了新串后面
int tmp = j+anspos+eps-(s[i].size()-ans.size());
while(l < r) {
//注意Hash是逆序存的,要从末尾开始看
if(gethash(Hash.size()-1-tmp-mid,Hash.size()-1-tmp)==gethash(Hash.size()-1-mid,Hash.size()-1)) l = mid+1;
else r = mid;
}
if(s[i][j+anspos+eps+l]>s[i][j+sa.sa[k]+eps+l]) anspos = sa.sa[k];
if(k == s[i].size()-ans.size()) update(i,anspos);//如果到了最后一个串了可以直接更新了
}
}
for(int i = ans.size()-1;~i;i--) cout << ans[i];
cout << endl;
}
return 0;
}
Solution 2
贪心从后往前看,最后一个串一定选择字典序最小的后缀,然后把这个后缀拼接到第n - 1个串,重复这个步骤就行了。
具体实现:
从后往前遍历,每次找当前串的最小后缀,这个可以对于当前下标和当前最小后缀下标二分+hash找到lcp,看lcp后一个位置的大小,然后更新最小后缀的下标(这里是关键)。然后把最小后缀拼接到前一个串即可。
理论时间复杂度跟后缀数组差不多,但后缀数组常数和编码量更大。
AC code
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
const ull base=131;
#define mod
#define maxn 605000
ull p[maxn];ull h[maxn];
ull get_hash(ull l,ull mid)
{
return h[l]-h[l-mid]*p[mid];
}
string str[maxn];char ans[maxn];
int len[maxn];
ull check(ull x,ull y)
{
ull l=1,r=y;
while(l<=r)
{
ull mid=(l+r)/2;
//cout<<"l="<<l<<" r="<<r<<" mid="<<mid<<'\n';
if(get_hash(x,mid)==get_hash(y,mid))
{
l=mid+1;
}
else r=mid-1;
}
if(l==y+1) return 0;
return ans[x-r]<ans[y-r];
}
int main()
{
ull T;
p[0]=1;
for(ull i=1;i<=maxn-100;i++)
{
p[i]=p[i-1]*base;
}
cin>>T;
while(T--)
{
ull n;
cin>>n;
for(ull i=1;i<=n;i++)
{
cin>>str[i];
len[i]=str[i].size();
}
ull id=0;
for(ull i=n;i>=1;i--)
{
//cout<<"i="<<i<<" id="<<id<<'\n';
ans[++id]=str[i][len[i]-1];
h[id]=h[id-1]*base+str[i][len[i]-1];
ull to=1;
ull t=id;
for(int j=(int)(len[i])-2;j>=0;j--)
{
//cout<<"i="<<i<<" j="<<j<<'\n';
ans[id+to]=str[i][j];
h[id+to]=h[id+to-1]*base+str[i][j];
if(check(id+to,t))
{
t=id+to;
}
to++;
}
id=t;
}
for(ull i=id;i>=1;i--) cout<<ans[i];
cout<<'\n';
}
}
/*
3
3
bbb
aaa
ccc
*/
智能推荐
使用UmcFramework和unimrcpclient.xml连接多个SIP设置的配置指南及C代码示例
在多媒体通信领域,MRCP(Media Resource Control Protocol)协议被广泛用于控制语音识别和合成等媒体资源。UniMRCP是一个开源的MRCP实现,提供了客户端和服务端的库。UmcFramework是一个基于UniMRCP客户端库的示例应用程序框架,它帮助开发者快速集成和测试MRCP客户端功能。本文将详细介绍如何使用UmcFramework和unimrcpclient.xml配置文件连接到多个SIP设置,以及如何用C代码进行示例说明。
java.net.ProtocolException: Server redirected too many times (20)-程序员宅基地
文章浏览阅读3k次。报错:java.net.ProtocolException: Server redirected too many times (20)1.没有检查到cookie,一直循环重定向。解决:CookieHandler.setDefault(new CookieManager(null, CookiePolicy.ACCEPT_ALL));URL url = new URL(url); ..._java.net.protocolexception: server redirected too many times (20)
springboot启动报错 Failed to scan *****/derbyLocale_ja_JP.jar from classloader hierarchy_failed to scan from classloader hierarchy-程序员宅基地
文章浏览阅读4.1k次。问题这是部分报错信息2019-07-11 14:03:34.283 WARN [restartedMain][DirectJDKLog.java:175] - Failed to scan [file:/D:/repo/org/apache/derby/derby/10.14.2.0/derbyLocale_ja_JP.jar] from classloader hierarchyjava...._failed to scan from classloader hierarchy
MATLAB-ones函数_matlab中ones函数-程序员宅基地
文章浏览阅读2.8k次,点赞3次,收藏7次。在MATLAB中,ones函数用于创建一个指定大小的由1组成的矩阵或数组。_matlab中ones函数
解决PS等软件出现应用程序无法正常启动(0xc000007b)_photoshop应用程序无法正常启动0xc000007b。请单击“确认”关闭应用程序。-程序员宅基地
文章浏览阅读3.9w次,点赞2次,收藏9次。 在使用电脑办公过程中,安装应用程序时难免遇到无法安装或者无法正常启动的问题,这对我们使用电脑带来了诸多不便。那遇到应用程序无法正常启动的问题要如何解决呢?相信大家肯定都是十分疑问的,每次都是只能忍痛重新安装软件。今天,小编就和大家探讨下应用程序无法正常启动的解决方法,帮助大家排忧解难。0xc000007b电脑图解1 第一种方案:SFC检查系统完整性来尝试修复丢失文件 1、打开电脑搜索输入cmd.exe,选择以管理员身份运行,跳出提示框时选择继续。0xc000007b电脑图解2_photoshop应用程序无法正常启动0xc000007b。请单击“确认”关闭应用程序。
oracle介质恢复和实例恢复的异同-程序员宅基地
文章浏览阅读396次。1、概念 REDO LOG是Oracle为确保已经提交的事务不会丢失而建立的一个机制。实际上REDO LOG的存在是为两种场景准备的:实例恢复(INSTANCE RECOVERY);介质恢复(MEDIA RECOVERY)。 实例恢复的目的是在数据库发生故障时,确保BUFFER CACHE中的数据不会丢失,不会造成数据库的..._oracle 实例恢复和介质恢复
随便推点
轻松搭建CAS 5.x系列(5)-增加密码找回和密码修改功能-程序员宅基地
文章浏览阅读418次。概述说明CAS内置了密码找回和密码修改的功能; 密码找回功能是,系统会吧密码重置的连接通过邮件或短信方式发送给用户,用户点击链接后就可以重置密码,cas还支持预留密码重置的问题,只有回答对了,才可以重置密码;系统可配置密码重置后,是否自动登录; 密码修改功能是,用户登录后输入新密码即可完成密码修改。安装步骤`1. 首先,搭建好cas sso server您需要按..._修改cas默认用户密码
springcloud(七) feign + Hystrix 整合 、-程序员宅基地
文章浏览阅读141次。之前几章演示的熔断,降级 都是 RestTemplate + Ribbon 和RestTemplate + Hystrix ,但是在实际开发并不是这样,实际开发中都是 Feign 远程接口调用。Feign + Hystrix 演示: eruka(略)order 服务工程: pom.xml<?xml version="1.0" encoding="U..._this is order 服务工程
YOLOv7如何提高目标检测的速度和精度,基于优化算法提高目标检测速度-程序员宅基地
文章浏览阅读3.4k次,点赞35次,收藏43次。学习率是影响目标检测精度和速度的重要因素之一。合适的学习率调度策略可以加速模型的收敛和提高模型的精度。在YOLOv7算法中,可以使用基于余弦函数的学习率调度策略(Cosine Annealing Learning Rate Schedule)来调整学习率。
linux中进程退出函数:exit()和_exit()的区别_linux结束进程可以用哪些函数,它们之间有何区别?-程序员宅基地
文章浏览阅读4k次,点赞4次,收藏9次。 linux中进程退出函数:exit()和_exit()的区别(1)_exit()执行后立即返回给内核,而exit()要先执行一些清除操作,然后将控制权交给内核。(2)调用_exit函数时,其会关闭进程所有的文件描述符,清理内存以及其他一些内核清理函数,但不会刷新流(stdin, stdout, stderr ...). exit函数是在_exit..._linux结束进程可以用哪些函数,它们之间有何区别?
sqlserver55555_sqlserver把小数点后面多余的0去掉-程序员宅基地
文章浏览阅读134次。select 5000/10000.0 --想变成0.5select 5500/10000.0 --想变成0.55select 5550/10000.0 --想变成0.555select 5555/10000.0 --想变成0.5555其结果分别为:0.5000000 0.5500000 0.5550000 0.5555000一、如果想去掉数字5后面多余的0 ,需要转化一下:selec..._sql server 去小数 0
Angular6 和 RXJS6 的一些改动_angular6,requestoptions改成了什么-程序员宅基地
文章浏览阅读3.1k次。例一:import { Injectable } from '@angular/core';import { Observable } from 'rxjs';import { User } from "./model/User";import { map } from 'rxjs/operators';import { Http, Response, Headers, RequestOp..._angular6,requestoptions改成了什么